


Map
Map 是一种键-值对(key-value)集合,也称为二元偶对象。
public interface Map<K,V>
//所有已知实现类: AbstractMap , Attributes , AuthProvider , ConcurrentHashMap , ConcurrentSkipListMap , EnumMap ,
HashMap , Hashtable , Headers , IdentityHashMap , LinkedHashMap , PrinterStateReasons , Properties ,
Provider , RenderingHints , ScriptObjectMirror , SimpleBindings , TabularDataSupport , TreeMap , UIDefaults , WeakHashMap
键对象(key)不允许重复,
而值对象(value)可以重复,也可以还是 Map 类型。
嵌套类
static interface |
Map.Entry<K,V> |
映射条目(键值对)。
|
|---|
实际上来讲,对于每一个存放到 Map 集合中的 key 和 value 都是将其变为了 Map.Entry 并且将 Map.Entry 保存在了 Map 集合之中
即Map 集合中每一个元素都是 Map.Entry 的实例,只有通过 Map.Entry 才能进行 key 和 value 的分离操作。
Map 接口主要有两个实现类:
HashMap :按哈希算法来存取键对象
TreeMap 类:可以对键对象进行排序。
Hashtable:是一个最早的 keyvalue 的操作类,本身是在 JDK 1.0 的时候推出的。其基本操作与 HashMap 是类似的。
Map常用方法
| 变量和类型 | 方法 | 描述 |
|---|---|---|
void |
clear() |
从此映射中删除所有映射(可选操作)。
|
boolean |
containsKey(Object key) |
如果此映射包含指定键的映射,则返回
true 。 |
boolean |
containsValue(Object value) |
如果此映射将一个或多个键映射到指定值,则返回
true 。 |
static <K,V> |
copyOf(Map<? extends K,? extends V> map) |
返回包含给定Map的条目的 unmodifiable Map 。
|
static <K,V> |
entry(K k, V v) |
返回包含给定键和值的不可修改的
Map.Entry 。 |
Set<Map.Entry<K,V>> |
entrySet() |
返回此映射中包含的映射的
Set视图。 |
boolean |
equals(Object o) |
将指定对象与此映射进行比较以获得相等性。
|
default void |
forEach(BiConsumer<? super K,? super V> action) |
对此映射中的每个条目执行给定操作,直到处理完所有条目或操作引发异常。
|
V |
get(Object key) |
返回指定键映射到的值,如果此映射不包含键的映射,则返回
null 。 |
default V |
getOrDefault(Object key, V defaultValue) |
返回指定键映射到的值,如果此映射不包含键的映射,则返回
defaultValue 。 |
int |
hashCode() |
返回此映射的哈希码值。
|
boolean |
isEmpty() |
如果此映射不包含键 - 值映射,则返回
true 。 |
Set<K> |
keySet() |
返回此映射中包含的键的
Set视图。 |
static <K,V> |
of() |
返回包含零映射的不可修改映射。(还可以有多个映射)
|
V |
put(K key, V value) |
将指定的值与此映射中的指定键相关联(可选操作)。
|
void |
putAll(Map<? extends K,? extends V> m) |
将指定映射中的所有映射复制到此映射(可选操作)。
|
V |
remove(Object key) |
如果存在,则从该映射中移除键的映射(可选操作)。
|
default boolean |
remove(Object key, Object value) |
仅当指定键当前映射到指定值时才删除该条目的条目。
|
default V |
replace(K key, V value) |
仅当指定键当前映射到某个值时,才替换该条目的条目。
|
default boolean |
replace(K key, V oldValue, V newValue) |
仅当前映射到指定值时,才替换指定键的条目。
|
default void |
replaceAll(BiFunction<? super K,? super V,? extends V> function) |
将每个条目的值替换为在该条目上调用给定函数的结果,直到所有条目都已处理或函数抛出异常。
|
int |
size() |
返回此映射中键 - 值映射的数量。
|
Collection<V> |
values() |
返回此映射中包含的值的
Collection视图。 |
Map遍历
Map集合不能直接使用迭代器或者foreach进行遍历,需要转成Set。
// 通过键的方式 Map<String, String> map = new HashMap<String, String>(); Set<String> set = map.keySet(); // 得到全部的key Iterator<String> iter = set.iterator(); while (iter.hasNext()) { String it = iter.next(); // 得到key System.out.println(it + " --> " + map.get(it)); }
for (String str : set) {
System.out.println(str);
}
// 通过值的方式
Collection<String> value = map.values();
// 得到全部的value
Iterator<String> iter = value .iterator();
while (iter.hasNext()) {
String it= iter.next();
// 得到key
System.out.println(it);
}
// 通过键值对的方式,使用到嵌套类Map.Entry
Set<Map.Entry<String,String>> entrySet = map.entrySet();
Iterator<Map.Entry<String,String>> it =entrySet.iterator();
while(it.hasNext()){
Map.Entry<String,String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);
}
HashMap
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
HashMap<K,V>:存储数据采用哈希表结构,元素的存取顺序不一致。由于要保证键唯一、不重复,需要重写键的hashCode()方法、equals()方法。
哈希表
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一 个链表里。
但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率 较低。
而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
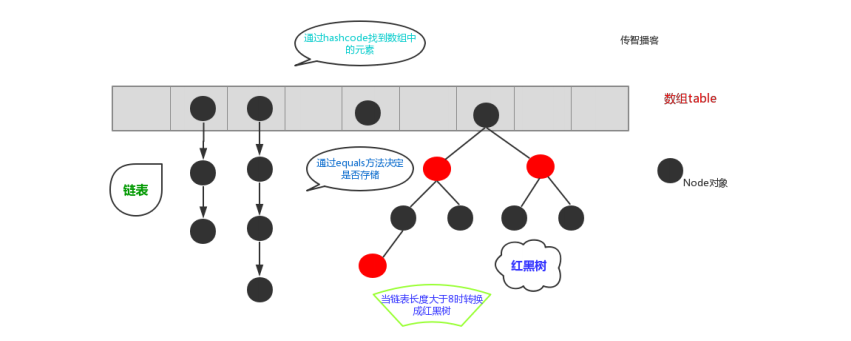
当长度从8减少后,红黑树会转成链表。
哈希表存储过程

HashMap 与 Hashtable 的区别
| 区别点 | HashMap | Hashtable |
| 推出时间 | JDK 1.2 之后推出的,新的操作类 | JDK 1.0 时推出的,旧的操作类 |
| 性能 | 异步处理,性能较高 | 同步处理,性能较低 |
| null | 允许设置为 null键、null值 | 不允许设置,否则将出现空指向异常 |
TreeMap
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, Serializable
TreeMap 是允许 key 进行排序的操作子类,其本身在操作的时候将按照 key 进行排序,另外,key 中的内容可以 为任意的对象,但是要求对象所在的类必须实现 Comparable 接口。
构造器
| 构造器 | 描述 |
|---|---|
TreeMap() |
使用其键的自然顺序构造一个新的空树图。
|
TreeMap(Comparator<? super K> comparator) |
构造一个新的空树图,根据给定的比较器排序。
|
TreeMap(Map<? extends K,? extends V> m) |
构造一个新的树映射,其中包含与给定映射相同的映射,根据其键的 自然顺序排序 。
|
TreeMap(SortedMap<K,? extends V> m) |
构造一个包含相同映射的新树映射,并使用与指定有序映射相同的顺序。
|
常用方法
| 变量和类型 | 方法 | 描述 |
|---|---|---|
Map.Entry<K,V> |
ceilingEntry(K key) |
返回与大于或等于给定键的最小键关联的键 - 值映射,如果没有此键,则
null 。 |
K |
ceilingKey(K key) |
返回大于或等于给定键的
null键,如果没有这样的键,则 null 。 |
void |
clear() |
从此映射中删除所有映射。
|
Object |
clone() |
返回此
TreeMap实例的浅表副本。 |
boolean |
containsKey(Object key) |
如果此映射包含指定键的映射,则返回
true 。 |
boolean |
containsValue(Object value) |
如果此映射将一个或多个键映射到指定值,则返回
true 。 |
Set<Map.Entry<K,V>> |
entrySet() |
返回此映射中包含的映射的
Set视图。 |
V |
get(Object key) |
返回指定键映射到的值,如果此映射不包含键的映射,则返回
null 。 |
Map.Entry<K,V> |
pollFirstEntry() |
删除并返回与此映射中的最小键关联的键 - 值映射,如果映射为空,则
null 。 |
V |
put(K key, V value) |
将指定的值与此映射中的指定键相关联。
|
void |
putAll(Map<? extends K,? extends V> map) |
将指定映射中的所有映射复制到此映射。
|
V |
remove(Object key) |
如果存在,则从此TreeMap中删除此键的映射。
|
int |
size() |
返回此映射中键 - 值映射的数量。
|
Collection<V> |
values() |
返回此映射中包含的值的
Collection视图。 |
分析 equals、hashCode 与内存泄露
equals 的作用:比较两个对象的地址值是否相等
equals()方法在 object 类中定义如下:
public boolean equals(Object obj) { return (this == obj); }
但是我们必需清楚,当 String 、Math、还有 Integer、Double。。。。等这些封装类在使用 equals()方法时,已经覆盖了 object 类的 equals()方法,不再是地址的比较而是内容的比较。
我们还应该注意,Java 语言对 equals()的要求如下,这些要求是必须遵循的:
1. 对称性:如果 x.equals(y)返回是“true”,那么 y.equals(x)也应该返回是“true”。
2. 反射性:x.equals(x)必须返回是“true”。
3. 类推性:如果 x.equals(y)返回是“true”,而且 y.equals(z)返回是“true”,那么 z.equals(x)也应该返回是“true”。
4. 还有一致性:如果 x.equals(y)返回是“true”,只要 x 和 y 内容一直不变,不管你重复 x.equals(y)多少次,返回都是 “true”。
5. 任何情况下,x.equals(null),永远返回是“false”;x.equals(和 x 不同类型的对象)永远返回是“false”。
以上这五点是重写 equals()方法时,必须遵守的准则,如果违反会出现意想不到的结果。
hashcode() 方法,在 object 类中定义如下:
public native int hashCode();
说明是一个本地方法,它的实现是根据本地机器相关的。当然我们可以在自己写的类中覆盖 hashcode()方法,比如 String、 Integer、Double。。。。等等这些类都是覆盖了 hashcode()方法的。
java.lnag.Object 中对 hashCode 的约定:
1. 在一个应用程序执行期间,如果一个对象的 equals 方法做比较所用到的信息没有被修改的话,则对该对象调用 hashCode 方法多次,它必须始终如一地返回同一个整数。
2. 如果两个对象根据 equals(Object o)方法是相等的,则调用这两个对象中任一对象的 hashCode 方法必须产生相同的整 数结果。
3. 如果两个对象根据 equals(Object o)方法是不相等的,则调用这两个对象中任一个对象的 hashCode 方法,不要求产生不同的整数结果。但如果能不同,则可能提高散列表的性能。
在 java 的集合中,判断两个对象是否相等的规则是:
(1)判断两个对象的 hashCode 是否相等 如果不相等,认为两个对象也不相等,完毕 如果相等,转入 2
(这一点只是为了提高存储效率而要求的,其实理论上没有也可以,但如果没有,实际使用时效率会大大降低,所以我们 这里将其做为必需的。后面会重点讲到这个问题。)
(2)判断两个对象用 equals 运算是否相等
如果不相等,认为两个对象也不相等
如果相等,认为两个对象相等(equals()是判断两个对象是否相等的关键)
提示: 当一个对象被存进 HashSet 集合后,就不能修改这个对象中的那些参与计算的哈希值的字段了,否则,对象被修改后的哈 希值与最初存储进 HashSet 集合中时的哈希值就不同了,在这种情况下,即使在 contains 方法使用该对象的当前引用作为 的参数去 HashSet 集合中检索对象,也将返回找不到对象的结果,这也会导致无法从 HashSet 集合中删除当前对象,从而 造成内存泄露。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号