linux系统符号及正则符号学习
参考:https://www.zsythink.net/archives/1845
一、linux系统特殊符号:

引号:
' ' 输出的信息,所见及所得。
'' '' 解析文本中的特定字符,并输出解析后的内容
` ` $() 将引号中的命令先执行,将执行的结果交给外面的命令进行处理,和双引号功能类似,但是可以直接识别通配符信息
补充:(逻辑符号系列)
|| 前边执行成功则不执行后面的动作
&& 前面执行成功则执行后面的动作
二、系统通配符:

三、正则表达式字符:
"正则表达式"又称"规则表达式",使用"正则表达式"可以让我们"表达出"某种规则,就像刚才使用到的"hello",我们使用这个正则表达式,表达出了我们的想法,我们的想法就是搜索出位于行首的hello字符串,在正则表达式中,""就表示行首,所以,"^hello"就是表示位于行首的hello字符串,这就是我们想要表达的"规则",这就是"正则",我们利用这个正则表达式,检索出了"符合规则"的文本。
位置匹配符:
^:表示锚定行首,此字符后面的任意内容必须出现在行首,才能匹配。
$:表示锚定行尾,此字符前面的任意内容必须出现在行尾,才能匹配。
^$:表示匹配空行,这里所描述的空行表示"回车",而"空格"或"tab"等都不能算作此处所描述的空行。
^abc$:表示abc独占一行时,会被匹配到。
\<或者\b :匹配单词边界,表示锚定词首,其后面的字符必须作为单词首部出现。
\>或者\b :匹配单词边界,表示锚定词尾,其前面的字符必须作为单词尾部出现。
\B:匹配非单词边界,与\b正好相反。
连续次数匹配符:
* 表示前面的字符连续出现任意次,包括0次。
. 表示任意单个字符。
.* 表示任意长度的任意字符,与通配符中的*的意思相同。
\? 表示匹配其前面的字符0或1次
\+ 表示匹配其前面的字符至少1次,或者连续多次,连续次数上不封顶。
\{n\} 表示前面的字符连续出现n次,将会被匹配到。
\{x,y\} 表示之前的字符至少连续出现x次,最多连续出现y次,都能被匹配到,换句话说,只要之前的字符连续出现的次数在x与y之间,即可被匹配到。
\{,n\} 表示之前的字符连续出现至多n次,最少0次,都会陪匹配到。
\{n,\} 表示之前的字符连续出现至少n次,才会被匹配到.
常用正则符号:
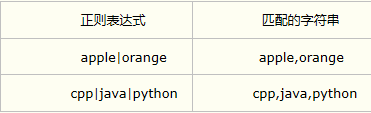
0.择一匹配 (|)
| 从多个模式中选择其一,类似于逻辑或,例如
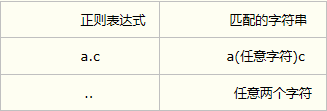
1.任意匹配单个字符 (.)
. 匹配除了换行符\n以外的任意字符,例如:
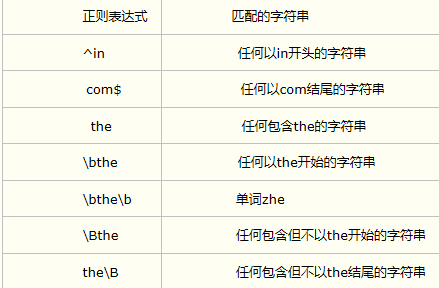
2.从字符串开始或结尾或单词边界匹配(^) ($) (\b) (\B)
^或\A接字符串,表示以该字符串开始(区别:^匹配一行的开始,\A匹配输入的开始)
$或\Z接字符串,表示以该字符串结尾(同上)
\b接字符串,表示以该字符串开始(区别于^和\A:匹配一个单词起始部分,不管该单词前面是否有任何字符。通俗来说:^匹配字符串的开始,\b匹配单词的开始)
\B接字符串,表示以该字符串为子串但不是边界
3.创建字符集,类似于择一匹配 ([])
([])用于匹配某些特定字符,区别于(.)匹配任意字符,匹配方括号中包含的任意字符。
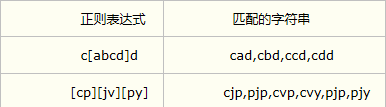
4.限定范围或否定 (-) ([^])
方括号中两个字符以-符号连接表示指定一个范围,在连接的字符之中。
方括号中紧紧连接^符号表示不匹配给定字符集任一字符

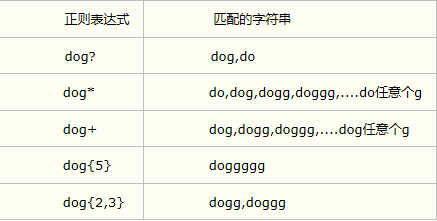
5.零次,一次或多次匹配(*) (+) (?) ;频数匹配 {M} {M,N} {M,}
*将匹配其左边的正则表达式出现零次或多次的情况。
+将匹配其左边的正则表达式出现一次或多次的情况。
?将匹配其左边的正则表达式出现零次或一次的情况。
{M}将匹配其左边的正则表达式出现M次的情况。
{M,N}将匹配其左边的正则表达式出现M到N次的情况。
{M,}将匹配其左边的正则表达式出现M次或更多次的情况。

6.表示字符集的特殊字符 (\w)(\d) (\s)
\w 匹配任何字母数字下划线字符
\d 匹配任何十进制数字
\s 匹配任意空格字符

7.括号符号:()
作用:
1.指定信息进行整体匹配
2.进行后项引用前项使用 (配合sed 替换功能和 \1 使用)
示例:批量创建用户
echo test{0..10} | xargs -n1 | sed -r 's#(.*)#useradd \1#g' | bash
示例:输出<12><34><56>


 浙公网安备 33010602011771号
浙公网安备 33010602011771号