《基于深度学习的高传染性疾病预测系统》数据库设计心得
项目名称:基于深度学习的高传染性疾病预测系统
队名:发量和我作队
队员:殷浩翔 肖欣 刘佳雨 马诗丹 张楠
指导老师:胡军
综述
本项目为基于深度学习的高传染性疾病预测系统,通过使用深度学习模型,在Web应用中与用户进行实时交互,并且通过前端的逻辑使用户制作图模型,与同时发送消息到后端与数据库进行交互,使得用户可以通过设置初始的参数来查看一个疾病传染案例(本质为多结点的图)的预测结果。
设计过程
首先,由于本项目是一个偏算法的项目,首先我们得知道算法需要什么样的数据,来决定数据库怎么存。
算法模块分析:
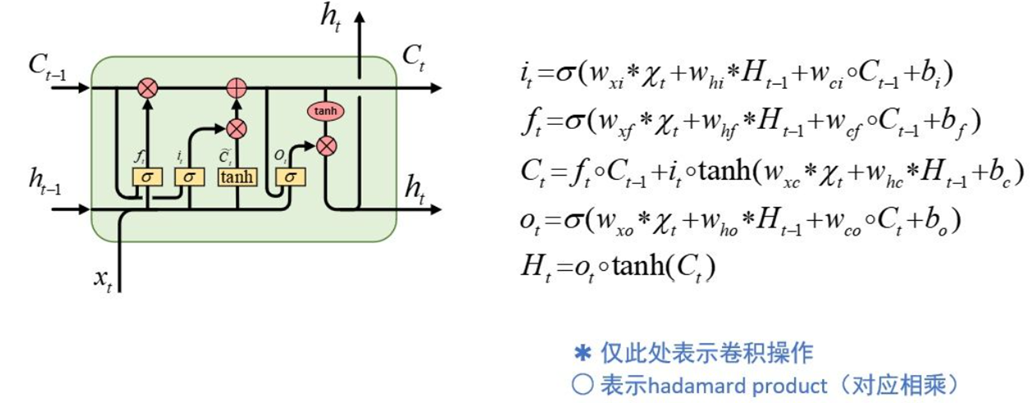
我们采用的算法是ConvLSTM(Convolutional Long-short term memory),基于卷积神经单元的长短记忆神经网络。结构如下:
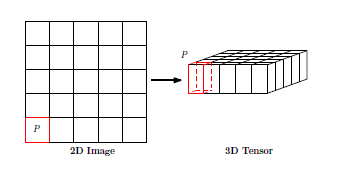
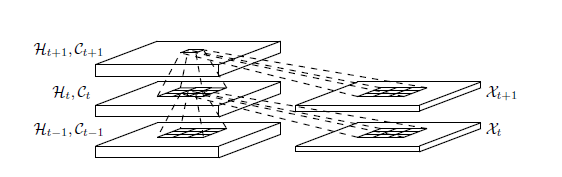
首先对于每一个时间步,我们的项目将城市与城市之间的关系,城市自己的信息作为二维的张量进行展开,也就是城市与城市之间的关系是通过邻接矩阵的n*n矩阵的二维张量,而城市本身的信息通过稀疏的矩阵二维张量表示,这样城市间关系+城市自身属性就是一个3维的张量。这个三维张量会在卷积的过程中被卷积操作转化为四维的但是在数据库存储中只需要存储三维的即可。
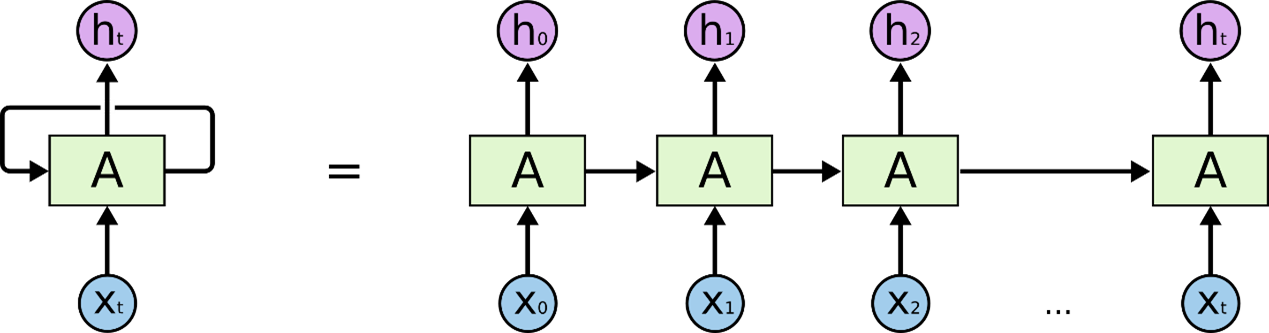
又由于LSTM本身需要序列的数据,所以需要把矩阵的信息都作为每一步的输入信息与LSTM的隐藏层,之前的状态信息进行结合,组合成一个四维的张量。
下面将会对张量在数据库中的存储进行详细说明:
对于每一个时间步:
需要输入卷积层的三维张量需要包含以下的信息
- 城市与城市之间的流通指数
- 每一个城市的人口
- 每一个城市感染人数
对于城市与城市之间的流通指数实质上是一个实对称矩阵如下图所示:
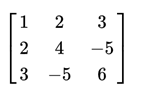
实对称是因为城市间的联系是无向边。
每一个城市的人口将会是一个对角矩阵:
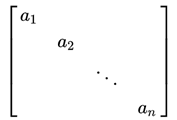
感染人数也将会是一个对角矩阵。
对于整体:
每一个时间步的信息会被整合并且输入LSTM与卷积神经网络进行操作。
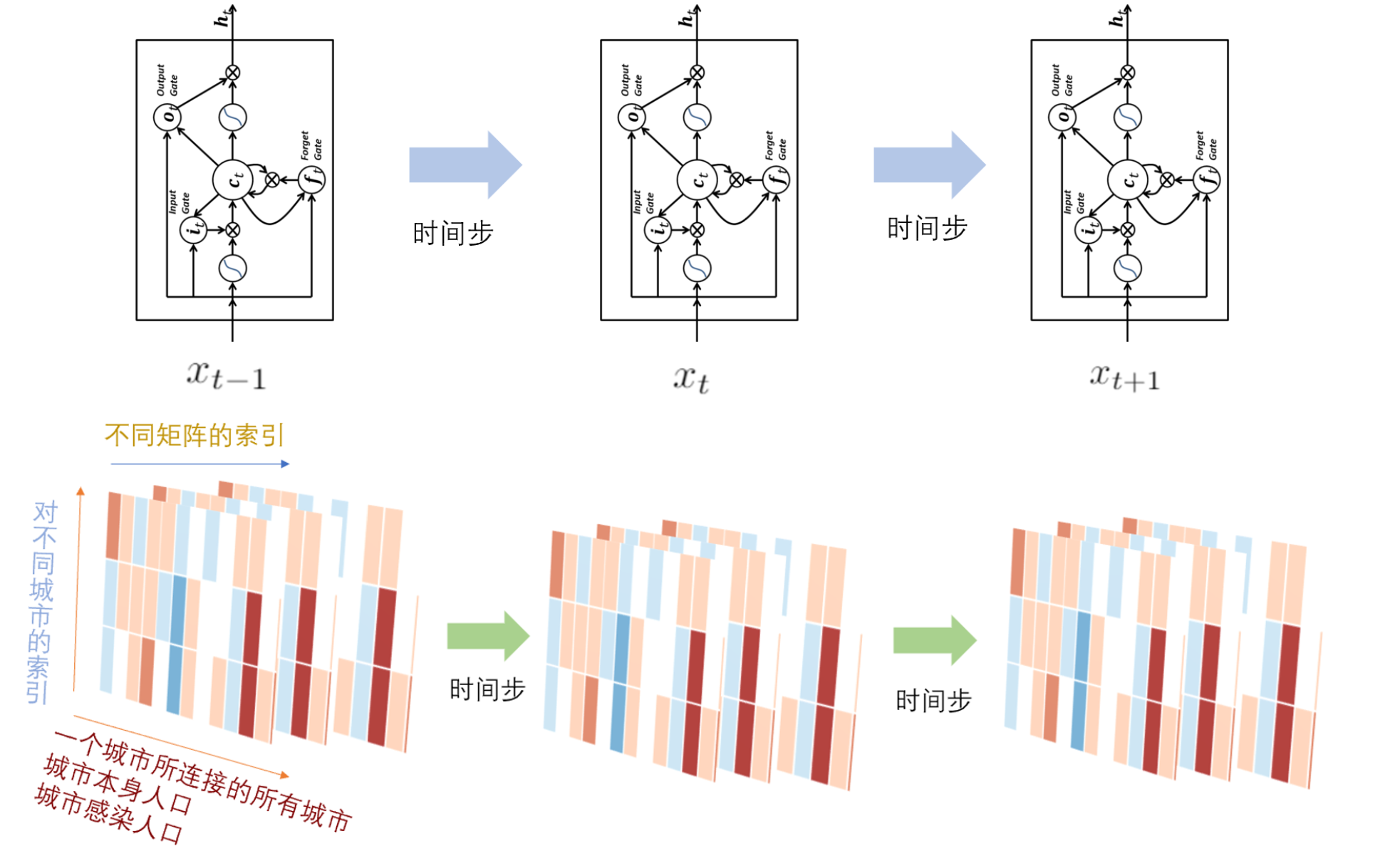
算法部分需要数据库存储的形式介绍完毕,具体数据库实现会在下面阐述。
数据库设计:
数据库设计无疑是从需求映射到实现的第一步,因此数据库设计是相当重要的。通过需求分析,我们已经确定了绝大部分的用例并确定了每个用例中涉及的对象,接下来就是从这些对象中提取出需要的数据,然后思考这些数据如何有效率的存储到数据库中。
这里的有效率涉及到很多性能,比较重要的几个方面分别是:①如何用尽可能小的空间储存,②如何使数据的操作尽可能快,③如何尽量减少不必要的操作。我们从存储方式,索引方式,表组织形式三个方面来优化这三点。
1. 存储方式
在本次需求分析过程中,部分需求的数据存储可能会让人非常困惑,例如矩阵形式的数据,这样的数据格式显然并不能直接存入数据库。这时候就需要灵活改变数据的存储性质。
对于无法直接存储的矩阵,可以有两种存储方法。第一种是通过转换为点的信息存储其行列坐标与值,并且通过一个矩阵id作为标识符记录其所属矩阵。
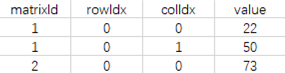
这种处理方式虽然浅显易懂,但是存在的问题是如果矩阵本身的行列数过多,一个矩阵需要大量的数据行来存储,毫无疑问会增大存储开销,并加大数据库在增删改查时的时间消耗,降低效率。因此这种设计被放弃。
另一种处理方式是通过将整个矩阵连同分隔符和换行符在内处理为一个长字符串,每次取出信息的时候只需要对字符串做解析就能获得原矩阵数据。
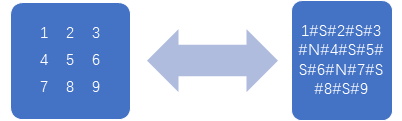
这种方法虽然加长了一个属性值的长度并且需要做额外解析。但是在内存中对字符串做解析的开销比扫描多行数据从数据库返回的时间消耗更小。权衡之后这种方式更加合适于大型矩阵的存储。
类似这样的数据存储的转换还有很多,例如如何存储用户在canvas上绘制的案例。
第一个考虑方案是canvas标签及其中的部分直接作为数据信息存储,这种方式类似前文提及的矩阵转字符串存储。但是这里的权衡结果让我们直接放弃了这种方式,因为这样存储刀数据库的将会是一个非常长的字符串,掺杂大量的冗余信息,相似的存储方式,却反而造成额外存储开销。
最终敲定的方案是,将canvas做坐标轴,通过记录城市坐标和道路映射来实现canvas的存储。虽然表的数量增加了,但作为tradeoff获得了存储开销的降低。因此认为是合理的。
除此之外还有一些对数据存储方式的权衡,我们通过这些表的设计来获得更好的数据库性能。
2.索引方式
数据库索引,是数据库管理系统中一个排序的数据结构,索引的实现通常使用B树及其变种B+树,其形式类似于下图:
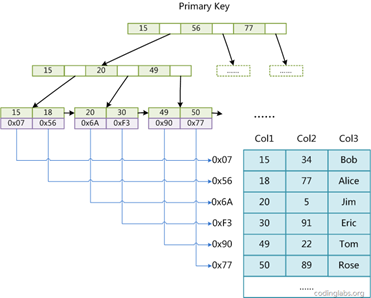
索引可以加快查询、更新、分组、排序、表连接的速度,但是会带来存储空间开销的提高和插入删除数据速度的减慢。对于数据量较少的表与常常插入删除的表而言只需要主键索引即可。对于存储模型数据,canvas数据的表而言,由于时常进行数据插入删除,因此不应该建立额外的索引;而对于用户表而言,由于网站体量并不大,用户数量并不多,因此也不建立额外的索引。
3.表组织形式
最后是关于表组织形式的策略
设计表与表之间的关系时,我们要根据具体功能和实际情况,考虑实体与实体间的关系,建立正确的关系类型。
一对一关系:假设我们有A表和B表,一对一关系就是说A表中的一行最多只能匹配B表中的一行,反之亦然。一对一关系是比较少用的,一般有两种情况:情况一是用于保存临时数据,建一张单独的表便于修改,这样不会影响到之前建好的数据库。情况二是指在一个表中有一个属性存储长度很大的数据,这样在每次进行查询操作时,效率会比较低,将这个属性单独出来,就不会影响其他数据的查询速度。
一对多关系:还是假设有A、B两张表,一对多关系就是说A表中的一行可以匹配B表中的多行,而B表中的一行最多只能匹配A表中的一行。
多对多关系:A表中的一行可以匹配B表中的多行,反之亦然。
设计用户账户信息表,我们考虑到登陆密码加密以及权限管理等因素,分解为了多个表设置一对一关系。然后根据我们主要的的功能需求,案例展示、模拟数据等设计“案例”相关的数据库表,多数为一对多关系。
实现过程
根据之前的需求分析,我们开始建立数据库表。根据我们的用户分类以及功能需求,使用powerdesinger工具创建实体,分析实体与实体之间的联系,确定关系类型:一对一、一对多或者多对多。由概念模型生成物理模型,修改部分字段类型,利用powerdesinger生成sql语句以及数据字典。
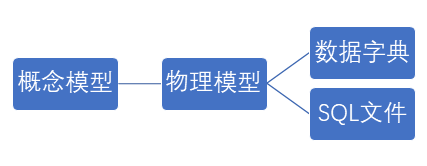
创建概念模型CDM:
1. 根据我们的用户分类以及功能需求,在powerdesinger中创建实体,设计实体中的字段和字段属性(类型、长度、注释等)
2. 根据实际需求,连接实体。在设置一对一的关系中,设置父表和字表以及依赖关系
生成物理模型PDM:
1. 完成概念模型设计后,利用powerdesinger可直接生成物理模型
2. 生成的物理模型中,有些字段的类型会自动设置为默认值,需要我们手动修改
生成数据字典:
使用模板生成数据字典
生成SQL文件:
1. 在物理模型中检查每个表的SQL语句
2. 利用物理模型生成SQL文件
在实现设计的过程中,我们也遇到了一些问题:
1. 相互生成外键的错误
原因:在powerdesinger中没有设置一对一关系的子父表
解决办法:设置一对一关系的父(主)表→子(从)表,根据实际需求,设置依赖关系,如果设置为依赖关系则表示外键在子表中作为主键存在。
2. 外键约束问题
如果删除主表的数据,该数据被从表引用了,那么该条不能被删除。
这样的设置可以保持数据的完整性和有效以性
3. 字段类型的选择
字段类型的选择要根据实际需求和字段功能的特点,比如一些字段需要设置为自增,需要设置为int类型。在设置字段类型的时候还要考虑到存储空间的开销,在功能完善的前提下,尽量选择空间开销小的数据类型
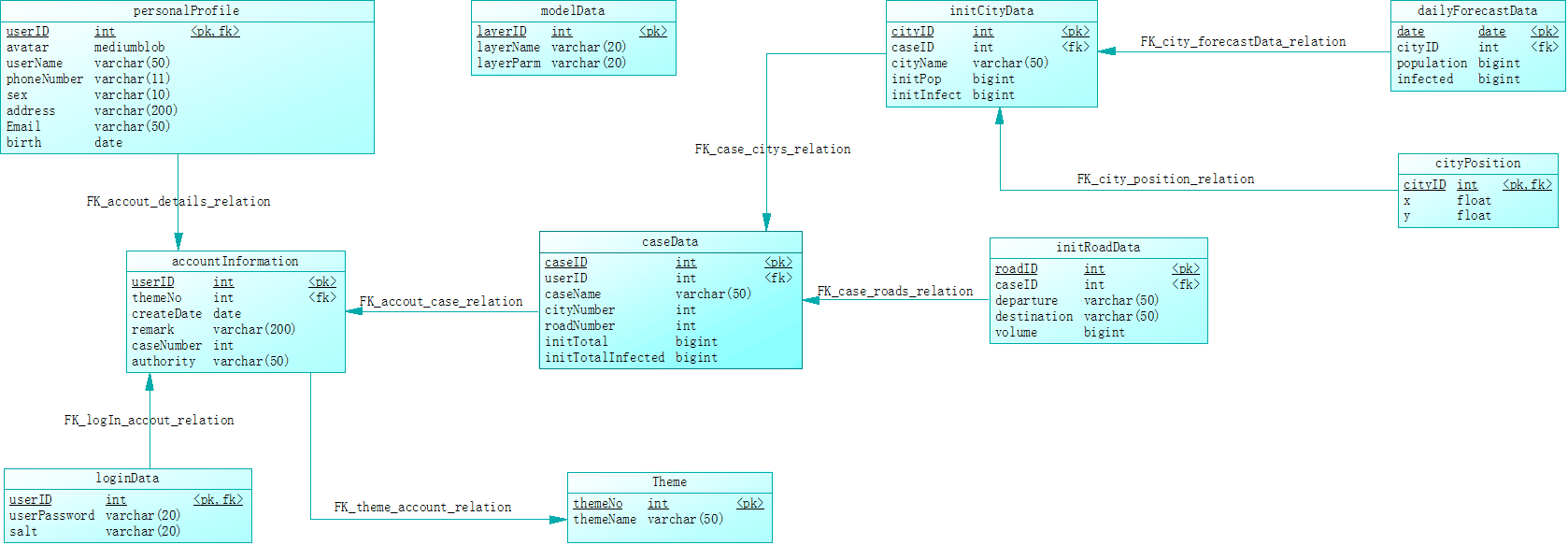
最后生成的数据库E-R图如下所示:
心得体会
在开始设计数据库的时候,我们需要确定实体和实体之间的联系。对于一系列的行为,我们需要确定所涉及到的范围,分析各个行为之间有些什么关系,包含一对一、一对多、多对多的关系,同时细化这些行为并确定业务规则,比如一个用户可以创建多个案例,一个案例可以多次进行模拟等。
然后确定需要的数据,我们的项目包含什么数据,数据都有什么样的特点,各个数据之间会存在什么联系,对于每一个实体列出所要跟踪的所有数据,确定数据使用的属性类型。还要考虑各个数据的计量单位差别,如果将感染人数以万人作为计量单位,感染人数就需要设置成浮点数,同时要考虑精度问题。
对实体、关系和数据进行标准化,搭建CDM,选择各个实体的主键和外键,选择字段是否为必填项,选择对字段的约束等等。

经过几周的讨论和完善,此次数据库设计的版本已经确定下来。虽然说在此之前已经接触到了数据库的相关知识,但是这次的数据库设是第一次接触到数据库设计,最初的经验也很不足,在每一次讨论和完善中不断学习,也对此次项目开发的过程更加了解。在数据库设计过程中,学到了很多经验,在设计表的过程中需要反复推敲,考虑数据库结构性、完整性最好的方案,考虑各个字段的合理性,这个过程十分漫长和复杂。在完成设计之后,还需要反复检验,检验是否符合三个范式,检验设计是否合理。此次数据库设计对我来说是一次尝试与创新的过程,也是一个挑战的过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号