[微服务进阶场景实战] - “微服务数据依赖症”
![[微服务进阶场景实战] - “微服务数据依赖症”](https://img2024.cnblogs.com/blog/2428649/202601/2428649-20260105095759528-1147748526.png) 本文探讨了微服务架构中服务间数据依赖问题的解决方案。针对供应链系统中商品、订单、采购服务间的数据查询需求,传统跨服务调用方案存在性能低下、服务过载和依赖链雪崩三大问题。提出数据冗余方案,通过同步或异步方式更新冗余数据,但面临同步更新导致核心流程被绑架、消息异步更新带来订阅泛滥和逻辑重复等问题。最终采用基于Bifrost的数据同步方案,将商品主数据实时同步至下游服务数据库,实现业务逻辑解耦。该方案具有配置简单、维护成本低等优势,但需注意同步延迟、只读原则和监控等关键事项,避免在核心流程中依赖同步数据。
本文探讨了微服务架构中服务间数据依赖问题的解决方案。针对供应链系统中商品、订单、采购服务间的数据查询需求,传统跨服务调用方案存在性能低下、服务过载和依赖链雪崩三大问题。提出数据冗余方案,通过同步或异步方式更新冗余数据,但面临同步更新导致核心流程被绑架、消息异步更新带来订阅泛滥和逻辑重复等问题。最终采用基于Bifrost的数据同步方案,将商品主数据实时同步至下游服务数据库,实现业务逻辑解耦。该方案具有配置简单、维护成本低等优势,但需注意同步延迟、只读原则和监控等关键事项,避免在核心流程中依赖同步数据。
在解决了数据一致性的麻烦后,我们转向微服务的另一个经典难题:服务间的数据依赖。这就像在一个团队里,每个人都需要频繁向某个同事询问信息,一旦他请假,整个工作就卡住了。还是先来说说具体的业务场景。
1 业务场景:如何解决微服务之间的数据依赖问题
在解决了数据一致性的麻烦后,我们转向微服务的另一个经典难题:服务间的数据依赖。这就像在一个团队里,每个人都需要频繁向某个同事询问信息,一旦他请假,整个工作就卡住了。
以一个供应链系统为例,核心服务包括商品、订单和采购。它们的主要数据结构简化如下:
- 商品表:商品ID、名称、分类、型号、生产年份、编码。
- 订单表:订单ID、下单时间、客户、总金额。
- 子订单表:子订单ID、商品ID、单价、数量。
- 采购单表:采购单ID、下单时间、供应商、总金额。
- 采购子订单表:采购子订单ID、商品ID、单价、数量。
业务上存在这样的查询需求:
- 根据商品的型号、分类、生产年份等属性,查询相关订单。
- 根据同样的商品属性,查询相关的采购单。
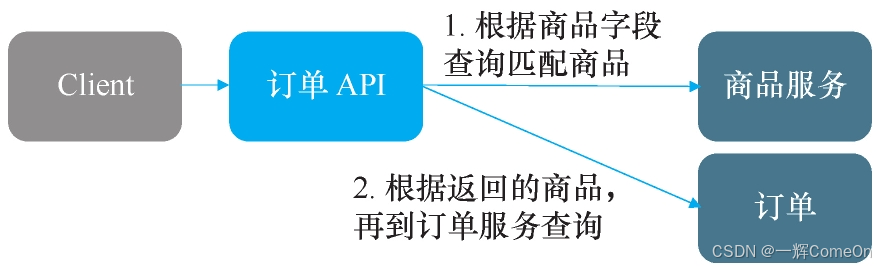
订单的整个查询流程如图所示。
起初,我们严格遵守微服务边界:
- 商品数据的存储与查询职责,完全归属于商品服务。
- 订单服务和采购服务各自管理自己的单据数据。
那么,当需要在订单或采购单中按商品属性查询时,流程被迫变得复杂:
- 调用商品服务:首先,将商品属性(如“型号=A”)发送给商品服务,获取所有匹配的商品ID列表。
- 本地关联查询:接着,在订单或采购服务的数据库中,使用
IN语句,通过上一步得到的商品ID列表,关联查询出最终的单据。
整个查询流程如下图所示(此处为原流程图示意)。
这个方案很快暴露了三大问题:
- 查询性能低下:随着商品数量增长,一次查询可能返回成千上万个商品ID。在订单/采购数据库中用庞大的
IN (...)列表进行关联查询,效率急剧下降。 - 核心服务过载:商品服务成为瓶颈。几乎所有查询都依赖它,导致其负载过高,响应变慢,甚至频繁超时。
- 依赖链雪崩:一旦商品服务响应慢或失败,所有依赖它的订单、采购查询都会跟着失败或超时,用户体验极差。
结果就是:业务人员一旦使用商品条件进行查询,系统就变得又慢又不稳定。于是,团队开始思考一个新方案——数据冗余。这正是我们接下来要详细探讨的解决方案。
2 数据冗余方案
为了解决跨服务查询的效率与依赖问题,一个直接的思路是:在订单、采购等服务中,冗余存储必要的商品信息。调整后的数据结构如下:
- 商品表:商品ID、名称、分类、型号、生产批号ID、编码。(保持不变)
- 订单表与子订单表:在子订单表中,除了商品ID,额外冗余存储商品名称、商品分类ID、商品型号、生产批号ID。
- 采购单表与采购子订单表:做同样的冗余处理。
这样一来,查询订单或采购单时,无需再实时调用商品服务,直接在本地库关联查询即可,性能与稳定性得到保障。
但随之而来的核心问题是:当商品信息更新时,如何同步这些冗余数据? 通常有两种思路:
- 同步调用更新:商品服务在更新自身数据后,同步调用订单、采购等服务提供的接口,触发它们更新本地冗余数据。
- 消息异步更新:商品服务更新后,发布一条消息到消息队列(MQ),由订单、采购等服务各自订阅并异步更新。
我们曾在数据一致性章节讨论过类似场景。那么,这两种方法各自存在什么问题?
先看第一种“同步调用更新”:这会让商品服务在每次更新时,都必须等待下游服务完成冗余数据更新。这带来两个突出问题:
- 核心流程被绑架:如果某个下游服务更新失败,理论上整个操作应该回滚。但商品服务的开发人员肯定会不乐意:冗余数据本非我的核心职责,为何要因为一个“边缘需求”的失败,而阻断我自身核心的商品更新流程?
- 依赖关系倒置与膨胀:商品服务本应是一个稳定的底层服务。但在此方案下,它反而需要主动依赖众多上游服务(订单、采购、库存、运营等)。依赖方越多,其稳定性和迭代速度受影响越大,这与设计初衷背道而驰。因此,该方案被直接否决。
再看第二种“消息异步更新”:这是更常见的做法,其优势明显:
- 商品服务只需发布消息,无需关心下游谁消费、如何处理,职责清晰。
- 即使消费失败,也可利用MQ的重试机制保证最终一致性。
该方案的架构示意如图所示
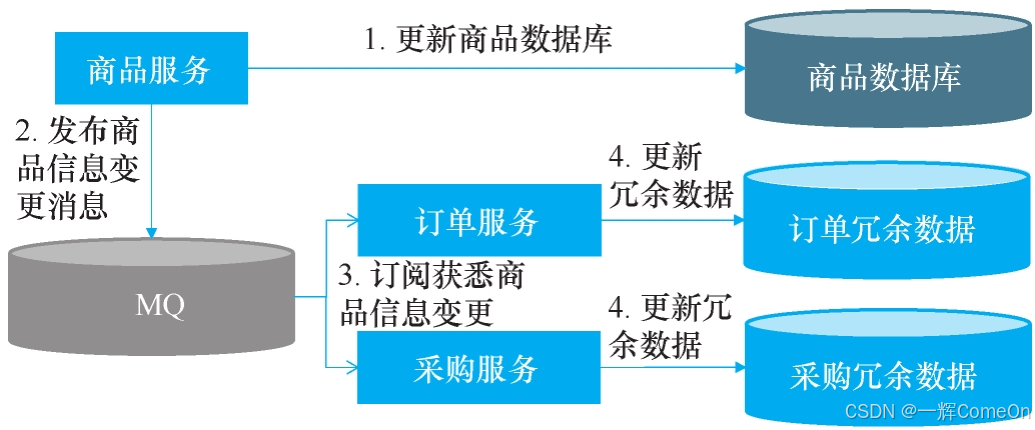
虽然这已是业界普遍做法,但它仍存在以下三个痛点:
- 订阅主题泛滥:要维护的数据远不止基础商品信息。例如,商品分类、生产批号等关联信息变更也需要同步。实践中,一个服务可能需要订阅近十种不同类型的消息,近乎将商品领域的一小半逻辑复制了过来。
- 逻辑重复实现:所有依赖商品数据的服务(订单、采购等),都需要独立实现一套几乎相同的消息监听、数据解析与更新逻辑,导致大量重复代码。
- 联调与运维复杂:基于消息的联调比接口联调更棘手。消息的生产、流转和消费节点不易追踪,为调试而临时修改代码的行为,常因忘记还原而引入线上问题。我们并不希望一个非核心的冗余需求,带来如此复杂的消息拓扑。
鉴于上述问题,项目组决定采用一个更彻底的数据同步方案来解耦业务逻辑。
3 解耦业务逻辑的数据同步方案
为根治服务间复杂的数据依赖,我们采用了一种更为彻底的方案,其核心在于将数据同步与业务逻辑完全解耦。设计思路清晰直接:
- 数据层实时同步:借助数据同步工具,将商品主数据及其关联表(如分类、生产批号、保修类型等)的全量及增量变更,实时同步至下游服务(如订单、采购)的数据库中,并保持表结构原封不动。
- 本地化关联查询:当下游服务需要查询时,直接在自己的数据库中关联这些同步过来的“副本表”,如同使用本地表一样高效、稳定。
- 严格的读写权限:明确规定,下游服务仅拥有对这些副本表的读取权限,禁止任何形式的修改,确保数据来源单一、权威。
该方案的架构示意如图所示
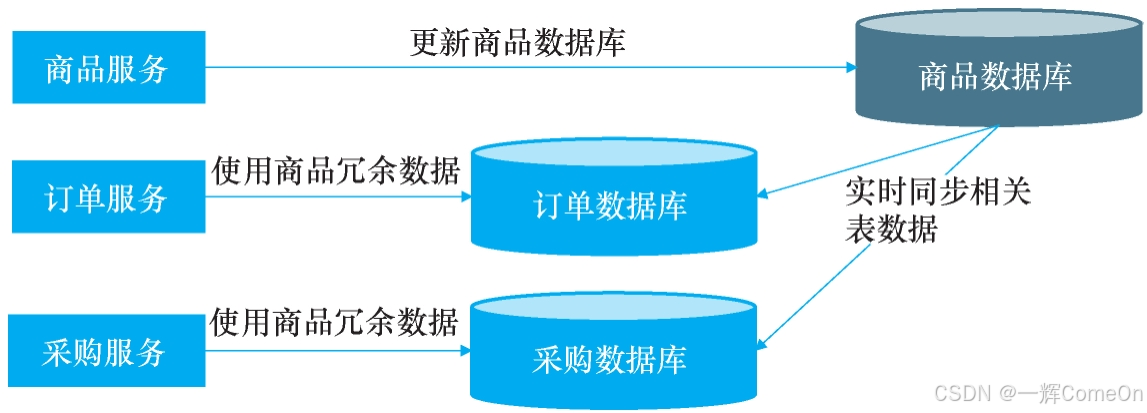
它一举解决了此前方案的核心痛点:
- 对上游商品服务:实现了“零依赖”与“零感知”。它既无需调用其他服务,也无需发布消息,同步成败与否均不影响其核心流程,彻底轻装上阵。
- 对下游订单/采购服务:实现了“零开发”。完全无需编写和维护任何数据同步或消息处理逻辑,只需像查询普通本地表一样使用即可。
当然,此方案会增加下游数据库的存储空间,因为引入了额外的表。但这笔账算下来非常划算:
- 在传统的字段冗余方案中,假设有1000万条订单记录,每条都需要存储一份完整的商品信息副本,即新增1000万条冗余数据记录。
- 而在本方案中,仅需将约10万条商品主数据(及其关联表)同步至下游。实际增加的存储量远小于前者,在空间效率上反而是更优的选择。
至此,一个清晰、低侵扰的方案已浮出水面。接下来最实际的问题是:如何可靠地实现这种跨数据库的实时表同步? 我们将在下一节揭晓具体的技术实现。
4 基于Bifrost的数据同步方案
4.1 技术选型
为解决实时数据同步问题,项目组决定引入一个开源中间件。我们为其设定了五个明确的筛选条件:
- 支持实时同步:延迟需在可接受范围内。
- 支持增量同步:避免每次全量复制,效率是关键。
- 无需编码业务逻辑:目标是“配置即用”,降低开发和维护负担。
- 支持MySQL到MySQL同步:匹配当前技术栈。
- 社区活跃度高:这通常意味着更好的问题响应和可持续性。
根据这些标准,我们对比了Canal、Debezium、DataX、Databus、Flinkx及Bifrost等候选方案。综合评估后,Bifrost脱颖而出。
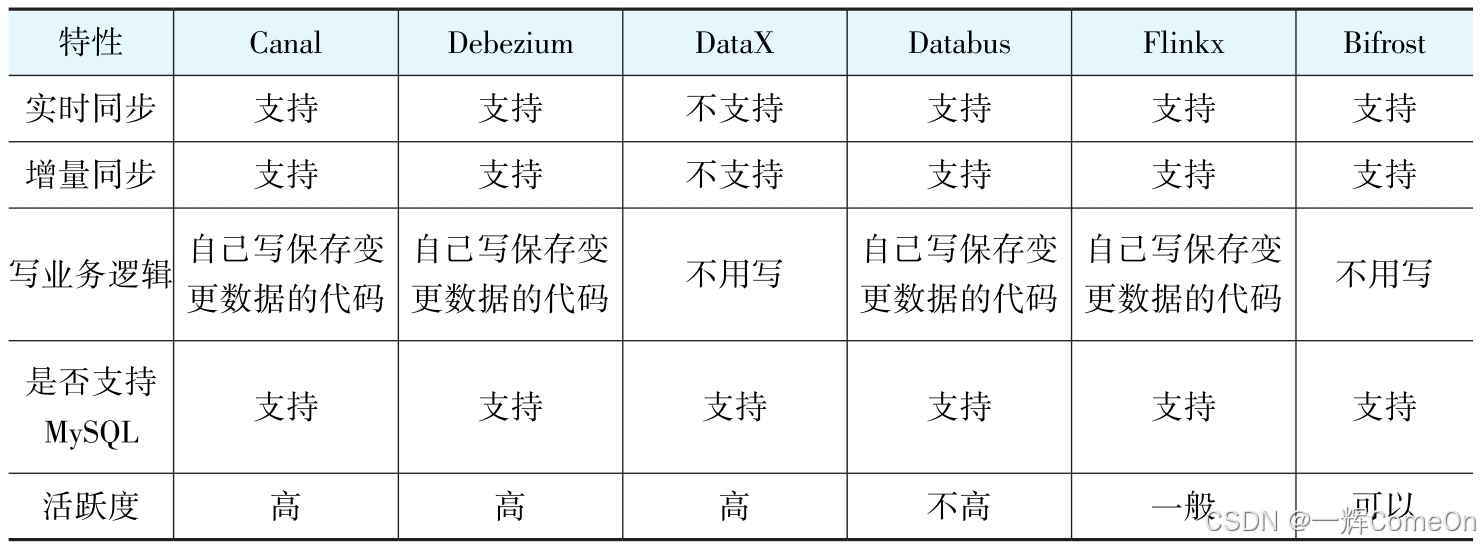
尽管Bifrost相对年轻且不支持原生集群模式,但我们最终选择它,主要基于以下四个务实考量:
- 管理界面友好:提供Web控制台,配置、监控和管理直观便捷,降低了运维门槛。
- 架构简单可控:其核心逻辑清晰,若出现问题,团队有能力进行深度排查甚至自行维护,避免了在复杂黑盒系统前的无助感。
- 作者更新活跃:积极的提交记录和Issue处理让我们对项目生命力更有信心。
- 内置监控报警:开箱即用的监控功能,省去了自行搭建的麻烦。
选定Bifrost后,整体方案架构如图所示。
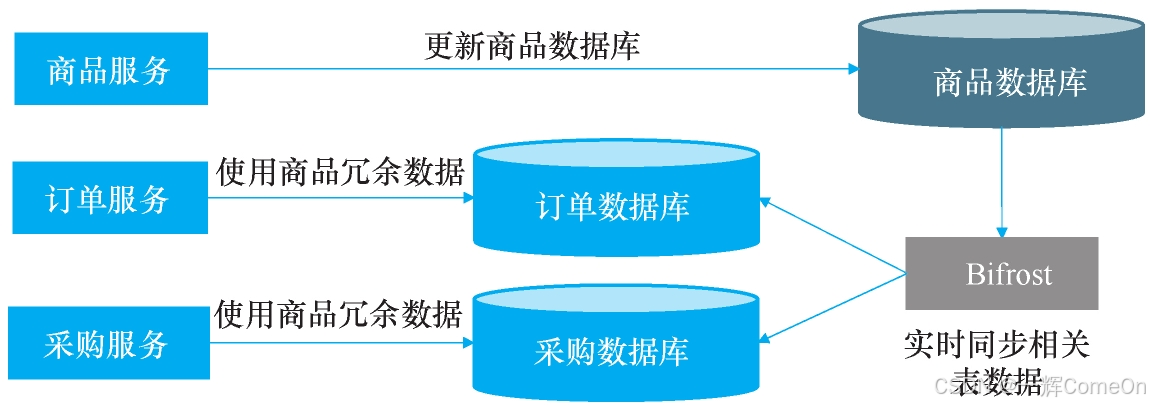
4.2 Bifrost架构
知其然也需知其所以然。Bifrost的工作原理并不复杂,其核心架构如图所示。
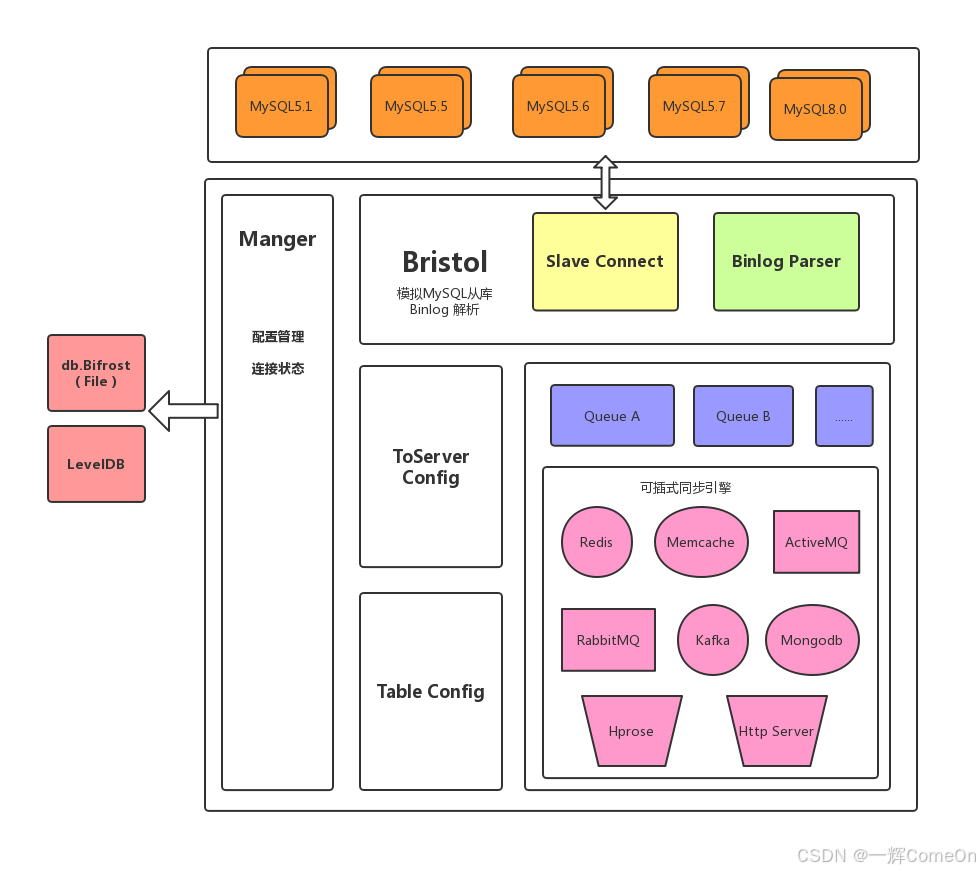
简单来说,Bifrost将自己伪装成一个MySQL从库,通过读取并解析源数据库的Binlog(二进制日志)来捕获数据变更,随后将这些变更实时应用到目标数据库中。它支持多种目标数据源,而本项目正是用于实现MySQL到MySQL的同步。
4.3 注意事项
引入任何技术都需明确其边界。使用此方案,必须牢记以下几点:
- 正视同步延迟:该方案存在毫秒到秒级的固有延迟。因此,对时效性要求极高的业务逻辑(如实时库存校验),不应依赖同步数据,而应直接调用服务接口。同步来的数据,主要应用于查询、展示和分析等非实时强一致性场景。
- 坚守只读原则:同步是单向的。目标库中同步过来的数据应视为“只读副本”,严禁在业务层对其进行修改。任何数据修正都必须回归源头系统,再经由同步链路分发,以保障数据权威性。
- 监控必须到位:鉴于Bifrost并非高可用设计,对其服务状态的监控至关重要。除了利用其内置告警,建议建立独立的健康检查机制(Bifrost提供了API便于集成),确保在服务异常时能第一时间被发现和处理。
- 核心逻辑避免依赖:基于延迟和可用性考虑,关键业务流程不应建立在同步数据之上。例如:
- 防超卖库存检查:应直接调用库存服务,而非查询本地同步的库存快照。
- 权限校验:应实时对接权限中心,而非使用可能滞后的本地权限数据副本。
5 小结
方案上线后,商品数据的同步稳定运行,达成了预期目标:
- 商品团队:只需专注核心领域,无需为数据消费者分心。
- 采购/订单团队:在查询时进行简单的表关联即可,彻底摆脱了同步逻辑的纠缠。可谓双赢。
唯一的遗憾是Bifrost的单点架构。然而在实践中,反而是那些设计为多节点高可用的业务服务更常出现故障。Bifrost作者在其文档(开发者文档)中解释了他对“高可用”的谨慎态度,认为过早引入复杂的分布式设计可能增加故障排查难度,并对生产环境保持敬畏。我们部分认同这一观点——在实践中确实遇到过一些号称“高可用”的系统在故障时表现更糟。
当然,这绝非否定高可用的价值,而是特定场景下的权衡。项目组为此准备了应急预案和深度监控,并随时准备在必要时为Bifrost增加灾备能力。
无论如何,我们成功地为“服务间数据依赖”这一痛点找到了一个简洁有效的解决方案。接下来,我们将挑战下一个更复杂的问题:服务间业务流程与逻辑的耦合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号