[微服务进阶场景实战] - 数据一致性
![[微服务进阶场景实战] - 数据一致性](https://img2024.cnblogs.com/blog/2428649/202512/2428649-20251231172110600-959933332.png) 本文探讨了微服务架构中的数据一致性问题及解决方案。针对最终一致性场景,提出基于消息队列的异步补偿方案,通过消息持久化和重试机制确保数据最终一致;对于强一致性需求,对比分析了TCC模式与Seata AT模式,重点推荐Seata AT方案,其通过自动生成回滚日志实现低侵入式分布式事务管理。实践表明,这两种方案能有效解决数据不一致问题,且不会显著增加开发负担,为微服务架构提供了可靠的数据一致性保障。
本文探讨了微服务架构中的数据一致性问题及解决方案。针对最终一致性场景,提出基于消息队列的异步补偿方案,通过消息持久化和重试机制确保数据最终一致;对于强一致性需求,对比分析了TCC模式与Seata AT模式,重点推荐Seata AT方案,其通过自动生成回滚日志实现低侵入式分布式事务管理。实践表明,这两种方案能有效解决数据不一致问题,且不会显著增加开发负担,为微服务架构提供了可靠的数据一致性保障。
前面我们梳理了微服务的九大痛点,其中一部分目前尚无完美解决方案,另一部分则已有可行对策。从本章起,我们将逐一探讨那些“有解”的痛点。首当其冲的,就是数据一致性问题——让我们从一个实际业务场景切入。
1 业务场景:下游服务失败后上游服务如何独善其身
在微服务架构中,一个业务请求常常需要跨多个服务更新多个数据库,示意图如下:
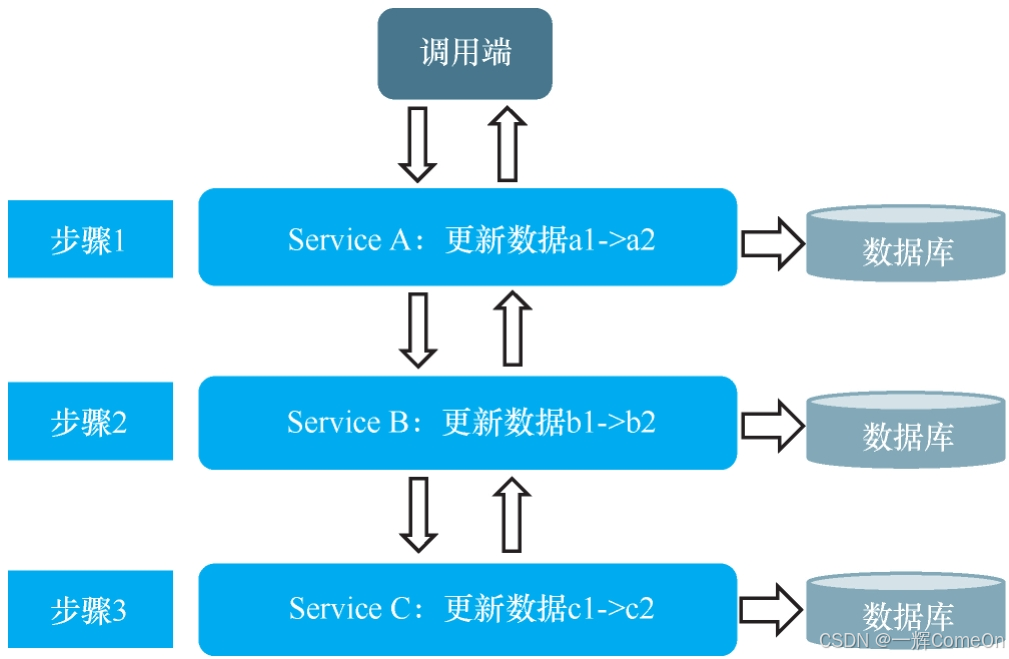
理想情况下,业务顺利完成时,三个服务的数据应依次更新为 a2、b2、c2,此时数据处于一致状态。然而,现实往往充满意外:网络抖动、服务过载、数据库响应缓慢等都可能导致调用链中途失败。例如,若在步骤 2 失败,数据会停留在 a2、b1、c1;若在步骤 3 失败,则变成 a2、b2、c1——数据不一致就这样产生了。
在本项目启动前,由于早期改造工期紧张,开发团队无暇顾及数据一致性问题,导致线上陆续出现错误数据。业务部门通过工单反馈后,IT 团队排查发现,根源正是分布式更新过程中的不一致。
事已至此,团队不得不专门腾出精力,为数据一致性问题设计可靠方案。经过讨论,他们将问题归纳为两类:
第一类:可接受短期不一致,但必须保证最终一致性
以零售下单为例(简化版):订单需依次在商品服务扣库存、订单服务生成订单、交易服务生成交易单。假设生成交易单失败,就会出现库存已扣、订单已生、但交易单缺失的状态。此时只要系统能最终补全交易单,业务即可接受——这就是最终一致性。
第二类:必须保证实时一致性
以积分兑换折扣券为例:需要先扣积分,再发折扣券。若采用最终一致性,用户可能看到积分已扣但券未到账,进而立刻投诉。此时更好的做法是:一旦后续步骤失败,立即回滚前面所有操作,并提示用户“操作失败,请重试”。这就是实时一致性。
那么,针对这两类情况,具体如何实现呢?下面我们分别展开。
2 最终一致性方案
对对于接受最终一致性的场景,核心思路是借助消息队列(MQ)实现跨服务的数据更新“接力”。具体流程如下:
- 每个服务完成本地操作后,向 MQ 发送一条消息,触发下一个服务的处理。
- 下游服务消费消息,完成自身操作后,继续发送消息给更下游的服务。
- 若消费失败,消息应保留在 MQ 中,等待后续重试。
整个调用流程如图所示:
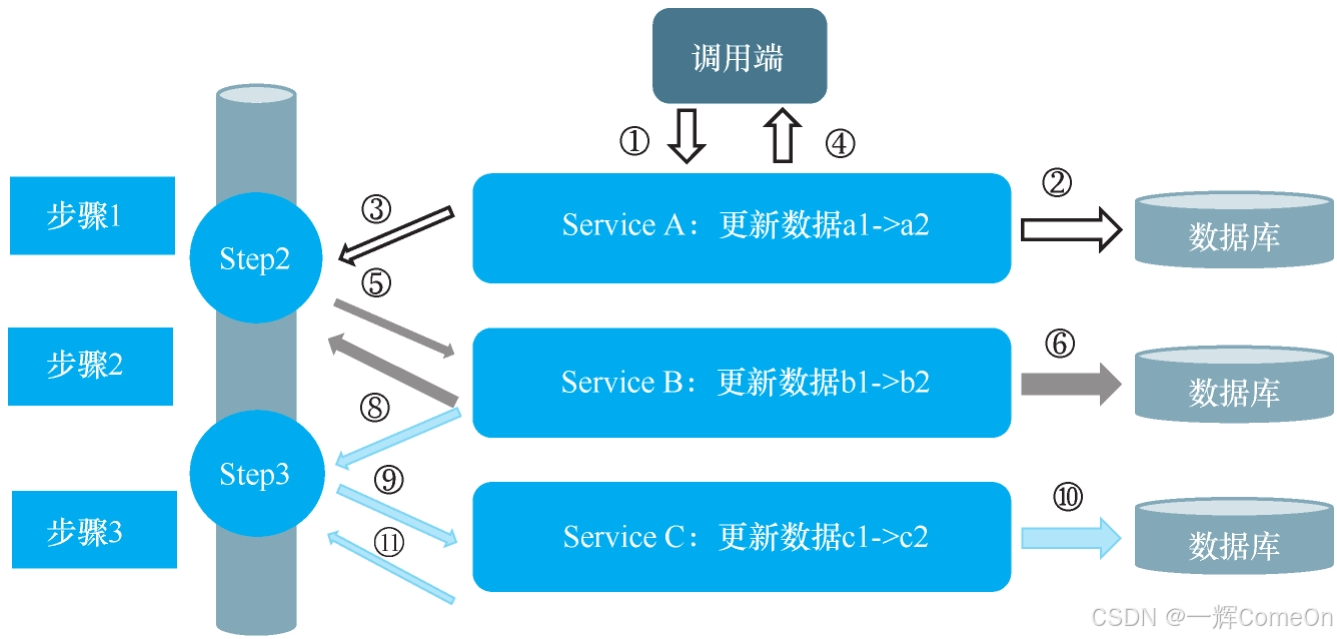
详细步骤与异常处理如下:
| 步骤 | 执行内容 | 失败应对策略 |
|---|---|---|
| 1 | 调用端调用 Service A | 直接返回失败,用户数据无影响 |
| 2 | Service A 将 a1 改为 a2 | 本地事务回滚,数据恢复 |
| 3 | Service A 向 MQ 发送 Step2 消息 | 发送失败则触发本地回滚 |
| 4 | Service A 返回成功响应给调用端 | 无需额外处理 |
| 5 | Service B 消费 Step2 消息 | MQ 自带重试机制,无需担心 |
| 6 | Service B 将 b1 改为 b2 | 本地事务回滚,消息重新投递(重新回到步骤5) |
| 7 | Service B 向 MQ 发送 Step3 消息 | 依赖 MQ 生产端重试机制 |
| 8 | Service B 确认消费 Step2 | 若失败,MQ 会重新投递给其他消费者(重新回到步骤5) |
| 9 | Service C 消费 Step3 消息 | 同步骤 5 |
| 10 | Service C 将 c1 改为 c2 | 同步骤 6 |
| 11 | Service C 确认消费 Step3 | 同步骤 8 |
该方案本质上是利用 MQ 的消息持久化、重试和确认机制,将分布式更新拆解为多个本地事务,通过异步消息串联起来。但还需要注意两个常见问题:
1. 幂等性必须保证
由于 MQ 的重试机制,步骤 6 和步骤 10 可能被重复执行。因此,下游服务在更新数据时,必须实现业务幂等——即同一消息多次消费,结果应与一次消费相同。
2. 代码复用与封装
如果每个业务流程都手动实现上述逻辑,开发量会很大。实际上,MQ 相关的发送、消费、确认逻辑可以抽象为公共组件。本项目最终将这些重复代码封装成通用模块,供各业务服务调用。具体封装方法较为直接,此处不再展开。
3 实时一致性方案
实时一致性其实就是常说的分布式事务。
MySQL其实有一个两阶段提交的分布式事务方案MySQL XA,但是该方案存在严重的性能问题。比如,一个数据库的事务与多个数据库间的XA事务性能可能相差10倍。
另外,XA的事务处理过程会长期占用锁资源,所以项目组一开始就没有考虑这个方案。而当时比较流行的方案是使用TCC模式,下面简单介绍一下。
4 TCC模式:一分为三的补偿型事务
TCC(Try-Confirm-Cancel)是一种补偿型事务方案。它将一个完整的业务接口逻辑拆解为三个独立的操作阶段:
- Try:尝试执行。负责完成所有业务检查,并预留必要的资源(例如冻结积分、锁定库存)。
- Confirm:确认执行。真正执行业务操作,使用Try阶段预留的资源,通常保证成功。
- Cancel:取消执行。用于释放Try阶段预留的资源,进行业务回滚。
以“积分兑换折扣券”为例,涉及“账户服务扣积分”和“营销服务发折扣券”两个操作。那么,仅“扣积分”这一个接口,就需要拆分为以下三个方法:
public boolean prepareMinus (BusinessActionContext businessActionContext,
final String accountNo,
final double amount){
//[校验] 账户积分余额
//[冻结] 积分金额
}
public boolean Confirm(BusinessActionContext businessActionContext){
//[扣除] 账户积分余额
//[释放] 账户,冻结积分金额
}
public boolean Cancel(BusinessActionContext businessActionContext){
//[回滚] 所有数据变更
}
理,“发折扣券”接口也需要编写对应的三个方法。其成功调用的流程示意如图所示。

该流程中,除Cancel路径外,代表成功调用链。一旦任何环节出错,事务管理器将协调调用所有已执行服务的Cancel方法进行回滚。
TCC模式将一段业务逻辑拆成三部分,实施复杂度显著增加,并需谨慎处理以下问题:
- 空提交:需保证Try成功,Confirm必定成功。
- 空回滚:需处理Try未执行却收到Cancel调用的情况,实现正确回滚。
- 防悬挂:需防止因网络拥堵,Cancel先于Try到达导致资源被永久锁定。
- 幂等性:所有Try、Confirm、Cancel操作都必须支持重复调用。
- 数据隔离:事务期间数据处于中间状态(如“冻结”),需设计得当,避免对其他业务逻辑造成干扰。
可见,TCC模式实现相当繁琐,不仅业务代码量激增,还需精心处理上述各类边缘情况,开发和维护成本高,易出错。幸运的是,存在更优的替代方案,例如Seata框架提供的AT模式。
5 Seata AT模式:基于SQL反向补偿的自动回滚
AT(Automatic Transaction)模式,即自动(分支)事务模式。其最大优点是对业务侵入极低。
开发者只需做两件事:
- 在全局事务的发起方方法上添加
@GlobalTransactional注解。 - 在各个参与服务的本地方法上,继续使用普通的
@Transactional注解。
Seata官网对这块介绍的非常详细,有兴趣的朋友可以看一下:Apache Seata。在这里简要概括一下,其核心机制在于,Seata会自动拦截并解析业务SQL,通过生成并管理反向回滚日志,实现分布式事务的自动协调。整个过程可简要概括为三个阶段:
第一阶段:执行与日志记录
- 解析SQL:拦截业务SQL,解析其操作类型、表、条件等。
- 保存前置镜像:根据解析条件查询数据,保存更新前的状态(Before Image)。
- 执行业务SQL:执行用户定义的更新操作。
- 保存后置镜像:查询更新后的数据状态(After Image)。
- 插入回滚日志:将前后镜像数据及SQL信息组成回滚日志,存入
UNDO_LOG表。 - 注册与锁:向事务协调器(TC)注册分支事务,并获取相关数据的全局锁。
- 本地提交:提交业务数据更新和
UNDO_LOG。 - 上报结果:将本地事务提交结果上报给TC。
第二阶段:回滚(如需要)
若收到TC发出的回滚指令,则:
- 开启本地事务,查找对应的
UNDO_LOG记录。 - 数据校验:对比
UNDO_LOG中的后镜像与当前数据。若不一致(说明数据被其他事务修改),需根据策略处理。 - 生成并执行回滚SQL:根据前镜像数据,生成反向SQL执行,恢复数据。
- 提交并上报:提交本地事务,删除
UNDO_LOG,并向TC上报回滚结果。
第三阶段:异步清理
收到TC的提交指令后,异步、批量地删除对应的 UNDO_LOG 记录,完成资源清理。
6 为何选择Seata:一个务实的工程决策
当时,Seata虽未发布正式版,但我们项目组仍决定采用,主要基于两点现实考量:
- 场景可控:需要强实时一致性的业务场景占比少、频率低,影响范围有限。对于高频、高并发的场景,我们会优先与业务方沟通,采用最终一致性方案,从而规避性能风险。
- 投入产出比高:相较于TCC模式需要将每个业务逻辑“一拆三”并处理各种异常,AT模式仅需增加一个
@GlobalTransactional注解,开发工作量天差地别。这种显著的效率提升,使得尝试新技术带来的风险变得可以接受。这或许也是Seata能迅速流行的原因之一。
尽管AT模式存在一些小缺陷(如全局锁对性能的细微影响),但瑕不掩瑜,其易用性优势在大多数场景下非常突出。
7 小结:缓解痛点,轻装前行
通过为“最终一致性”和“实时一致性”场景分别设计并落地了基于MQ的异步补偿方案与基于Seata AT模式的自动补偿方案,我们成功解决了数据不一致的核心痛点。
关键成果在于:这些方案并未给业务开发带来显著负担,也未影响项目正常推进,却极大降低了数据错误的发生概率。
至此,数据一致性的痛点已得到有效缓解。接下来,我们将面对微服务架构中的另一个常见难题:服务间数据依赖复杂,导致需要编写大量冗余数据获取与组装逻辑。这个问题又该如何破解?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号