
Linux文件系统与日志分析
Linux文件系统与日志分析
一、inode与block
1、inode与block概述
1)bolck(块)
①、连续的八个扇区组成一个block(4K)
②、是文件存取的最小单位
2)inode(索引节点)
①、中文译名为“索引节点”,也叫 i节点
②、用于存储文件元信息
注:一个文件必须占用一个 inode,但至少占用一个block
-
文件是存储在硬盘上的,硬盘的最小存储单位叫做“扇区”(sector),每个扇区存储512字节。
-
一般连续八个扇区组成一个“块”(block),一个块是4K大小,是文件存取的最小单位。操作系统读取硬盘的时候,是一次性读取多个扇区,即一个块一个块的读取的。
-
文件数据包括实际数据与元信息(类似文件属性)。文件数据存储在”块“中,存储文件元信息(比如文件的创建者、创建日期、文件大小、文件权限等)的区域叫做inode。因此,一个文件必须占用一个inode,并且至少占用一个block。
-
inode不包含文件名。文件名是存放在目录当中的。linux系统中一切皆文件,因此目录也是一种文件
-
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称,文件名和inode号码是一一对应关系,每个inode号码对应一个文件名。
-
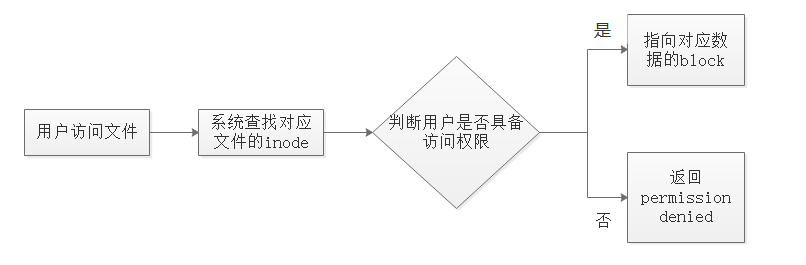
当用户在Linux系统中试图访问一个文件时,系统会根据文件名去查找它对应的inode 号码,通过Inode号码。获取Inode 信息;根据inode信息,看该用户是否具有访问这个文件的权限;如果有,就指向相对应的数据block,并读取数据。
2、inode的内容
1)inode包含文件的元信息,包括:
-
文件的字节数
-
文件拥有者的User ID
-
文件的Group ID
-
文件的读、写、执行权限
-
文件的时间戳
-
……
注:文件拥有着的User ID不包含文件名
2)用 stat命令可以查看某个文件的 inode信息
①、格式:stat 文件名
②、例:stat abc.txt
3、查看文件名对应的inode号码
1)ls -i 文件名:只显示文件对应的 inode号,不能显示指定目录的 inode号,可以显示目录内所有文件的目录的inode号
2)stat 文件名:会显示文件的元信息,也可以指定目录显示

4、Linux系统文件三个主要的时间属性
1)ctime(change time)
最后一次改变文件或目录(属性)的时间
2)atime(access time)
最后一次访问文件或目录的时间
3)mtime(modification time)
最后一次修改文件或目录(内容)的时间
5、目录文件的结构
1)Linux系统中,一切皆为文件。因此,目录也是一种文件。
2)目录文件的结构:

注:每一行称为一个目录项。
3)每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
4)Linux系统内部不适用文件名,而使用inode号码来识别文件。
5)对于用户,文件名只是inode号码便于识别的别称。
6、用户通过文件名打开文件时,系统内部的过程
1)系统找到这个文件名对应的inode号码
2)通过inode号码,获取inode信息
3)根据inode信息,找到文件数据所在的block,读出数据
7、银盘分区后结构和访问文件简单流程
1)硬盘分区后的结构
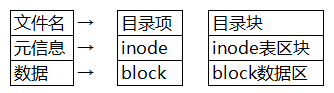
2)访问文件的简单流程
8、inode的大小
1)inode也会消耗硬盘空间
①、每个inode的大小
②、一般是128字节或者256字节
2)格式化文件系统时确定inode的 总数
3)df-i 查看每个硬盘分区对应的inode总数以及使用数
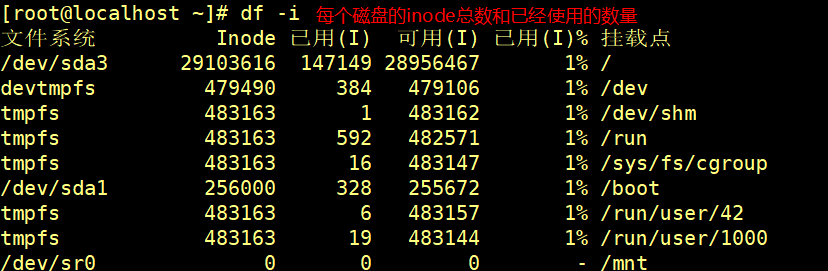
注:
-
inode也会消耗硬盘空间,所以格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据; 另一个是 inode区,存放 inode 所包含的信息。每个 inode 的大小,一般是 128 字节或 256 字节。
-
通常情况下不需要关注单个 inode 的大小,而是需要重点关注 inode 总数。inode 的总数在格式化时就给定了,执行"df-i"命令即可查看每个硬盘分区对应的的 inode 总数和已经使用的inode 数量。
9、inode的特殊作用
由于inode号码与文件名分离,导致一些Unix/Linux系统具有以的现象:
-
当文件名包含特殊字符,可能无法正常删除文件,直接删除inode,也可以删除文件
-
移动或重命名文件时,只改变文件名,不影响inode号码
-
打开一个文件后,系统通过inode号码来识别该文件,不再考虑文件名
-
文件数据被修改保存后,会生成一个新的inode号码
10、通过inode号删除文件命令
1)find ./ -inum 52305140 -exec rm -i {} ;
2)find ./ -inum 50464299 -delete

11、inode节点耗尽故障模拟处理
1)使用fdisk创建分区/dev/sdb1,分区大小30M即可
-
fdisk /dev/sdb
-
mkfs.ext4 /dev/sdb1
-
mkdir /test
-
mount .dev/sdb1 /mnt
-
df -i
2)模拟inode节点耗尽故障
-
for ((i=1;1<=7680;i++));do touch /test/file$i;done touch(1..7680).txt
-
df -i
-
df -hT
3)删除文件恢复inode
-
rm -rf /test/*
-
df -i
-
df -hT
二、硬链接与软链接
1、链接文件的分类
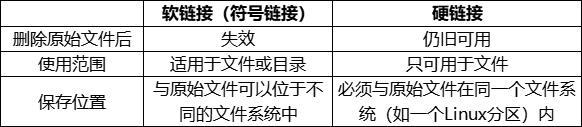
2、如何建立链接
1)硬链接:ln 源文件 目标位置
2)软链接:ln -s 源文件或目录 链接文件或目标位置
三、恢复误删除的文件
1、恢复EXT类型的文件
1)extundelete工具
①、extundelete是一个开源的Linux数据恢复工具,支持ext3、ext4文件系统。(ext4只能在CentOS 6版本恢复)
2)模拟删除并执行恢复操作
①、使用fdisk创建分区/dev/sdc1,格式化ext3文件系统
-
fdisk /dev/sdcpartprobe /dev/sdc
-
mkfs.ext3 /dev/sdc1
-
mkdir /test
-
mount /dev/sdc1 /test
-
df -hT
②、安装依赖包
-
yum -y inatll e2fsprogs-devel e2fsprogs-libs
③、编译安装extundelete
-
cd /test
-
wget http://nchc.dl.sourceforge.net/project/extundelete/extundelete/0.2.4/extundelete-0.2.4.tar.bz2 ## 下载文件
-
tar jxvf extundelete-0.2.4.tar.bz2
-
cd extundlete-0.2.4/
-
./configure --prefix=/usr/local/extundelete && make && make install
-
ln -s /usr/local/extundelete/bin/* /usr/bin/
③、执行恢复操作
-
cd /test
-
echo a>a
-
echo a>b
-
echo a>c
-
echo a>d
-
ls
-
extundelete /dev/sdc1 --inode 2 ##查看文件系统/dev/sdc1下存在哪些文件,i节点是从2开始的,2代表该文件系统最开始的目录
-
rm -rf a b
-
extundelete /dev/sdc1 --inode 2
-
cd ~
-
umount /test
-
extundelete /dev/sdc1 --restore -all ## 恢复/dev/sdc1文件系统下的所有内容
在当前目录下会出现一个RECOVERD_FILES/目录,里面保存了已经恢复的文件
-
ls RECOVERD_FILES/
2、XFS文件的备份和恢复
1)xfsdump工具
①、CentOS 7系统默认采xfs文件系统,xfs类型的文件可使用xfsdump与xfsrestore工具进行备份恢复。
②、xfsdump的备份级别有两种:0表示完全备份,1-9表示增量备份。xfsdump的默认备份级别为0。
2)xfsdump的命令格式
-
xfsdump -f 备份存放位置 要备份的路径或设备文件
3)xfsdump命令的常用选项
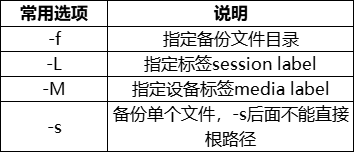
4)xfsdump的使用限制
①、只能备份已挂载的文件系统
②、必须使用root的权限才能操作
③、只能备份xfs文件系统
④、备份后的数据只能让xfsdump解析
⑤、不能备份两个具有相同UUID的文件系统(可用blkid命令查看)
5)模拟数据丢失并恢复
①、使用fdisk创建分区/dev/sdb1,格式化xfs文件系统
-
fdisk /dev/sdb
-
partprobe /dev/sdb
-
mkfs.xfs [-f] /dev/sdb1
-
mkdir /data
-
mount /dev/sdb1 /data/
-
cd /data
-
cp /etc/passwd ./
-
mkdir test
-
touch test/a
②、使用xfsdump命令备份整个分区
-
rpm -qa | grep xfsdump
-
yum install -y xfsdump
-
xfsdump -f /opt/dump_sdb1 /dev/sdb1 [-L dump_sdb1 -M sdb1]
③、模拟数据丢失并使用xfsrestore命令恢复文件
-
cd /data
-
rm -rf ./*
-
ls
-
xfsrestore -f /opt/dump_sdb1 /data/
四、日志文件
1、日志的功能
1)用于记录系统、程序运行中发生的各种事件
2)通过阅读日志,有助于诊断和解决系统故障
2、日志文件的分类
1)内核及系统日志
-
由系统服务rsyslog统一进行管理,日志格式基本相似
-
主配置文件为/etc/rsyslog.conf。
-
Linux操作系统本身和大部分服务器程序的日志文件都保存在/var/log下。
2)用户日志
-
记录系统用户登录及退出系统的相关信息
3)程序日志
-
由各种应用程序独立管理的日志文件,记录格式不统一
3、日志的保存位置
默认位于:/var/log目录下

注:vim /etc/rsyslog.conf # 查看rsyslog.conf配置文件
*.info;mail.none;authpriv.none;cron.none /var/log/messages
*.info # 表示info等级及以上的所有等级的信息都写到对应的日志文件里
mail.none # 表示某事件的信息不写到日志文件里 (这里比如是邮件)
4、内核及系统日志
1)由系统服务rsylog统一管理
①、软件包:rsylog-7.4.7-16.el7.x86_6
②、主要程序:/sbin/rsyslohd
③、配置文件:/etc/rsyslog.conf
5、日志消息的级别
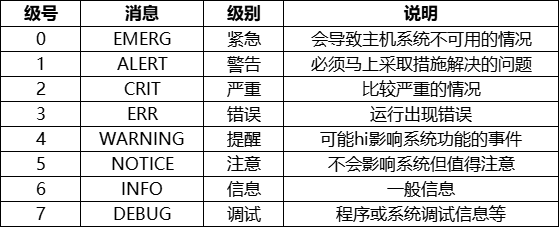
6、公共日志文件的记录格式
时间标签、主机名、子系统名、消息字段组成


7、用户日志分析
①、保存了用户登录、退出系统等相关信息
-
/var/log/lastlog:最近的用户登事件
-
/var/log/wtmp:用户登录、注销及系统开、关机事件
-
/var/run/utmp:当前登录的每个用户的详细信息
-
/var/log/secure:与用户验证相关的安全性事件
②、分析工具
-
users、who、w、last、lastb
-
last命令用于查询成功登录到系统的用户记录
-
lastb命令用于查询登陆失败的用户记录
8、程序日志分析
1)由相应的应用程序独立进行管理
①、Web服务:/var/log/httpd/
-
access_log // 记录客户访问事件
-
error_log // 记录错误事件
②、代理服务:/var/log/squid/
-
access.log
-
cache.log
2)分析工具
①、文本查看、grep过滤检索、Webmin管理套件中查看
②、awk、sed等文本过滤、格式化编辑工具
③、Webalizer、Awstats等专用日志分析工具
9、日志管理策略
1)及时做好备份和归档
2)延长日志保存期限
-
find ./ -mtime +30 -exec rm -rf {} ; 删除30天以前的日志文件
3)控制日志访问权限
-
日志中可能会包含各类敏感信息,如账户、口令等
4)集中管理日志
-
将服务器的日志文件发到统一的日志文件服务器
-
便于日志信息的统一收集、整理和分析
-
杜绝日志信息的意外丢失、恶意篡改或删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号