


1.爬虫介绍
编写程序,根据URL获取网站信息
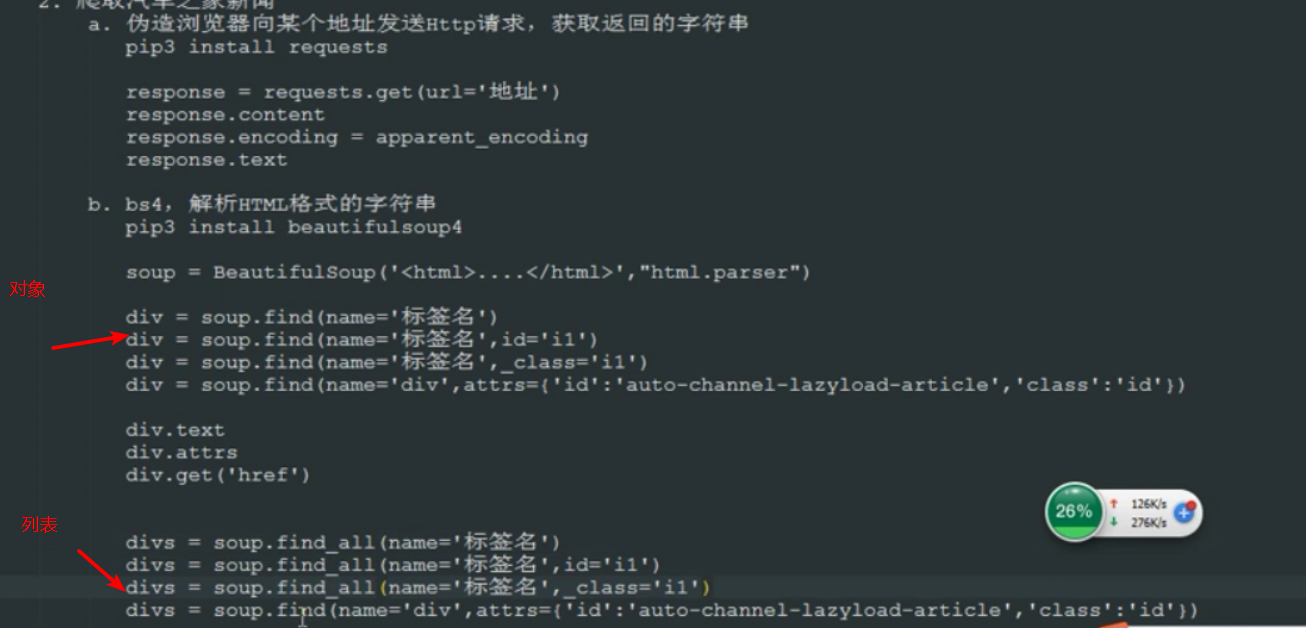
2.用到的库
requests库
bs4库
3.内容及步骤
4.代码
import requests
import os
from bs4 import BeautifulSoup
# 1.下载页面
ret = requests.get(url='https://www.autohome.com.cn/news/')
ret.encoding = ret.apparent_encoding
# print(ret.text) 爬取的内容
# 2.解析:获取想要的指定内容beautifulsoup
soup = BeautifulSoup(ret.text, 'html.parser') # lxml
div = soup.find(name='div', id='auto-channel-lazyload-article')
li_list = div.find_all(name='li')
# 更改下载地址
os.mkdir("图片")
os.chdir("图片")
for li in li_list:
# 获取新闻标题
h3 = li.find(name='h3')
if not h3:
continue
# 获取新闻内容
p = li.find(name='p')
# 获取链接地址
a = li.find(name='a')
# print(a.attrs)获取属性
print(h3.text,
a.get('href'),
p.text
)
print('=' * 15)
# 获取图片链接并下载
img = li.find('img')
src = img.get('src')
# 根据__分割,得到列表
file_nane = src.rsplit('__', maxsplit=1)[1]
ret_img = requests.get(
url='https:' + src
)
with open(file_nane, 'wb') as f:
f.write(ret_img.content)
find的扩展:
可以用:
1.id,_class
2.attrs方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号