提取b站视频封面,提取微信推文封面,提取微信推文中的视频频,提取浏览器中标签页的图标和文字
题外话
讲个题外话
“什么时候应该造轮子,什么时候不应该造轮子?”是个经常被讨论的问题
这是一个很有意思的问题
我来谈谈我的看法
比如说你想锻炼自己的技术,想了解清楚底层的那些东西是如何运作的,那你应该去造轮子
你觉得别人写的东西太烂了,你有一个几乎没人做的关于底层优化的idea,那。。。你当然要去造轮子。。。(膜拜,大佬带带我)
如果你使用电脑更多的是想高效地完成任务,而不是没事钻研底层原理,那你应该用现成的工具,方法得当的话效率是很高的。正规平台发布的工具的安全性是很高的。
方法论
有时候我会面对十分相似的任务,我可能这会想要提取个b站视频封面,过会又要提取个微信公众号封面,或者又要提取个微信推文里的视频。
它们是十分相似的。
方法无非那几种:
1.f12检查。
找到对应的html标签,找到url。
打开network选项卡,刷新页面,可能能找到你要的资源。
ctrl shift c开始“选择html元素”,然后鼠标左键选中可能相关的位置,定位到关联的html段落,查找可能出现的url
2.在1的基础上,写个py文件爬取
3.使用通用爬虫软件爬取,难点在于描述清楚你想爬取的东西是什么
4.使用网络资源嗅探的chrome扩展,比如chrome下载管理器。和使用扩展类似的是添加脚本。
5.IDM嗅探
使用上述5种方法,你几乎可以高效得到绝大多数需要的网络资源
解决方案总结
还是写个对上面提到的任务的解决方案总结吧,贼没意思。你甚至能找到比我这里提到的更为高效的方法。
- 提取b站视频封面。
a) 右键,选“在新标签页中打开图片”
b)
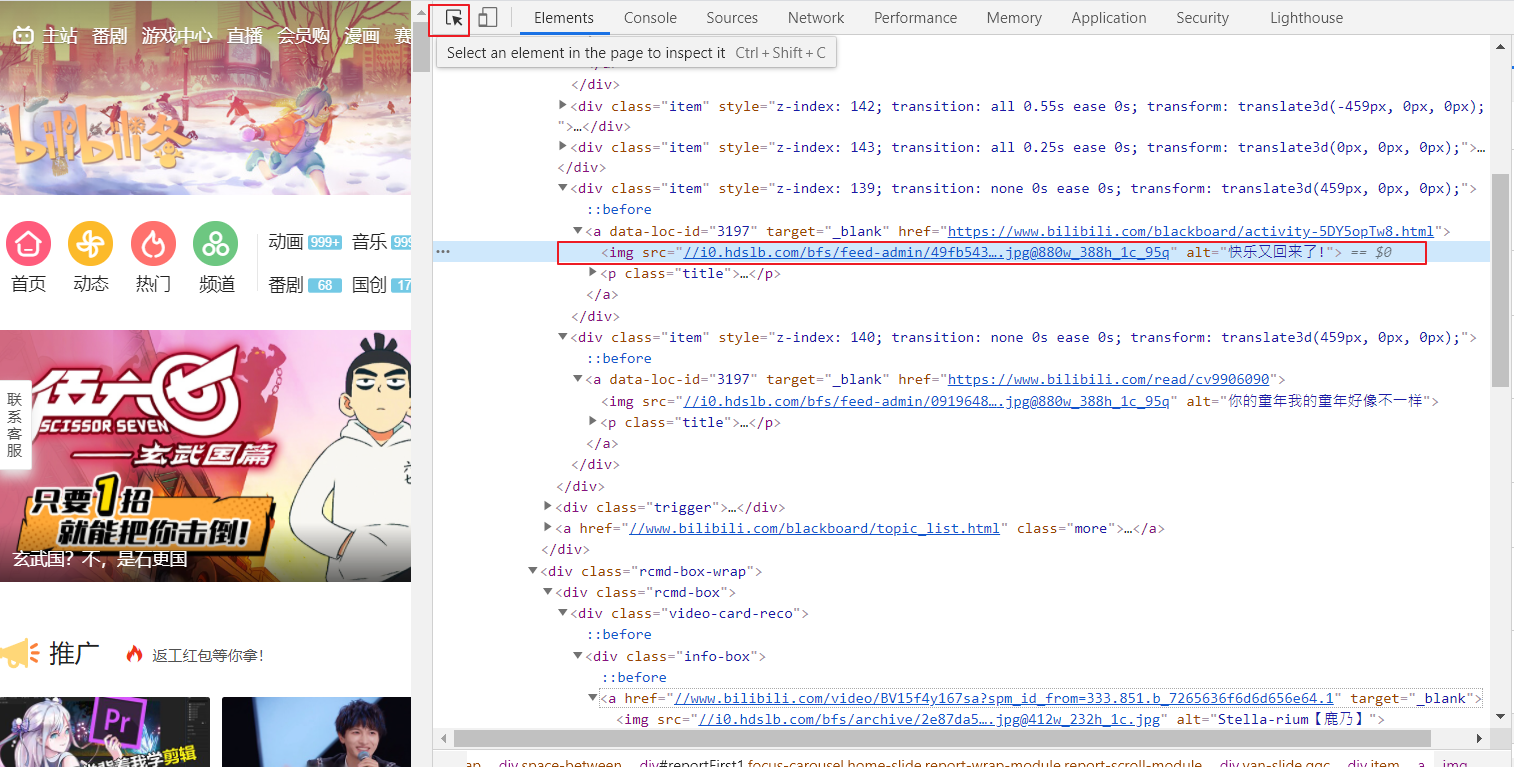
先点那个选择html元素按钮,然后点击你感兴趣的那个区域,之后定位到关联的html段落,src=那里就是你要的url。然后你怎么来都行了其实,chrome browser这时候鼠标右键会出现很多功能。chrome browser的检查功能做得很强大。
==$0表示这个html element是我上一次选择的element - 提取微信公众号封面
f12,ctrl f,找msg_cdn_url,会找到var msg_cdn_url="";这样的句子,""里就是你要的url。 - 提取微信推文里的视频
审查,network选项卡,过滤器选择media,播放视频,找到了 - 浏览器中标签页的图标和文字
以这个url为例子:https://www.cnblogs.com/yhm138/articles/14424223.html
f12审查,在head中找特定的标签

送个博客园的logo,svg文件 http://common.cnblogs.com/favicon.svg
今天才发现这个叫favicon,原谅我是前端文盲。我是从"前端阳光"公众号第一次知道favicon的。
你也可以用在线的Favicon提取工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号