
自动生成测试用例Agent工作流搭建
2025-06-05 14:46 _天枢 阅读(1336) 评论(2) 收藏 举报前言
随着2024年以来AI的火爆,各行各业都在探索,当然做为测试也不能落后于人,AI是真的能解决我产很多繁杂工作,解放双手;
接下来开始今天正题;
本次使用的是trae国际版,主要是为了使用免费的cluade大模型;
Agent项目结构
.trae --rules --project_rules.md #存储规则 markdown --生成的用例.md task --task.yaml #任务流 testcase #生成的csv用例存储路径 utils #一些必要脚本 workflows #工作流 --flows.yaml xmind #存储原始的需求分析文档

一、project_rules.md
你是与用户紧密协作的智能体,始终使用中文沟通,始终遵循以下顶级规则,严格遵守会受到奖赏,否则会受到惩罚。 - 顶级工作模式:上传需求文件规则>预估生成用例数量>用例生成规则>用例对比补充>用例文件导出规则 - 当用户输入以 "/" 开头时,必须触发对应的**工作管理任务指令** ## 任务字段说明 - name: 命令名称、功能 - triggers: 指令触发条件,用于判断用户是否输入了指令 - description: 命令描述 - file: 指令文件路径 - steps: 指令运行步骤,请一步一步的进行 - script: 指令运行脚本 ## 工作管理任务指令 [ { "name":"将提供以下工作管理指令供用户选择", "trigger":"/", "description":"要求只向用户展示工作指令的trigger、name和description", }, { "name":"测试用例生成工作", "description":"测试用例生成工作", "trigger":"/test", "file":"./task/task.yml", }, { "name":"xmind转md工作", "description":"将xmind文件转换为md文件", "trigger":"/tomd", "script":"python ./utils/xmind_to_md.py", }, { "name":"初始化环境2", "description":"初始化环境", "trigger":"/init", "script":"python ./utils/init_environment.py", }, { "name":"csv转xlsx", "description":"所有csv用例转换为xlsx格式", "trigger":"/toxls", "script":"python ./utils/csv_to_xlsx.py", } ]
二、task.yaml
# 工作流基本信息 id: test_workflow name: "测试用例生成任务" description: "测试用例生成任务流程" version: "1.0" # 工作流规则 rules: - 分析要尽可能详细 - 分析需求md文件时必须阅读全部内容 - 生成的所有文档如果没有指定明确路径,则统一放在 {{testcase}} 目录下 - 任务执行时,必须查阅 input 中指定的文档,这是必要的前置知识 - 任务执行时,无论任何情况下,output内容都必须遵照doc指定文件格式 - 编写文档前,先输出内容给用户查阅,等用户确认后再写入文档,避免写错反复修改 # 工作步骤定义 tasks: - name: 测试用例生成 description: "测试用例生成流程" input: - doc: ./agent_test/markdown/*.md rule: - "严格遵守当前工作、任务、步骤的规则" - "任务结束后提示用户任务完成,并结束任务" - doc: ./agent_test/workflows/flows.yml output: - doc: ./agent_test/testcase/TC_{{秒级时间戳}}.csv
三、utils目录下的脚本
csv_to_xlsx.py
import pandas as pd import os import sys def convert_csv_to_xlsx(): """将testcase目录下的所有CSV文件转换为XLSX格式,并删除原CSV文件""" # 设置控制台输出编码为utf-8 sys.stdout.reconfigure(encoding='utf-8') testcase_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'testcase') # 确保testcase目录存在 if not os.path.exists(testcase_dir): print(f"目录不存在: {testcase_dir}") return # 遍历testcase目录下的所有csv文件 for filename in os.listdir(testcase_dir): if filename.endswith('.csv'): csv_path = os.path.join(testcase_dir, filename) xlsx_path = os.path.join(testcase_dir, filename.replace('.csv', '.xlsx')) try: # 读取CSV文件 df = pd.read_csv(csv_path, encoding='utf-8') # 保存为XLSX文件 df.to_excel(xlsx_path, index=False) print(f"已将 {filename} 转换为XLSX格式") # 删除原CSV文件 os.remove(csv_path) print(f"已删除原CSV文件: {filename}") except Exception as e: print(f"处理 {filename} 时出错: {str(e)}") if __name__ == '__main__': convert_csv_to_xlsx()
init_environment.py
#!/usr/bin/env python # -*- coding: utf-8 -*- import os import sys import shutil import platform from pathlib import Path def get_windsurf_config_path(): """ 获取不同系统下 Windsurf 的配置目录路径 """ # 获取用户主目录 home = os.path.expanduser("~") # Windows: C:\Users\<username>\.codeium\windsurf\memories # Linux: ~/.codeium/windsurf/memories # macOS: ~/.codeium/windsurf/memories system = platform.system().lower() if system == "windows": config_path = os.path.join(home, ".codeium", "windsurf", "memories") elif system in ["linux", "darwin"]: # darwin 是 macOS 的系统名 config_path = os.path.join(home, ".codeium", "windsurf", "memories") else: raise Exception(f"不支持的操作系统: {system}") return config_path def ensure_directories(): """ 确保必要的目录存在,如果markdown目录存在则清空 """ try: # 获取当前脚本所在目录的上级目录(项目根目录) root_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 需要确保存在的目录 required_dirs = ['markdown', 'testcase', 'xmind'] for dir_name in required_dirs: # 使用绝对路径 dir_path = Path(os.path.join(root_dir, dir_name)) # 如果是markdown目录且存在,清空它 if dir_name == 'markdown' and dir_path.exists(): shutil.rmtree(dir_path) dir_path.mkdir() print(f"已清空并重新创建目录: {dir_path}") # 如果目录不存在,创建它 elif not dir_path.exists(): dir_path.mkdir() print(f"已创建目录: {dir_path}") return True except Exception as e: print(f"初始化目录时出错: {str(e)}") return False def init_global_rules(): """ 初始化全局AI规则 """ try: # 获取当前脚本所在目录的上级目录 current_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 使用绝对路径读取global_rules.md文件 rules_file = os.path.join(current_dir, 'global_rules.md') with open(rules_file, 'r', encoding='utf-8') as f: rules_content = f.read() try: # 获取 Windsurf 配置目录路径 config_path = get_windsurf_config_path() # 确保目录存在 os.makedirs(config_path, exist_ok=True) # 构建全局规则文件的完整路径 rules_file = os.path.join(config_path, "global_rules.md") # 写入全局规则 with open(rules_file, 'w', encoding='utf-8') as f: f.write(rules_content) print(f"已初始化全局AI规则到: {rules_file}") return True except Exception as e: print(f"写入全局规则文件时出错: {str(e)}") return False except Exception as e: print(f"初始化全局AI规则时出错: {str(e)}") return False def initialize_environment(): """ 初始化环境:创建必要目录并清理markdown目录,初始化全局AI规则 """ try: # 确保必要的目录存在 if not ensure_directories(): return False # 初始化全局AI规则 if not init_global_rules(): return False print("环境初始化完成") return True except Exception as e: print(f"初始化环境时出错: {str(e)}") return False if __name__ == "__main__": # 设置控制台输出编码为UTF-8 if sys.platform == 'win32': sys.stdout.reconfigure(encoding='utf-8') success = initialize_environment() sys.exit(0 if success else 1)
xmind_to_md.py
#!/usr/bin/env python # -*- coding: utf-8 -*- import os import sys import xmindparser import datetime # 设置默认编码为utf-8 if sys.version_info[0] == 3: sys.stdout.reconfigure(encoding='utf-8') class XMindToMarkdown: def __init__(self): self.current_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) self.xmind_dir = os.path.join(self.current_dir, 'xmind') self.markdown_dir = os.path.join(self.current_dir, 'markdown') def convert_to_markdown(self, xmind_file): """ 将XMind文件转换为Markdown格式 :param xmind_file: XMind文件名 :return: 转换后的Markdown内容 """ xmind_path = os.path.join(self.xmind_dir, xmind_file) if not os.path.exists(xmind_path): raise FileNotFoundError(f"XMind文件不存在: {xmind_path}") # 解析XMind文件 xmind_content = xmindparser.xmind_to_dict(xmind_path) if not xmind_content or not xmind_content[0].get('topic'): raise ValueError("XMind文件格式错误或内容为空") markdown_content = [] root_topic = xmind_content[0]['topic'] # 添加标题 markdown_content.append(f"# {root_topic.get('title', '需求文档')}\n") # 添加生成时间 current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") markdown_content.append(f"生成时间:{current_time}\n") # 处理子主题 if 'topics' in root_topic: self._process_topics(root_topic['topics'], markdown_content, level=1) return '\n'.join(markdown_content) def _process_topics(self, topics, markdown_content, level): """ 递归处理XMind主题 :param topics: 主题列表 :param markdown_content: Markdown内容列表 :param level: 当前层级 """ for topic in topics: # 添加标题 title = topic.get('title', '') markdown_content.append(f"{'#' * (level + 1)} {title}\n") # 处理备注 if 'note' in topic: note = topic['note'].strip() if note: markdown_content.append(f"{note}\n") # 处理子主题 if 'topics' in topic: self._process_topics(topic['topics'], markdown_content, level + 1) def convert_all_xminds(self): """ 转换xmind目录下的所有XMind文件为Markdown格式,并保存到markdown目录 """ # 确保xmind目录存在 if not os.path.exists(self.xmind_dir): os.makedirs(self.xmind_dir) print(f"创建目录: {self.xmind_dir}") return # 确保markdown目录存在 if not os.path.exists(self.markdown_dir): os.makedirs(self.markdown_dir) print(f"创建目录: {self.markdown_dir}") xmind_files = [f for f in os.listdir(self.xmind_dir) if f.endswith('.xmind')] if not xmind_files: print("没有找到XMind文件") return for xmind_file in xmind_files: try: markdown_content = self.convert_to_markdown(xmind_file) md_filename = os.path.splitext(xmind_file)[0] + '.md' md_path = os.path.join(self.markdown_dir, md_filename) with open(md_path, 'w', encoding='utf-8') as f: f.write(markdown_content) print(f"成功转换: {xmind_file} -> {md_filename}") except Exception as e: print(f"转换 {xmind_file} 失败: {str(e)}") if __name__ == '__main__': converter = XMindToMarkdown() converter.convert_all_xminds()
使用方法:
1.需求分析xmind文件,存放在xmind目录下
命令:
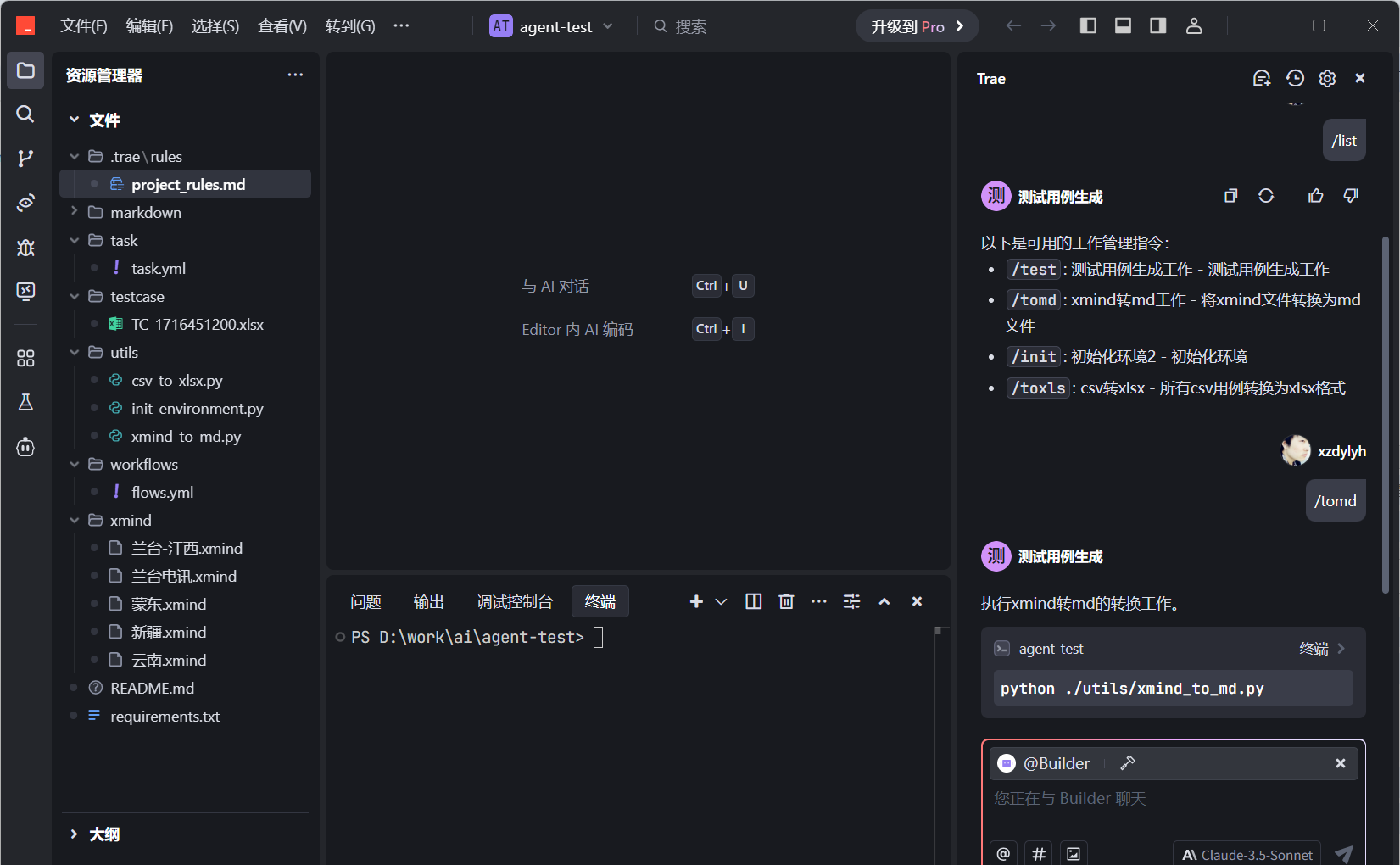
2. / 列出所有命令
3. /tomd 将xmind目录下的需求分析文件,转换为md格式;
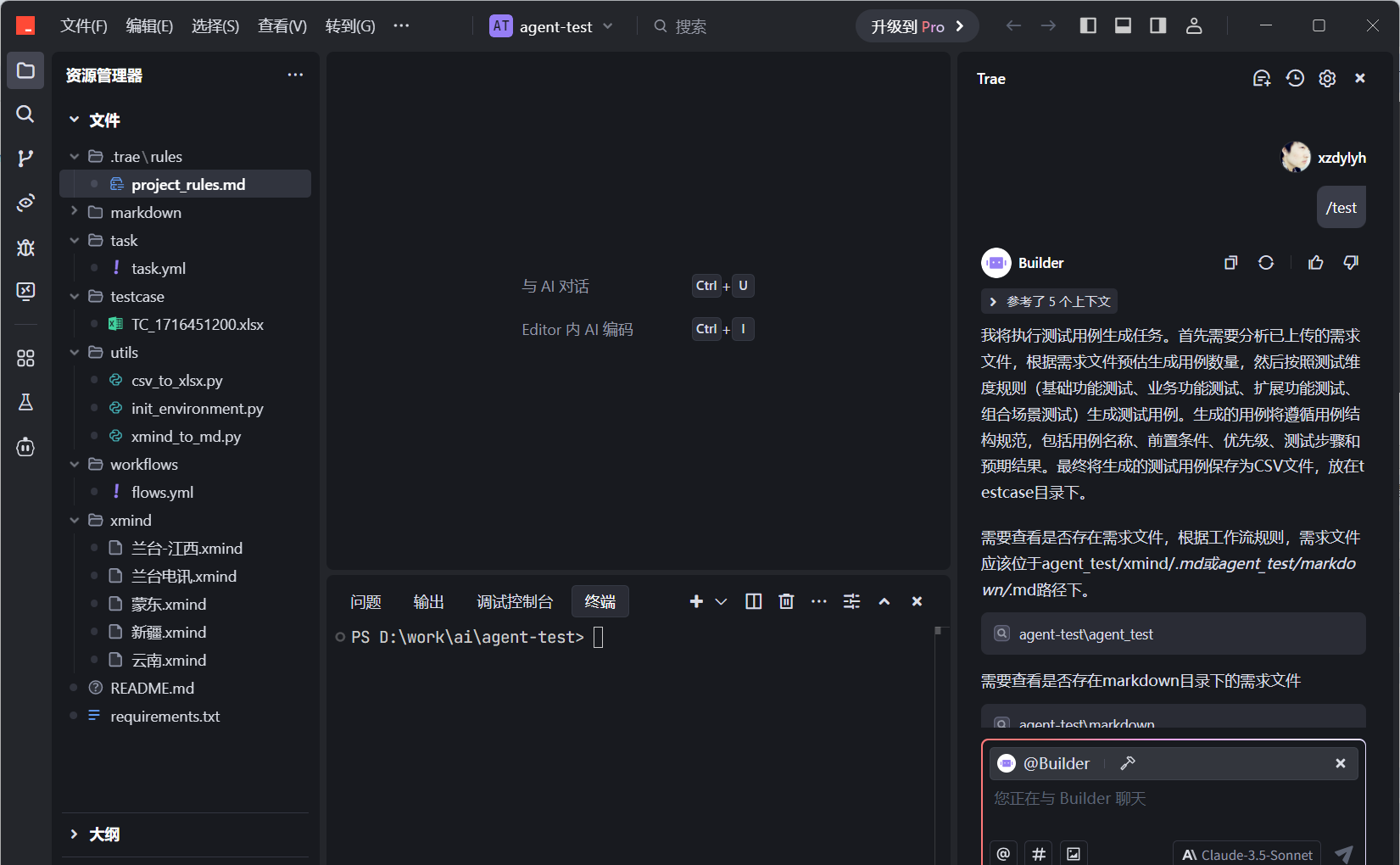
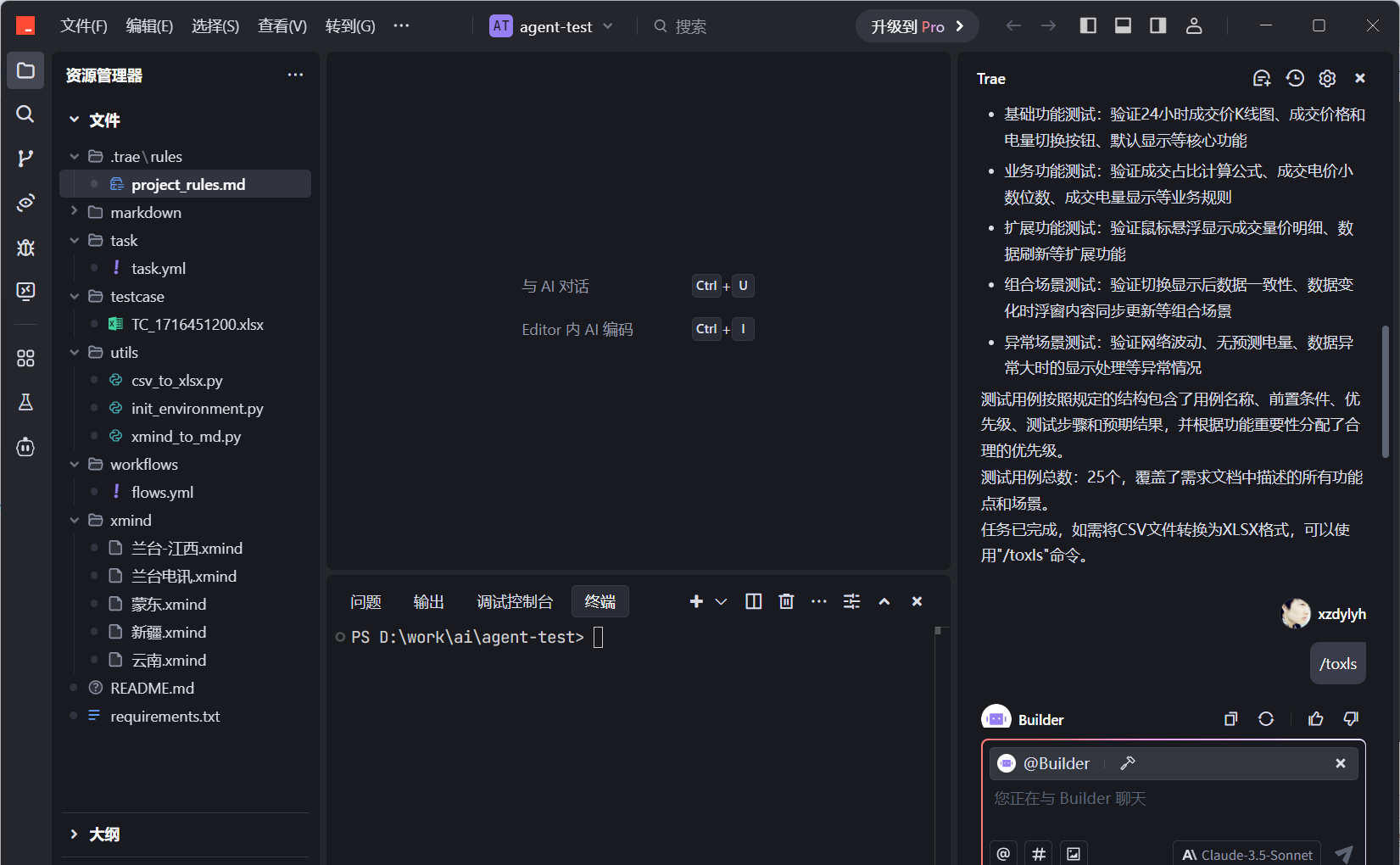
4./test进行用例生成
5./toxls 将csv转换成excel格式
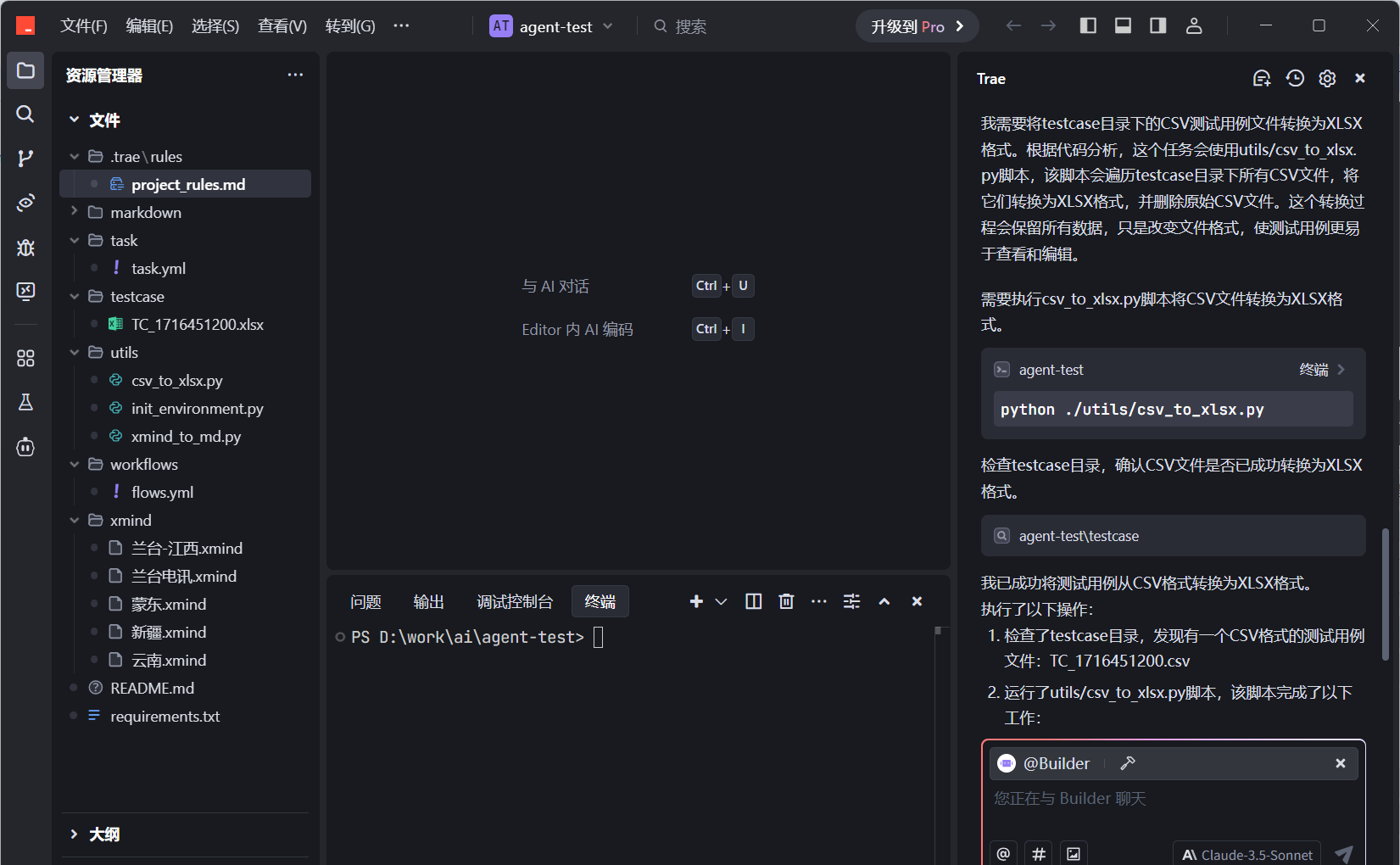
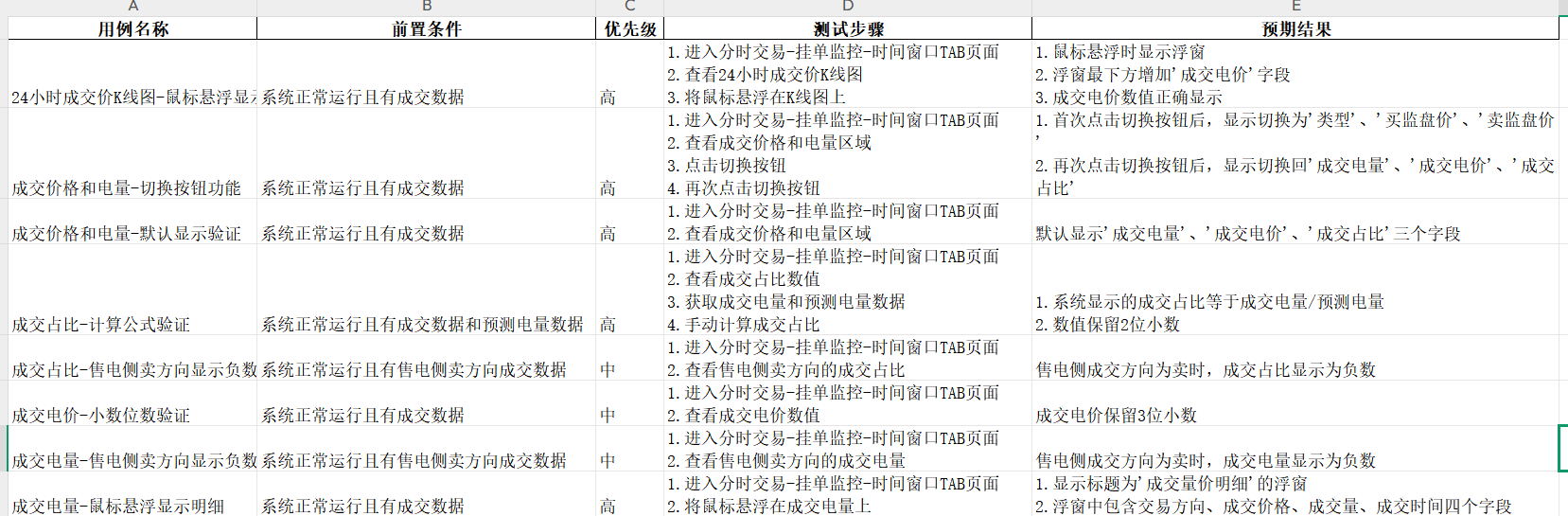
结果如下:
作 者:
天枢
出 处:
http://www.cnblogs.com/yhleng/
关于作者:专注于软件自动化测试领域。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者
直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角
【
推荐】
一下。您的鼓励是作者坚持原创和持续写作的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号