
4.19团队和个人第七次冲刺
团队博客
整个项目预期的任务量:30h 已用20h
任务看板照片

团队照片

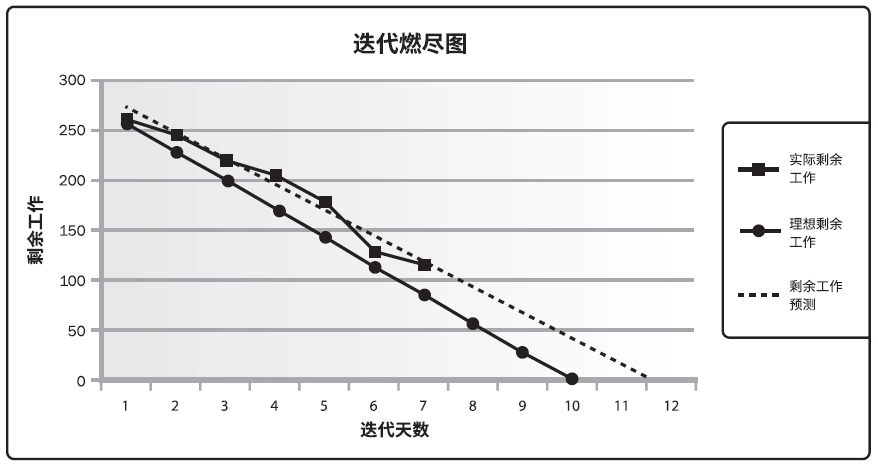
燃尽图
4.产品状态
完成了关键字提取
个人冲刺
昨天进行了pdf识别和录入,今天进行识别之后的文字进行提取
package com.itheima.web; import com.itheima.pojo.PDFReader; import com.itheima.pojo.Resume; import com.itheima.pojo.User; import com.itheima.service.UserService; import org.apache.pdfbox.io.IOUtils; import javax.servlet.*; import javax.servlet.http.*; import javax.servlet.annotation.*; import java.io.*; import java.net.URLDecoder; import java.util.Collection; import java.util.Iterator; @WebServlet("/TestServlet") public class TestServlet extends HttpServlet { UserService userService = new UserService(); @Override protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { HttpSession session = request.getSession(); User user = (User)session.getAttribute("user"); request.setCharacterEncoding("utf-8"); ServletInputStream inputStream = request.getInputStream(); FileOutputStream fileOutputStream=new FileOutputStream("F://"+"qiao.pdf"); IOUtils.copy(inputStream,fileOutputStream); fileOutputStream.close(); try { String s = PDFReader.readFile(); String[] all_splist = s.split("\\s+"); Resume resume = new Resume(); resume.setRid(user.getUid()); for (int i = 0; i < all_splist.length; i++) { if(all_splist[i].contains("姓名")) { resume.setName(all_splist[i+1]); } if(all_splist[i].contains("年龄")) { resume.setAge(all_splist[i+1]); } if(all_splist[i].contains("学历")) { resume.setStudy(all_splist[i+1]); } if(all_splist[i].contains("工作经验:")) { resume.setYear(all_splist[i+1]); } if(all_splist[i].contains("学校")) { resume.setSchool(all_splist[i+1]); } } userService.updateresumebyid(resume); response.getWriter().write("<h1>Success</h1>"); } catch (Exception e) { throw new RuntimeException(e); } } @Override protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { this.doGet(request, response); } }
遇到了提取的结果不是很理想的困难,但通过正则表达式以及一些字符的处理。最终解决了信息提取的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号