关于爬取b站播放排行榜的爬虫
期末作业搞个爬虫给大家看看,就是大家最爱的b站的播放排行
操作如下:
1. 页面解析
首先打开要爬取的网站:https://www.bilibili.com/v/popular/rank/all
然后右击空白页选择检查就能看到如下界面然后点击这个箭头所指图标
2. 点击箭头所指图标
然后点击需要爬取的内容就可以看到标题所在的标签和层级

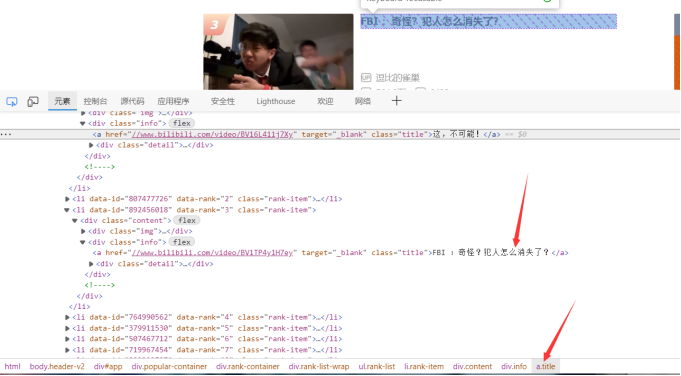
这里可以看到我们需要的标题在属性名为info的div下的a标签中

同理找到播放量和弹幕数的标签
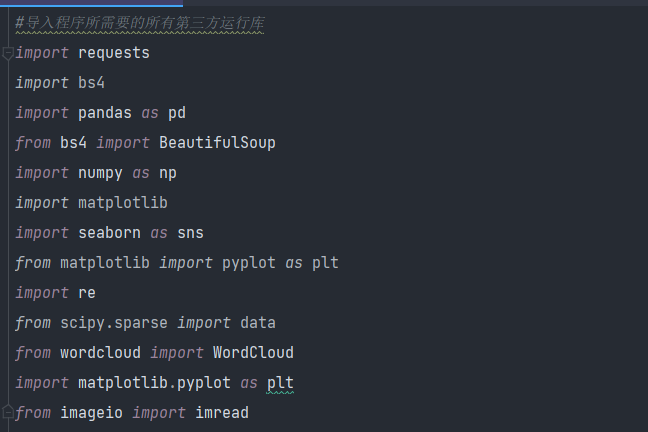
3.第三步就是编写代码了,导入第三方运行库先
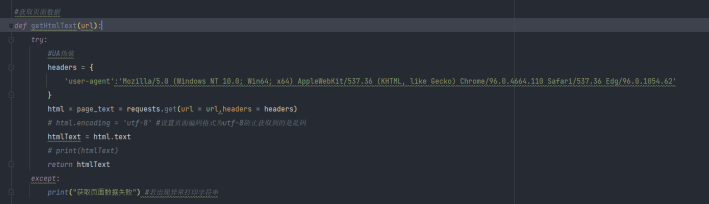
2.然后编写获取页面数据函数
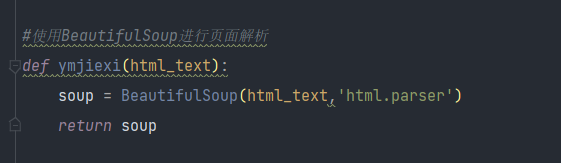
3.使用beautifulsoup工具进行页面解析
4.对需要爬取的内容进行标签定位并循环遍历标签内的文本 获取标题
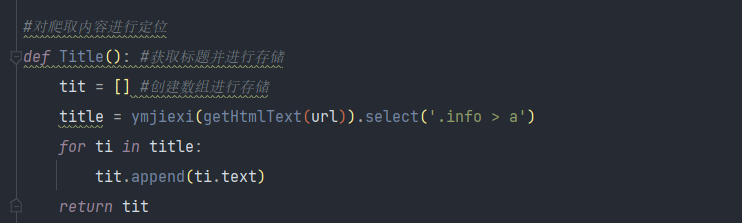
获取播放量
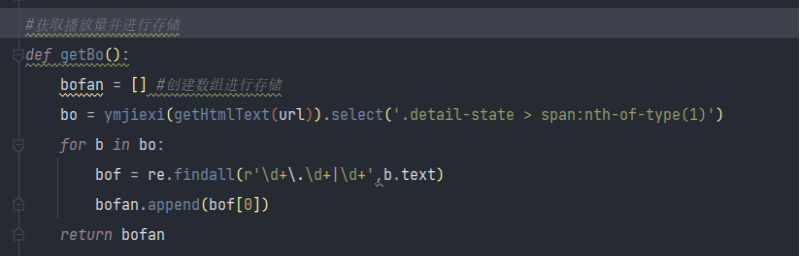
获取弹幕数
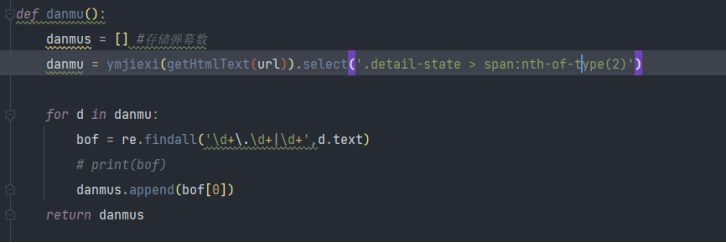
5.对获取的数据进行持久化存储
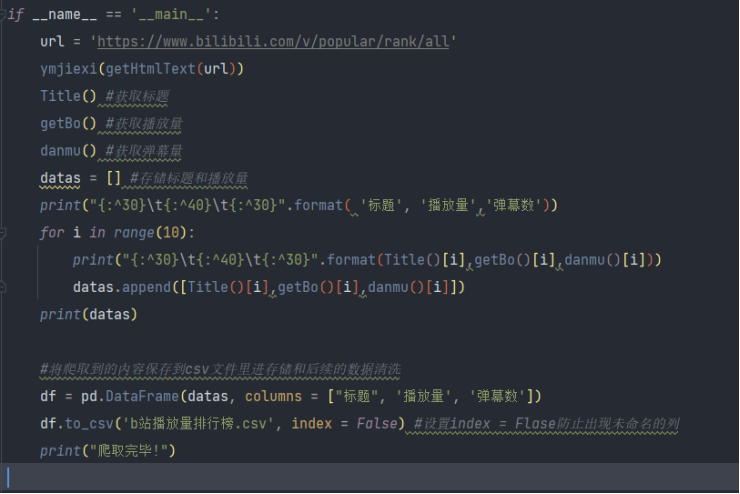
6.进行数据清洗
查找重复值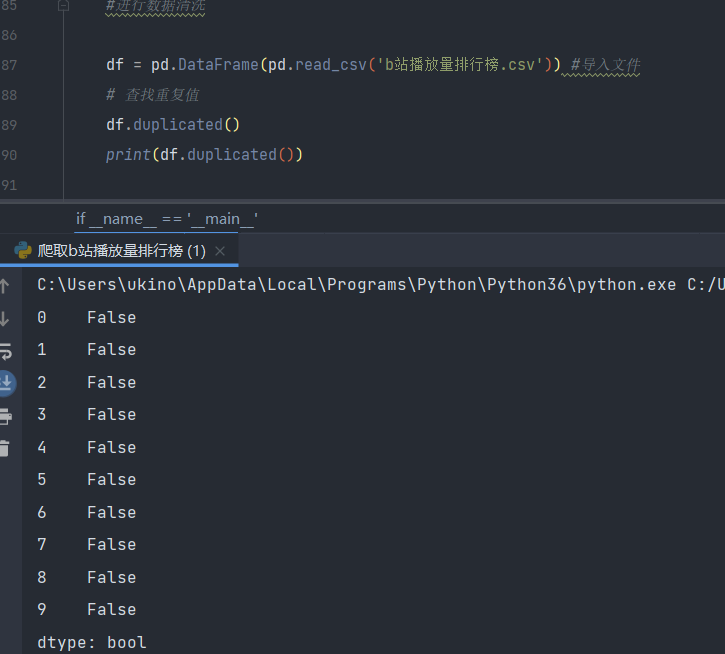
查找是否有空值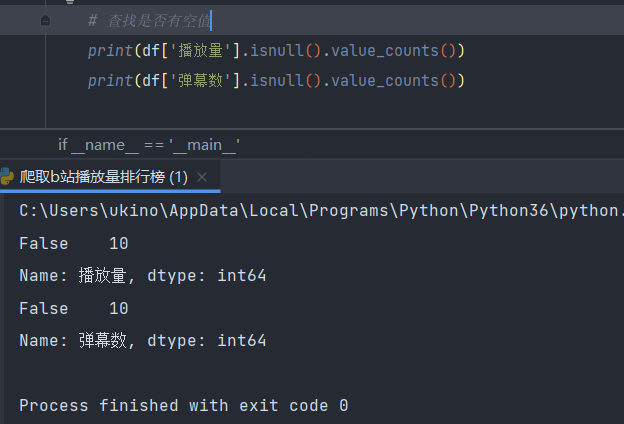
删除弹幕数小于20的标题(没啥用的)

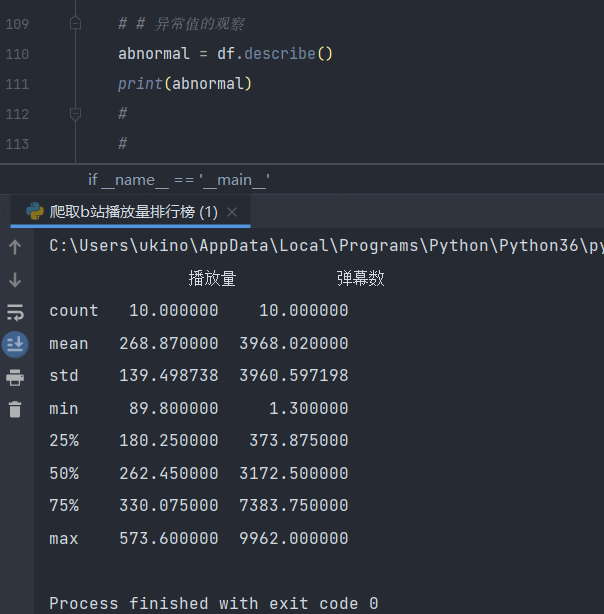
异常值观察
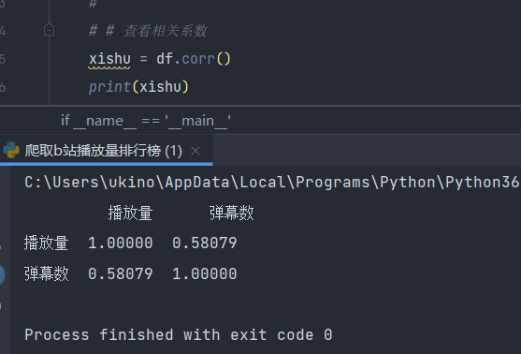
查看相关系数
7数据可视化
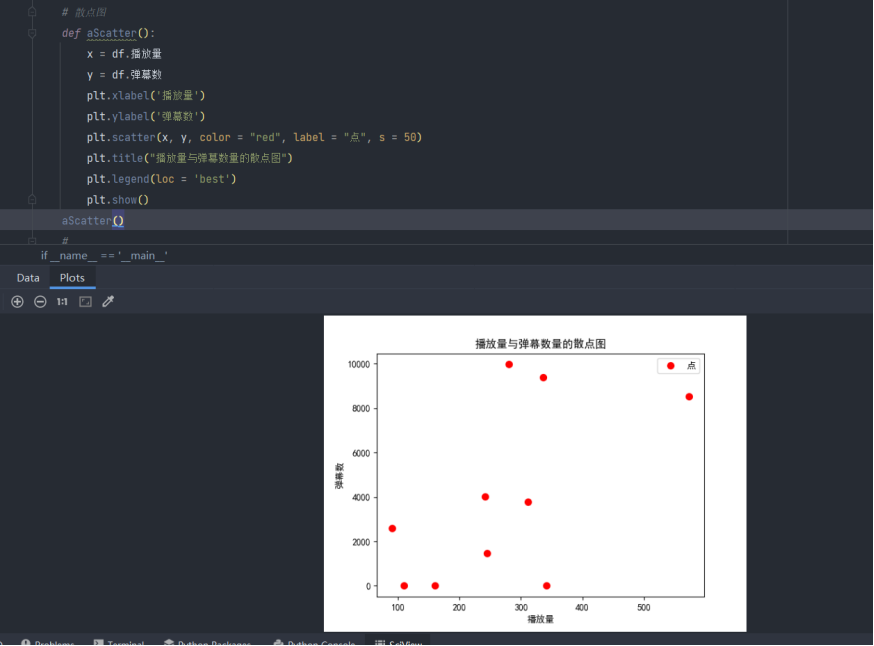
散点图
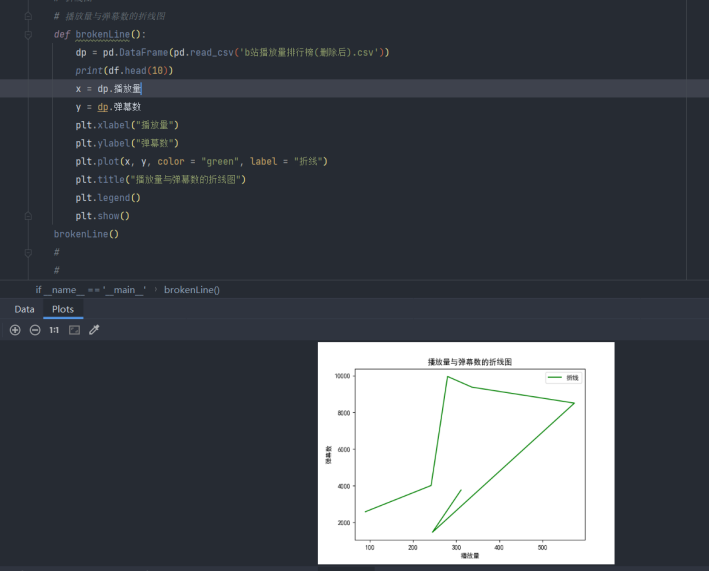
折线图
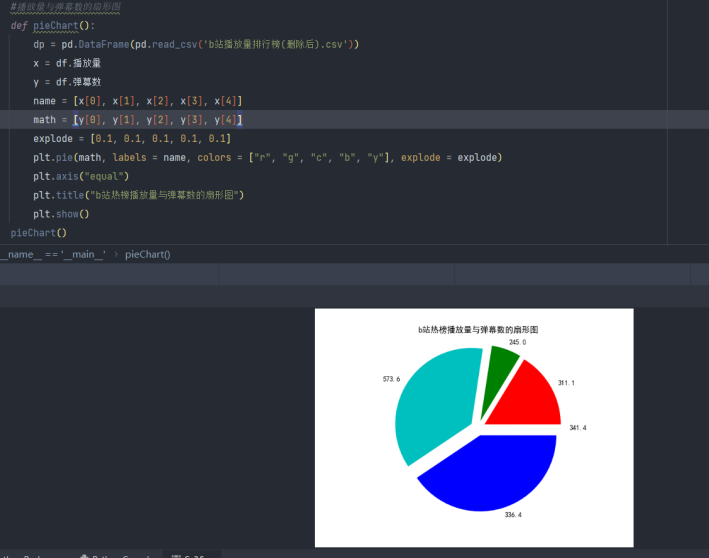
扇形图
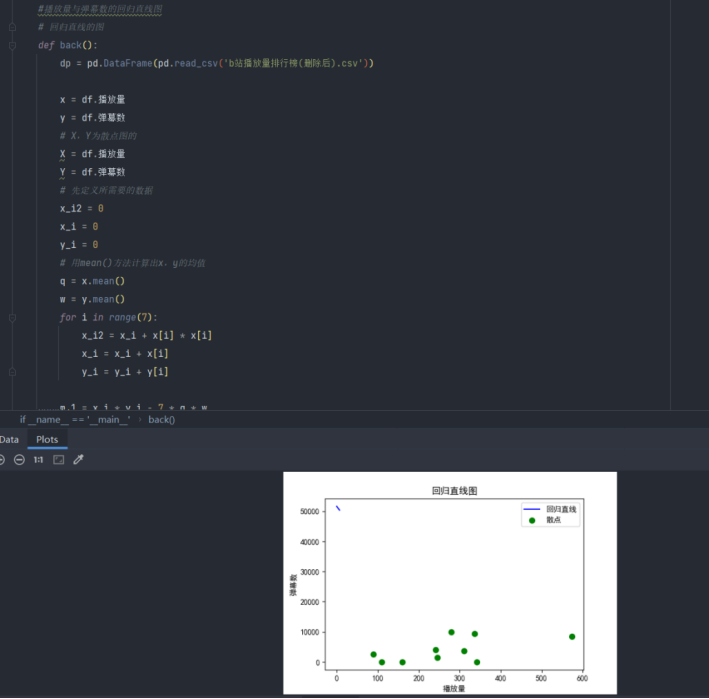
还有回归直线图和条形图

最后是线性关系图和词云图


最后的最后 给源码给大家看看
#导入程序所需要的所有第三方运行库
import requests
import bs4
import pandas as pd
from bs4 import BeautifulSoup
import numpy as np
import matplotlib
import seaborn as sns
from matplotlib import pyplot as plt
import re
from scipy.sparse import data
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imread
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签,防止画图出现中文字符不显示
plt.rcParams['font.serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
#获取页面数据
def getHtmlText(url):
try:
#UA伪装
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'
}
html = page_text = requests.get(url = url,headers = headers)
# html.encoding = 'utf-8' #设置页面编码格式为utf-8防止获取到的是乱码
htmlText = html.text
# print(htmlText)
return htmlText
except:
print("获取页面数据失败") #若出现异常打印字符串
#使用BeautifulSoup进行页面解析
def ymjiexi(html_text):
soup = BeautifulSoup(html_text,'html.parser')
return soup
# 散点图
def aScatter():
x = df.播放量
y = df.弹幕数
plt.xlabel('播放量')
plt.ylabel('弹幕数')
plt.scatter(x, y, color = "red", label = "点", s = 50)
plt.title("播放量与弹幕数量的散点图")
plt.legend(loc = 'best')
plt.show()
aScatter()
# 折线图
# 播放量与弹幕数的折线图
def brokenLine():
dp = pd.DataFrame(pd.read_csv('b站播放量排行榜(删除后).csv'))
print(df.head(10))
x = dp.播放量
y = dp.弹幕数
plt.xlabel("播放量")
plt.ylabel("弹幕数")
plt.plot(x, y, color = "green", label = "折线")
plt.title("播放量与弹幕数的折线图")
plt.legend()
plt.show()
brokenLine()
#播放量与弹幕数的扇形图
def pieChart():
dp = pd.DataFrame(pd.read_csv('b站播放量排行榜(删除后).csv'))
x = df.播放量
y = df.弹幕数
name = [x[0], x[1], x[2], x[3], x[4]]
math = [y[0], y[1], y[2], y[3], y[4]]
explode = [0.1, 0.1, 0.1, 0.1, 0.1]
plt.pie(math, labels = name, colors = ["r", "g", "c", "b", "y"], explode = explode)
plt.axis("equal")
plt.title("b站热榜播放量与弹幕数的扇形图")
plt.show()
pieChart()
#播放量与弹幕数的回归直线图
# 回归直线的图
def back():
dp = pd.DataFrame(pd.read_csv('b站播放量排行榜(删除后).csv'))
x = df.播放量
y = df.弹幕数
# X,Y为散点图的
X = df.播放量
Y = df.弹幕数
# 先定义所需要的数据
x_i2 = 0
x_i = 0
y_i = 0
# 用mean()方法计算出x,y的均值
q = x.mean()
w = y.mean()
for i in range(7):
x_i2 = x_i + x[i] * x[i]
x_i = x_i + x[i]
y_i = y_i + y[i]
m_1 = x_i * y_i - 7 * q * w
m_2 = x_i2 - 7 * q * q
k = m_1 / m_2
# 截距
b = w - q * k
x = np.linspace(0, 7)
y = k * x + b
print("斜率k=", k, "截距b=", b)
plt.figure(figsize = (6, 4))
plt.xlabel('播放量')
plt.ylabel('弹幕数')
plt.scatter(X, Y, color = "green", label = "散点", linewidth = 2)
plt.plot(x, y, color = "blue", label = "回归直线")
plt.title("回归直线图")
plt.legend()
plt.show()
back()
#对爬取内容进行定位
def Title(): #获取标题并进行存储
tit = [] #创建数组进行存储
title = ymjiexi(getHtmlText(url)).select('.info > a')
for ti in title:
tit.append(ti.text)
return tit
#获取播放量并进行存储
def getBo():
bofan = [] #创建数组进行存储
bo = ymjiexi(getHtmlText(url)).select('.detail-state > span:nth-of-type(1)')
for b in bo:
bof = re.findall(r'\d+\.\d+|\d+',b.text)
bofan.append(bof[0])
return bofan
def danmu():
danmus = [] #存储弹幕数
danmu = ymjiexi(getHtmlText(url)).select('.detail-state > span:nth-of-type(2)')
for d in danmu:
bof = re.findall('\d+\.\d+|\d+',d.text)
# print(bof)
danmus.append(bof[0])
return danmus
if __name__ == '__main__':
url = 'https://www.bilibili.com/v/popular/rank/all'
ymjiexi(getHtmlText(url))
Title() #获取标题
getBo() #获取播放量
danmu() #获取弹幕量
datas = [] #存储标题和播放量
print("{:^30}\t{:^40}\t{:^30}".format( '标题', '播放量','弹幕数'))
for i in range(10):
print("{:^30}\t{:^40}\t{:^30}".format(Title()[i],getBo()[i],danmu()[i]))
datas.append([Title()[i],getBo()[i],danmu()[i]])
print(datas)
#将爬取到的内容保存到csv文件里进存储和后续的数据清洗
df = pd.DataFrame(datas, columns = ["标题", '播放量', '弹幕数'])
df.to_csv('b站播放量排行榜.csv', index = False) #设置index = Flase防止出现未命名的列
print("爬取完毕!")
#进行数据清洗
df = pd.DataFrame(pd.read_csv('b站播放量排行榜.csv')) #导入文件
# 查找重复值
df.duplicated()
print(df.duplicated())
# 删除无效行
df.drop('标题',axis = 1,inplace = True)
print(df.head(10))
# 查找是否有空值
print(df['标题'].isnull().value_counts())
print(df['热度'].isnull().value_counts())
# 删除弹幕数量小于20的标题
def drop():
drop = df.drop(index=(df.loc[(df['弹幕数']<20)].index))
print(drop)
drop.to_csv('b站播放量排行榜(删除后).csv', index = False)
print("保存成功")
drop()
# 异常值的观察
abnormal = df.describe()
print(abnormal)
# 查看相关系数
xishu = df.corr()
print(xishu)
#绘制条形图
def bar():
df = pd.DataFrame(pd.read_csv('b站播放量排行榜.csv'))
x = df.播放量
y = df.弹幕数
plt.xlabel('播放量')
plt.ylabel('弹幕数')
plt.bar(x,y,color='red')
plt.title("播放量与弹幕数的条形图")
plt.show()
bar()
# 线性关系图
def line():
df = pd.DataFrame(pd.read_csv('b站播放量排行榜.csv'))
sns.lmplot(x = "播放量", y = "弹幕数", data = df)
plt.show()
line()
#读取b站播放量排行榜.csv将其中的标题名称写到txt文本中
text = pd.read_csv("b站播放量排行榜.csv", encoding='utf-8')
with open("标题.txt",'a+', encoding='utf-8') as f:
for title in text.标题:
f.write((str(title)+'\n'))
#读取文本
text=open('标题.txt',encoding='utf-8').read()
#词云的背景图片
photo=imread('小鸡.jpg')
Cyun=WordCloud(
background_color = "white",
mask = photo,
width=1000,
repeat=True,
font_path=r'simfang.ttf',
height=1600).generate(text)
plt.imshow(Cyun)
plt.axis("off")
plt.show()
#保存图片
Cyun.to_file("标题词云.jpg")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号