redis1.0源码日志(2):数据结构
概述
1.0版本的Redis具有以下几种数据结构:
- sds:动态扩容的字符串(A C dynamic strings library)。
- zipmap:字符串映射(String Map data structure optimized for size)。
- adlist:双向链表(A generic doubly linked list implementation)。
- dict:哈希表(Hash Tables Implementation)。
sds
typedef char *sds;
// 用来存放sds的关键信息
struct sdshdr {
long len; // sds长度, 总大小=len+free
long free; // 可用空间
char buf[]; // 指向sds, 不占用内存
};
sds的内存布局如下,每次创建一个新的sds时,都会分配原始字符串长度+1('\0'的长度)+sizeof(struct sdshdr)的长度的大小的内存空间。
这里有个细节要注意一下,在结构体中char buf[]是不占用内存空间的。但是这种无固定长度的数组只能放在结构体最后。
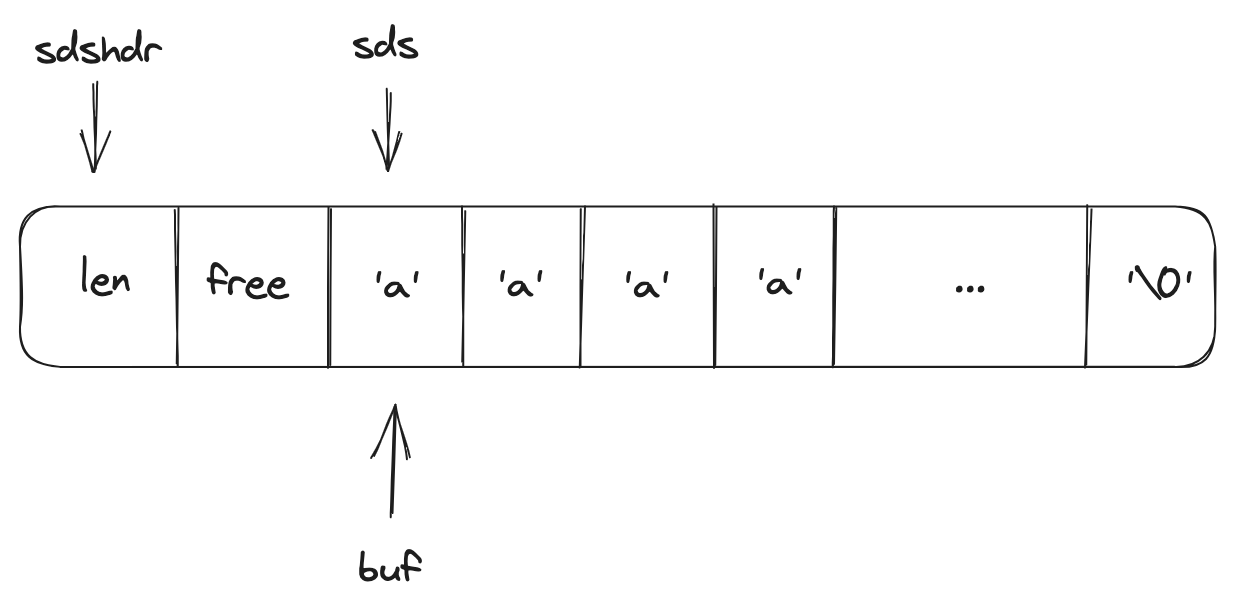
创建sds的方法:
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
// 划分一块内存区域, 头`sizeof(struct hdr)`个字节存放sdshdr, 后面连续的空间用来存放sds
sh = zmalloc(sizeof(struct sdshdr) + initlen + 1);
if (sh == NULL) return NULL;
sh->len = initlen;
sh->free = 0;
if (initlen) {
if (init) memcpy(sh->buf, init, initlen);
else memset(sh->buf, 0, initlen);
}
sh->buf[initlen] = '\0';
return (char*)sh->buf;
}
如何通过sds获取到sdshdr?
struct sdshdr *sh = (void*) (sds-(sizeof(struct sdshdr)));
字符串是二进制安全的,不同与glibc中strlen要计算'\0'在字符串的出现位置来计算长度,sds是通过sdshdr中len来记录字符串长度。
扩容机制:在所需长度的基础上乘以2。
static sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh;
size_t free = sdsavail(s);
size_t len, newlen;
if (free >= addlen) return s;
len = sdslen(s);
sh = (void*) (s-(sizeof(struct sdshdr)));
// 原字符串长度的两倍, 而不是整个sds的两倍
newlen = (len+addlen)*2;
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1);
if (newsh == NULL) return NULL;
newsh->free = newlen - len;
return newsh->buf;
}
adlist
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned int len;
} list;
adlist的大致结构如下图所示:
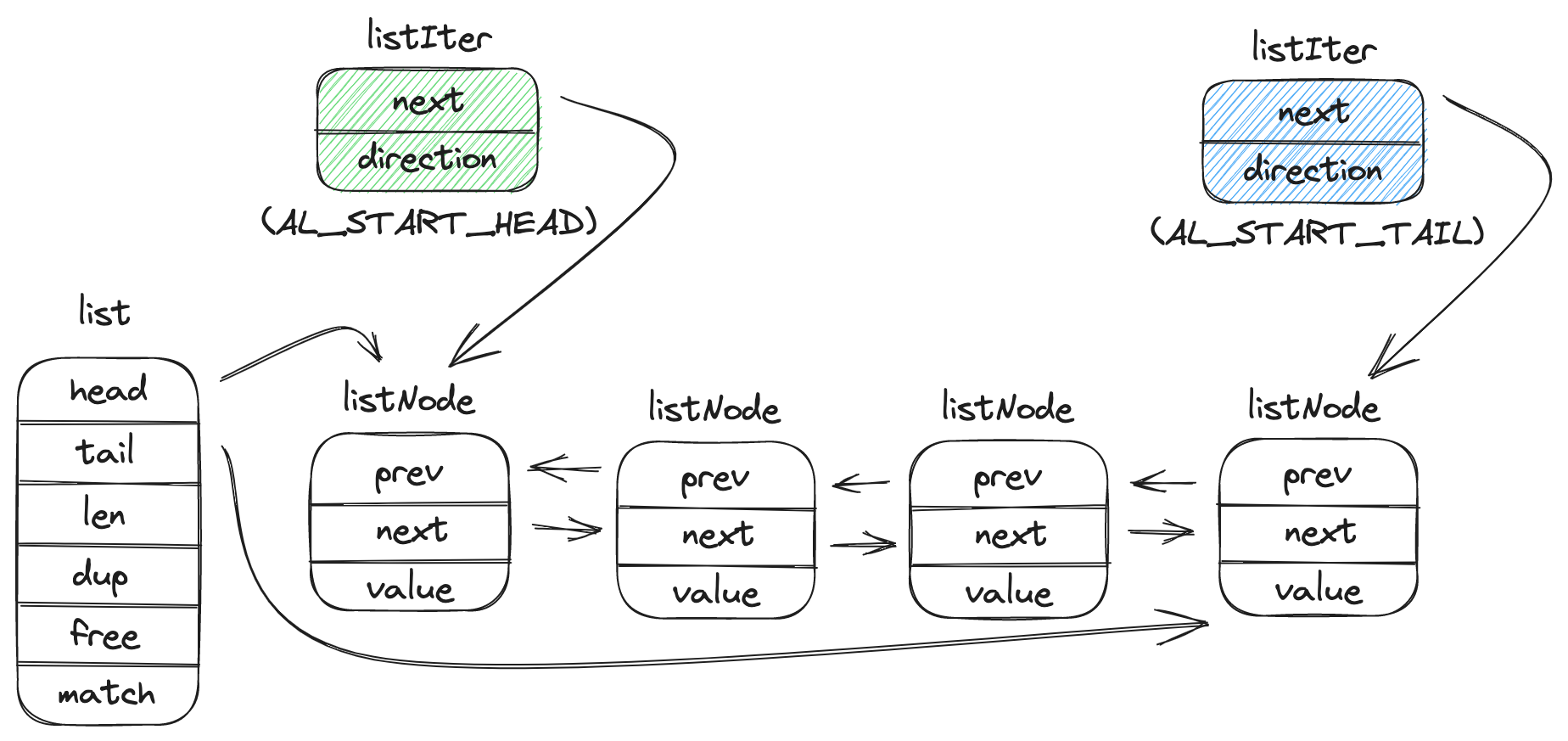
注意,adlist中listNode中的value是由用户管理,用户必须在释放list前,手动free或者挪到另一个地方。
list中的三个函数指针:dup、free、match,分别是用来:
- 复制listNode中的value
- 释放listNode中的value
- 匹配listNode中的value
zipmap
zipmap是一个压缩过的字符串映射,可以把它当成map<string, string>,但实际上使用unsigned char*表示。
zipmap的长度(也就是key-value pair的数量),由1个字节或者5个字节表示。
如果zipmap的第1个字节的值小于255(
0xff),那么zipmap的长度在0(0x00) ~ 254(0xfe)之间;如果第1个字节的值大于255(0xff),那么第1个字节不表示长度,由后面4个字节(无符号整数)表示zipmap的长度。
用代码获取长度如下所示:
#define ZIPMAP_BIGLEN 254
static unsigned int zipmapDecodeLength(unsigned char *p) {
unsigned int len = *p;
if (len < ZIPMAP_BIGLEN) return len;
memcpy(&len,p+1,sizeof(unsigned int));
return len;
}
zipmap末尾用一个终结符0xff来表示。
#define ZIPMAP_END 255
unsigned char *zipmapNew(void) {
unsigned char *zm = zmalloc(2);
zm[0] = 0; /* Length */
zm[1] = ZIPMAP_END;
return zm;
}

zipmap中entry编码格式是key length + key + value length + free + value。
key和value的长度编码跟zipmap的长度编码是一致的小于255就用一个字节表示,否则就用4个字节表示(同时第一个字节用255占位)。
entry中在value length的下一个字节是用于表示value中有多少空闲空间(free),但是free最多只能用1个字节表示,最大值也就是255,如果value的空闲空间超过255就会重新调整entry的布局。
entry长度的计算代码如下:
static unsigned long zipmapRequiredLength(unsigned int klen, unsigned int vlen) {
unsigned int l;
// 1 for key length, 1 for value length, 1 for free
l = klen+vlen+3;
if (klen >= ZIPMAP_BIGLEN) l += 4;
if (vlen >= ZIPMAP_BIGLEN) l += 4;
return l;
}

优缺点:
- zipmap适合那种一旦添加就不经常变更的数据,这样压缩后的收益最大,同时数量也不能太多,不然查询时不同的匹配,时间复杂度也是
O(n)。 - zipmap插入entry后的长度大于原zipmap长度,那么会重新分配内存,如果在频繁插入的场景下会有性能问题。
zipmap这个数据结构适用于小数据量的频繁读取。
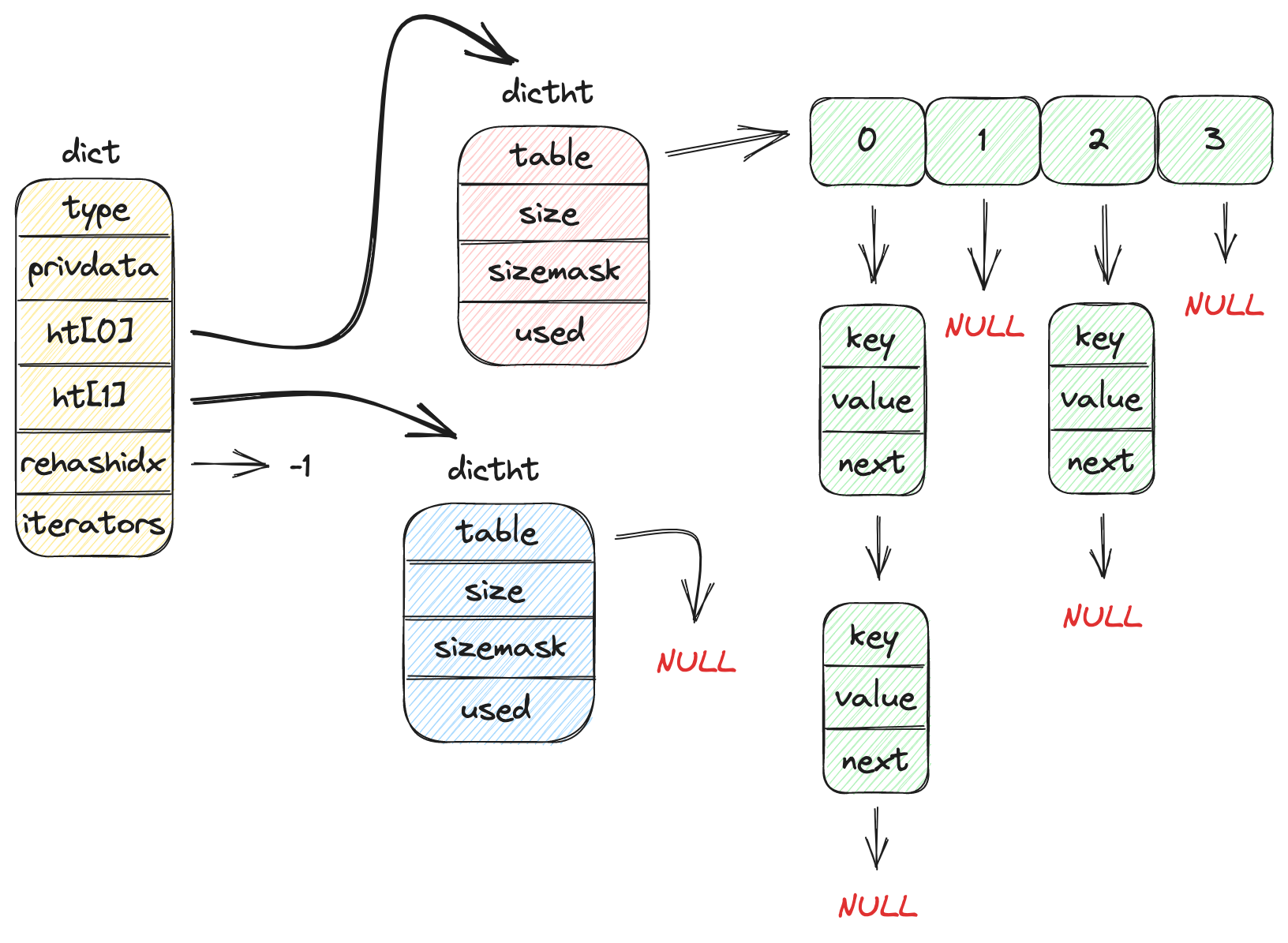
dict
dict是一个哈希表的实现,采用数组+链表(开链法)方式。同时dict可以动态扩容。并且利用结构体➕函数指针的方法表(dictType)来实现面向对象(OOP)。
typedef struct dictEntry {
void *key;
void *val;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size; // 数组长度, 一定是2的n次幂, 这样可以实现 hash & (size - 1)
unsigned long sizemask; // 取模的掩码, sizemask == size - 1
unsigned long used; // 哈希表中元素数量
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
typedef struct dictIterator {
dict *d;
int table;
int index;
dictEntry *entry, *nextEntry;
} dictIterator;
dict是对底层哈希表包装,这个结构有方法表(dictType),同时dictht数组来表示哈希表,数据的CRUD都是对ht字段进行操作,这里采用数组是为了实现一种渐进式哈希的rehash方法,同时rehashidx字段为-1表示没有在rehash,否则表示在rehash,ht[1]就作为新的哈希表,同时rehashidx不等于-1时还有另一层含义就是表示当前迁移到ht[0]的那一个下标了。当rehash完毕,就是用ht[1]替换ht[0],ht[1]称为新的ht[0],同时free掉原先ht[0]。
还有一点要注意的,渐进式哈希是在add/delete前移动ht[0]的一条链表到ht[1],而不是一个元素。
什么是rehash?
当哈希表在扩容后,原先基于哈希值%哈希数组长度的方法就会出现错误,因为哈希数组长度在哈希数组调整大小后发生了变化,因此需要对原来的元素重新对新的数组长度取模确定其在数组中的下标。这一过程就是rehash。
杂记
内存分配管理
redis的所有内存分配都在rmalloc.c中操作。
redis在这里统计了已分配的内存大小,它会在每一块分配的内存其余前添加PREFIX_SIZE大小的区域来记录这块内存大小,每次分配内存就并不是用户指定的大小,而是需分配内存大小 + PERFIX_SIZE。
分配内存就加上对应的内存大小到一个全局变量,释放内存就从PREFIX_SIZE获取这块分配内存的大小,并区域这个值。
static size_t used_memory = 0;
static int zmalloc_thread_safe = 0;
pthread_mutex_t used_memory_mutex = PTHREAD_MUTEX_INITIALIZER;
#define increment_used_memory(__n) do { \
size_t _n = (__n); \
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); \
if (zmalloc_thread_safe) { \
pthread_mutex_lock(&used_memory_mutex); \
used_memory += _n; \
pthread_mutex_unlock(&used_memory_mutex); \
} else { \
used_memory += _n; \
} \
} while(0)
#define decrement_used_memory(__n) do { \
size_t _n = (__n); \
if (_n&(sizeof(long)-1)) _n += sizeof(long)-(_n&(sizeof(long)-1)); /* 对齐 */ \
if (zmalloc_thread_safe) { \
pthread_mutex_lock(&used_memory_mutex); \
used_memory -= _n; \
pthread_mutex_unlock(&used_memory_mutex); \
} else { \
used_memory -= _n; \
} \
} while(0)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号