1、基础知识
1.1、简介
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统,常见可以用于web/nginx日志、访问日志,消息服务等。
Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
应用场景是:日志收集系统和消息系统。
官网地址:https://kafka.apache.org/
1.2、kafka vs zookeeper
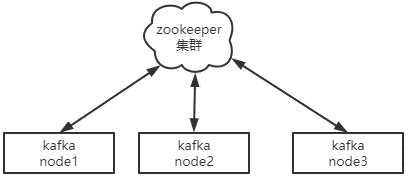
1.2.1、关系图
1.2.2、区别说明
ZooKeeper 是安装 Kafka 集群的必要组件,Kafka 通过 ZooKeeper 来实施对元数据信息的管理,包括集群、broker、主题、分区等内容。
2、原理解析
2.1、原理图
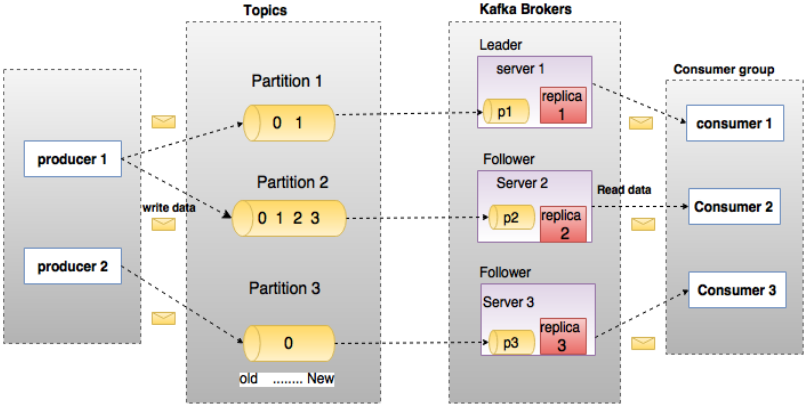
2.2、基本概念
术语 解析
broker # kafka每个节点都称为broker
leader # 所有broker中的主节点
follower # 其他的非主broker节点
topic # 存储关键字,或者理解为消息类别,可以理解为一个队列
partition # 消息最终存放的地方,归属于topic,一个topic有多个存储地方.在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
replication # 同样数据的副本,防止整体损坏,是Kafka的高可靠性的保障来源
group # 接收消息的群组
offset # 偏移量,指向开始获取消息的位置
producer # 生产消息的地方
consumer # 获取并指向消息的地方
AR # Assigned Replicas,分区中的所有副本的统称,AR = ISR + OSR-[在所有broker上存在的副本]
ISR # In Sync Replicas,所有与leader副本保持一定程度同步的副本集合,是AR的子集-[与leader同步数据成功的副本]
OSR # Out-of-Sync Replied,所有与leader副本同步滞后过多的副本集合,是AR的子集-[与leader同步数据不成功的副本]
2.3、整体效果图
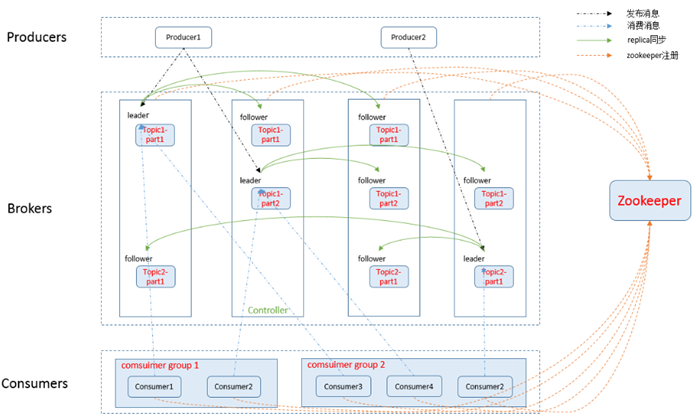
Kafka集群中包含如下几个部分:
若干Producer(任何可以产生流数据的位置)、大量broker节点、大量Consumer Group 及Zookeeper集群
作为一个消息系统,Kafka遵循了传统的消息处理流程:
Producer向broker push消息
Consumer从broker pull消息
Kafka通过Zookeeper管理集群
- 在所有broker节点中选举leader角色节点。
- Consumer Group发生变化时进行rebalance。
Producer使用push模式将消息发布到broker
- 每条消费都必须指定它的Topic,为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
- Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。
- 所有消息可以均匀分布到不同的Partition里,最终实现负载均衡。
Consumer使用pull模式从broker订阅并消费消息。
- Kafka可以基于广播或单播的方式,实现Topic消息通知给消费者。
- Kafka还可以同时提供离线处理和实时处理。
1、使用Storm这种实时流处理系统对消息进行实时在线处理,
2、用Hadoop这种批处理系统进行离线处理
3、将数据实时备份到另一个数据中心只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。
2.4、通信质量
Kafka为了保证整个过程中,通信的有效性,采取了多种策略方式,主要有以下几种:
At most once 消息可能会丢,但绝不会重复传输
At least one 消息绝不会丢,但可能会重复传输
Exactly once 每条消息肯定会被传输一次且仅传输一次。
当Producer向broker发送消息时,一旦这条消息被commit,因数replication的存在,它就不会丢。
如果Producer发送数据给broker后,遇到网络问题导致通信中断,Producer无法判断消息是否commit。
为了保证Kafka确定故障,Producer生成一种类主键的标识一旦识别出来这可以实现故障时幂等性的重试多次,最终实现Exactly once。
Consumer在从broker读取消息后,有多种处理机制:
- commit操作后在Zookeeper中保存该Consumer在Partition中读取的消息的offset。
Consumer下一次再读该Partition时会从下一条开始读取。
- 不commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。
- autocommit,Consumer一旦读到数据立即自动commit。
Kafka默认保证At least once,并且允许通过设置Producer异步提交来实现At most once。而Exactly once要求与外部存储系统协作,Kafka提供的offset机制,可以非常容易得使用这种方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号