Kubernetes学习目录
1、基础知识
1.1、监控指标
在k8s的系统上包含了各种各样的指标数据,早期的k8s系统,为kubelet集成了一个CAdvsior工具可以获取kubelet所在节点上的相关指标,包括容器指标。但是CAdvsior的缺陷在于,我们仅能够获取,指定
节点上的指标信息,而无法获取集群管理的统一指标。
比如,在k8s集群中,提供了一些监控用的命令,比如top,通过它可以汇总节点上的相关统计信息。由于没有默认情况下,k8s没有提供专用的metrics接口,所以这个命令无法正常使用。
~]# kubectl top node
error: Metrics API not available
虽然k8s已经内嵌了CAdvsior,但是没有集群级别的资源对象能够汇总这些所有的指标数据,并通过相关资源对象的api接口暴露出去。
kubectl api-resources | grep metrics
1.2、指标类型
早期的k8s提供了一个专用的metrics的指标服务器heapster,用于采集所有的监控数据,只不过这个软件因为某些原因被弃用了。
其中一部分原因就是,k8s的指标分化成了两种不同的类别:
核心资源指标
- k8s系统内部默认就应用的指标
- 它通过metrics-server服务来进行采集所有kubelet的数据,进而通过/metrics接口输出数据/api/metrics.k8s.io/v1bata1该服务默认情况下,是仅仅获取指标数据,然后保存到内存中。
自定义指标
- 用户根据情况自定义的指标
- 通过专用的监控平台软件来实现,或者通过对项目接口改造,暴露相关数据
注意:
默认情况下,k8s的指标格式与prometheus的指标格式不兼容。 如果我们需要通过prometheus来监控k8s的话,需要添加适配器。
1.3、数据采集汇总
1.3.1、监控代理程序
如node_exporter,收集标准的主机指标数据,包括平均负载、CPU、Memory、Disk、Network及诸多其他维度的数据
1.3.2、kubelet
收集容器指标数据,它们也是Kubernetes“核心指标”,每个容器的相关指标数据主要有CPU利用率(user和system)及限额、文件系统读/写/限额、内存利用率及限额、网络报文发送/接收/丢弃速率等。
1.3.3、APIServer
收集API Server的性能指标数据,包括控制工作队列的性能、请求速率与延迟时长、etcd缓存工作队列及缓存性能、普通进程状态(文件描述符、内存、CPU等)、Golang状态(GC、内存和线程等)
1.3.4、etcd
收集etcd存储集群的相关指标数据,包括领导节点及领域变动速率、提交/应用/挂起/错误的提案次数、磁盘写入性能、网络与gRPC计数器等
1.3.5、kube-state-metrics
该组件用于根据Kubernetes API Server中的资源派生出多种资源指标,它们主要是资源类型相关的计数器和元数据信息,包括指定类型的对象总数、资源限额、容器状态
(ready/restart/running/terminated/waiting)以及Pod资源的标签系列等
1.4、metrics-server流程图
1.4.1、集群整体流程图
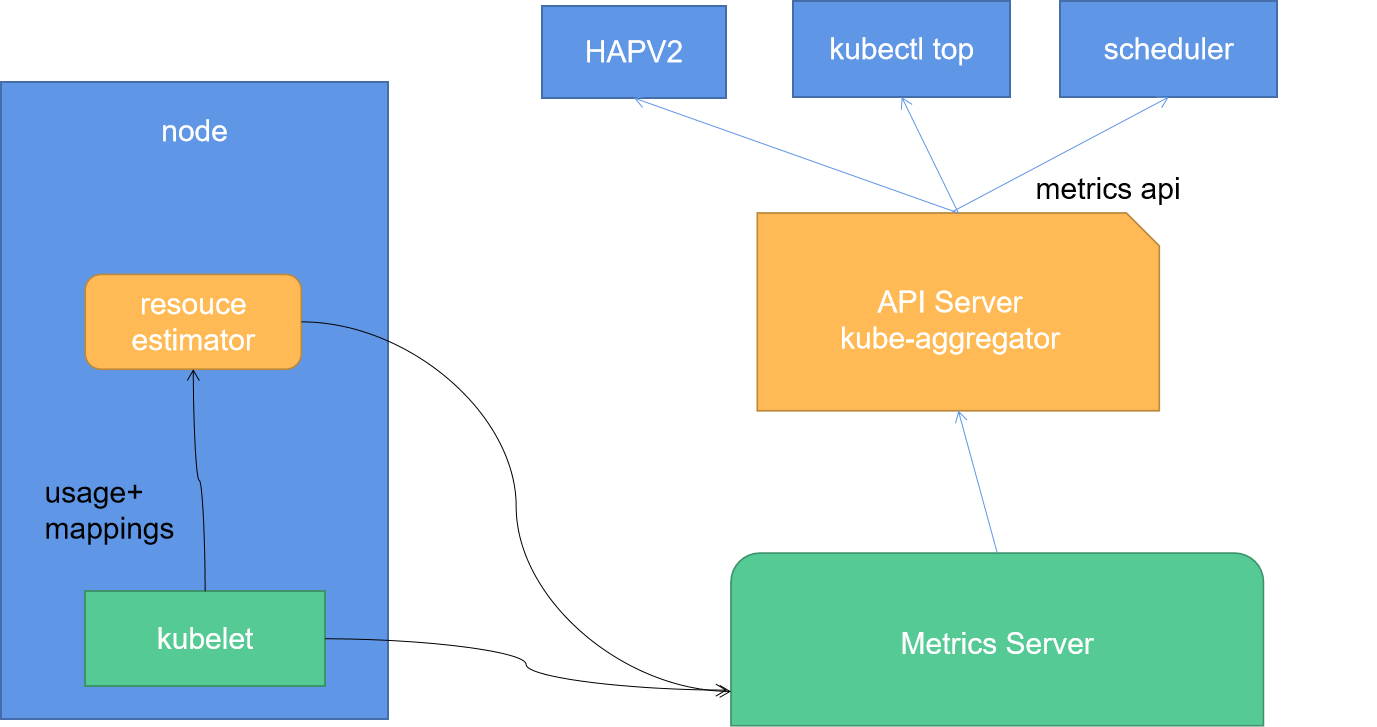
1.4.2、metrics-server与cAdvisor关系图
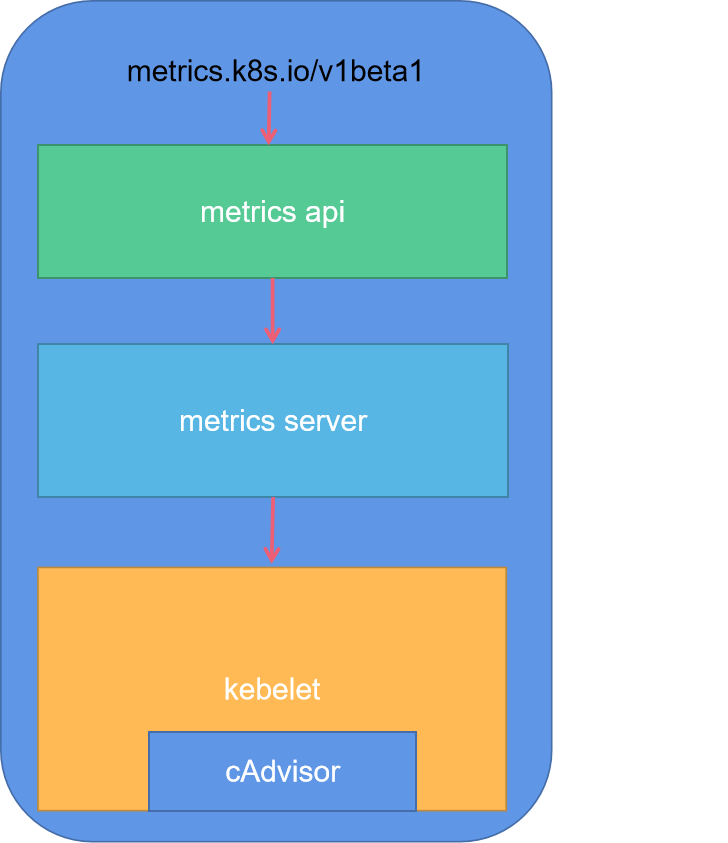
2、安装metrics-server
2.1、项目地址
https://github.com/kubernetes-sigs/metrics-server
当前版本:v0.6.3
主要用于获取资源的参数,不然HPA无法使用
2.2、下载yaml资源配置清单
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.3/components.yaml
2.3、修改配置文件
2.3.1、准备离线镜像并且修改yaml
docker pull registry.k8s.io/metrics-server/metrics-server:v0.6.3
docker tag registry.k8s.io/metrics-server/metrics-server:v0.6.3 192.168.10.33:80/k8s/hpa/metrics-server:v0.6.3
docker push 192.168.10.33:80/k8s/hpa/metrics-server:v0.6.3
]# sed -i 's#registry.k8s.io/metrics-server/metrics-server:v0.6.3#192.168.10.33:80/k8s/hpa/metrics-server:v0.6.3#g' components.yaml
]# grep 'image' components.yaml
image: 192.168.10.33:80/k8s/hpa/metrics-server:v0.6.3
imagePullPolicy: IfNotPresent
2.3.2、修改启动命令
]# vi components.yaml
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls # 增加此行参数
image: 192.168.10.33:80/k8s/hpa/metrics-server:v0.6.3
imagePullPolicy: IfNotPresent
2.4、应用资源配置清单
]# kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
2.5、查询运行状态
~]# kubectl api-resources | egrep "metr|NAME"
NAME SHORTNAMES APIVERSION NAMESPACED KIND
nodes metrics.k8s.io/v1beta1 false NodeMetrics
pods metrics.k8s.io/v1beta1 true PodMetrics
]# kubectl -n kube-system get pods -o wide | grep metrics
metrics-server-5b7dc79d77-6cfzv 1/1 Running 0 4m29s 10.244.4.124 node2 <none> <none>
]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 7d13h
metrics-server ClusterIP 10.97.76.234 <none> 443/TCP 86m
2.6、验证kubectl top是否生效
2.6.1、node
~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master1 168m 8% 1694Mi 62%
node1 84m 2% 1019Mi 27%
node2 98m 3% 1075Mi 29%
2.6.2、pod
~]# kubectl -n kube-system top pod
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-74846594dd-lf7p5 1m 28Mi
calico-node-brxqj 53m 132Mi
calico-node-ckxjg 49m 137Mi
calico-node-hgk89 39m 90Mi
coredns-c676cc86f-7k94l 3m 15Mi
coredns-c676cc86f-qbdpw 3m 20Mi
etcd-master1 28m 231Mi
kube-apiserver-master1 59m 428Mi
kube-controller-manager-master1 23m 60Mi
kube-proxy-7zxhp 1m 18Mi
kube-proxy-959kc 1m 30Mi
kube-proxy-9sv7f 1m 18Mi
kube-scheduler-master1 4m 23Mi
metrics-server-5b7dc79d77-s24rc 6m 22Mi
3、HPA-实践
3.1、基本知识
3.1.1、HPA工作机制
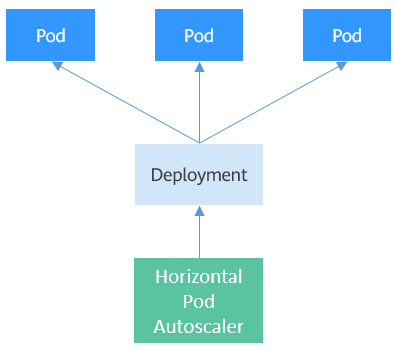
3.1.2、前提需知
1、报错信息
]# kubectl describe hpa scalar
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 12s (x2 over 27s) horizontal-pod-autoscaler failed to get cpu utilization: unable to get metrics for resource
cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
Warning FailedComputeMetricsReplicas 12s (x2 over 27s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu
resource metric value: failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not
find the requested resource (get pods.metrics.k8s.io)
2、报错信息,TARGETS显示unknown
]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
deployment-hpa Deployment/deployment-hpa <unknown>/50% 1 10 1 106m
以上原因:没有安装metrics-server导致的。
3.2、创建deployment资源
3.2.1、定义资源配置清单且应用
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-hpa
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: rs-test
template:
metadata:
labels:
app: rs-test
spec:
containers:
- name: nginxpod-test
image: 192.168.10.33:80/k8s/pod_test:v0.1
resources:
limits:
cpu: 100m
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
EOF
3.2.2、查询运行情况
]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-hpa 1/1 1 1 114m
]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deployment-hpa-88878d778-d8hn9 1/1 Running 0 114m
3.3、创建HPA资源
3.3.1、参考官方文档
3.3.2、v2版本语法-定义资源配置清单且应用
kubectl apply -f - <<EOF
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: scale
namespace: default
spec:
maxReplicas: 10
minReplicas: 1
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deployment-hpa
EOF
# 注意:autoscaling/v2beta2 在v1.23之后不可以用,1.23+需要使用autoscaling/v2
3.3.3、v1版本语法-定义资源配置清单且应用
kubectl apply -f - <<EOF
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: deployment-hpa
namespace: default
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deployment-hpa
targetCPUUtilizationPercentage: 50
EOF
3.3.4、怎么写hpa yaml
]# kubectl autoscale deployment deployment-hpa --cpu-percent=50 --min=1 --max=10 --dry-run=client -o yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: null
name: deployment-hpa
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deployment-hpa
targetCPUUtilizationPercentage: 50
status:
currentReplicas: 0
desiredReplicas: 0
3.3.5、查询运行结果
]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
scale Deployment/deployment-hpa 1%/50% 1 10 1 3m49s
3.4、压力测试pod
3.4.1、开启监控hpa
]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
scale Deployment/deployment-hpa 1%/50% 1 10 1 4m32s
3.4.2、进入pod进行压测
]# kubectl exec -it deployment-hpa-88878d778-d8hn9 -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
3.4.3、观察hpa状态
]# kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
scale Deployment/deployment-hpa 1%/50% 1 10 1 4m32s
scale Deployment/deployment-hpa 50%/50% 1 10 1 6m46s
scale Deployment/deployment-hpa 100%/50% 1 10 1 7m1s
# 此时cpu跑到50+
3.4.4、查询deployment状态
]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-hpa 2/2 2 2 140m
3.4.5、查询pod
]# kubectl get pods
NAME READY STATUS RESTARTS AGE
deployment-hpa-88878d778-d8hn9 1/1 Running 0 140m
deployment-hpa-88878d778-s5p5f 1/1 Running 0 19s
# 发现pod已经自动创建多一个出来了
3.5、自动缩容
# CPU负载下来,隔一段时间后,会自动缩容
]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
scale Deployment/deployment-hpa 1%/50% 1 10 1 13m

 浙公网安备 33010602011771号
浙公网安备 33010602011771号