

1. 概述
seatunnel 是一个数据同步平台,他可以在多种数据源之间实现数据同步,可以实现批处理同步,或者流处理同步,支持 flink,spark计算引擎。当前的版本是 2.3.12
2.部署安装
https://seatunnel.apache.org/zh-CN/download
下载最新的版本
解压后,还需要安装插件
执行命令
./bin/install-plugin.sh 2.3.12
这个下载命令执行下载时比较慢的,如何加载下载速度
我们可以在seatunnel 根目录下 增加 setting.xml 文件
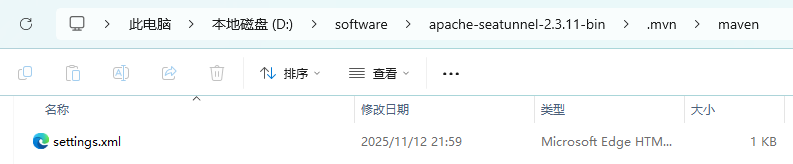
文件内容为:
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
https://maven.apache.org/xsd/settings-1.0.0.xsd">
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
</settings>
修改install-plugin.sh
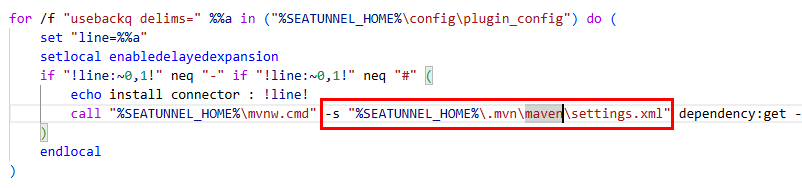
增加配置
-s "%SEATUNNEL_HOME%\.mvn\maven\settings.xml"
执行完成后会在 connectors 看到下载的连接器插件
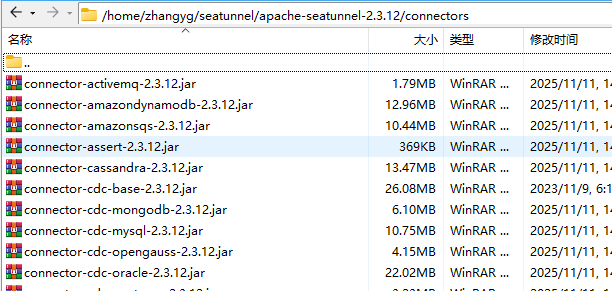
通常情况下,你不需要所有的连接器插件。你可以通过配置config/plugin_config来指定所需的插件。例如,如果你想让示例应用程序正常工作,你将需要connector-console和connector-fake插件。你可以修改plugin_config配置文件,如下所示
--connectors-v2--
connector-fake
connector-console
connector-cdc-mysql
connector-doris
connector-jdbc
connector-kafka
connector-rocketmq
--end--
3.执行seatunnel实现数据同步
seatunnel 可以实现使用 seatunnel 引擎,flink 引擎,spark引擎执行数据同步。
我们先实现本地启动实现同步,本地启动一般是直接提交计算任务,任务执行完成后,自动执行完毕。
3.1 使用seatunnel 实现 CDC同步
- 编写配置文件
使用seatunnel 实现同步时,需要编写 来源,转换,目标的配置文件,实现数据同步。具体这个文件怎么写,可以参考文档。
env {
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 10000
}
source {
MySQL-CDC {
url = "jdbc:mysql://192.168.2.10:3306/demo1"
username = "root"
password = "root"
table-names = ["demo1.demo1","demo1.demo2"]
startup.mode = "initial"
table-names-config = [
{"table": "demo1.demo1", "primaryKeys": ["id"]},
{"table": "demo1.demo2", "primaryKeys": ["id"]}
]
}
}
sink {
jdbc {
url = "jdbc:mysql://192.168.2.10:3306/demo2?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
username = "root"
password = "root"
generate_sink_sql = true
# You need to configure both database and table
database = demo2
primary_keys = ["id","id"]
field_ide = UPPERCASE
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
- 执行同步命令
./bin/seatunnel.sh --config ./config/mysqlcdc.conf -m local
执行这个命令后,由于cdc 会一直监控数据,所以这个不会退出,我们可以对源表进行操作,我们可以观察目标表的数据变化。当然如果使用cdc,数据库需要启用binlog。我们可以发现数据可以一直变化,实现表之间的数据同步。
3.2 使用 flink 计算引擎 实现 CDC同步
-
下载 flink 的 15- 18的版本
https://archive.apache.org/dist/flink/flink-1.15.4/
解压后启动 flink
./bin/start-cluster.sh -
配置flink
编辑 seatunnel-env.sh
配置 flink 安装地址:
FLINK_HOME=/seatunnel/flink/flink-1.15.4
- 发送 flink 命令
./bin/start-seatunnel-flink-15-connector-v2.sh --config ./config/mysqlcdc.conf
Execute SeaTunnel Flink Job: ${FLINK_HOME}/bin/flink run -c org.apache.seatunnel.core.starter.flink.SeaTunnelFlink /home/zhangyg/seatunnel/apache-seatunnel-2.3.12/starter/seatunnel-flink-15-starter.jar --config ./config/mysqlcdc.conf --name SeaTunnel --deploy-mode run
Job has been submitted with JobID cb3ee99c303c15f8f4f37db80379e21c
发送命令后,cdc 会一直执行,我们可以通过更改源数据表查看目标表的数据变化。
3.3 使用集群方式提交任务
3.3.1 介绍
前面是使用本地模式提交任务,当任务执行完成,seatunnel 就执行结束,我们也可以使用 集群模式部署,就是在后台启动服务。
seatunnel 有两种集群模式
./bin/seatunnel-cluster.sh -d
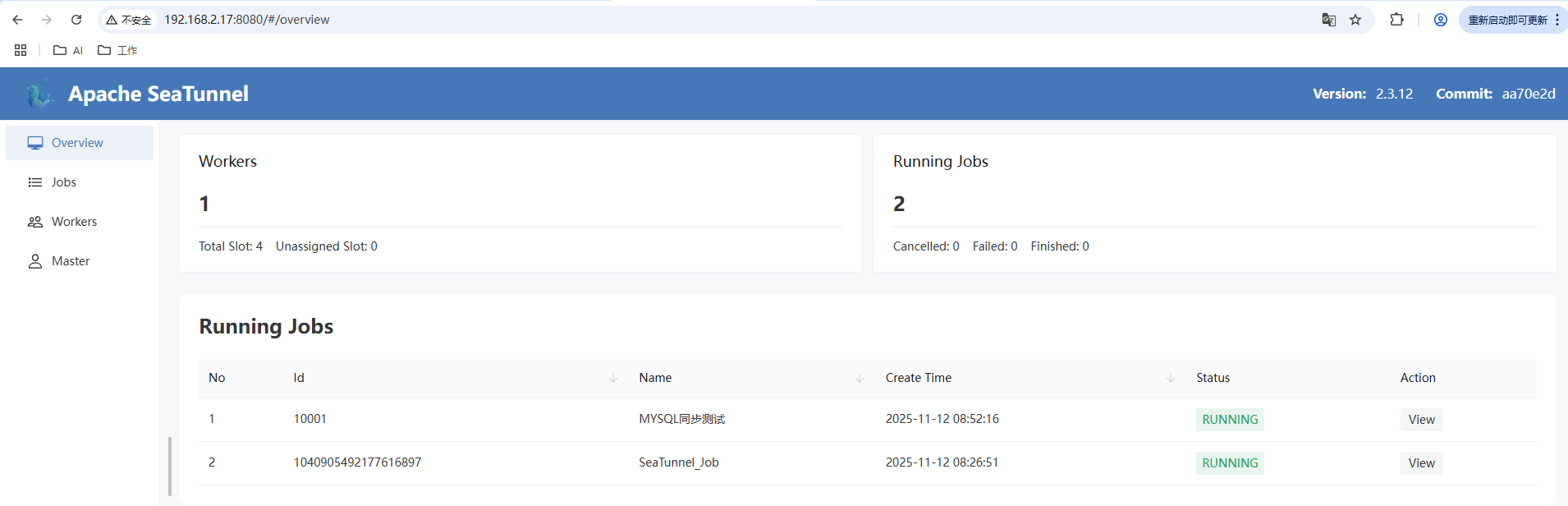
3.3.2 使用集群模式启动后访问web界面
编辑 seatunnel.yaml
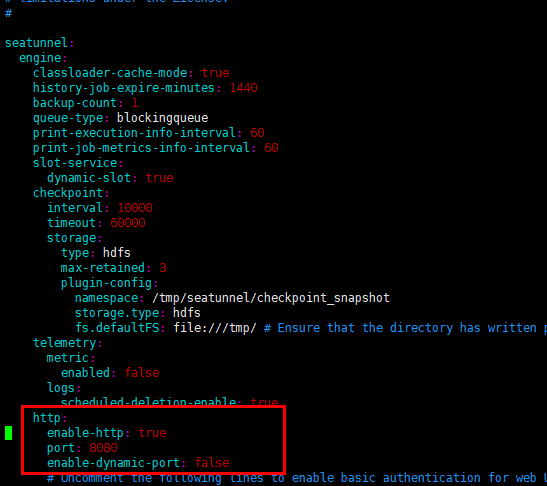
访问 web 界面
- 使用接口提交任务
seatunnel 提供了 restapi接口
https://seatunnel.apache.org/zh-CN/docs/seatunnel-engine/rest-api-v2
我们可以通过接口提交任务
接口地址
192.168.2.17:8080/submit-job?jobId=10001&jobName=MYSQL同步测试&format=hocon
请求体
env {
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 10000
}
source {
MySQL-CDC {
url = "jdbc:mysql://192.168.2.10:3306/demo1"
username = "root"
password = "root"
table-names = ["demo1.demo1","demo1.demo2"]
startup.mode = "initial"
table-names-config = [
{"table": "demo1.demo1", "primaryKeys": ["id"]},
{"table": "demo1.demo2", "primaryKeys": ["id"]}
]
}
}
sink {
jdbc {
url = "jdbc:mysql://192.168.2.10:3306/demo2?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
username = "root"
password = "root"
generate_sink_sql = true
# You need to configure both database and table
database = demo2
primary_keys = ["id","id"]
field_ide = UPPERCASE
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
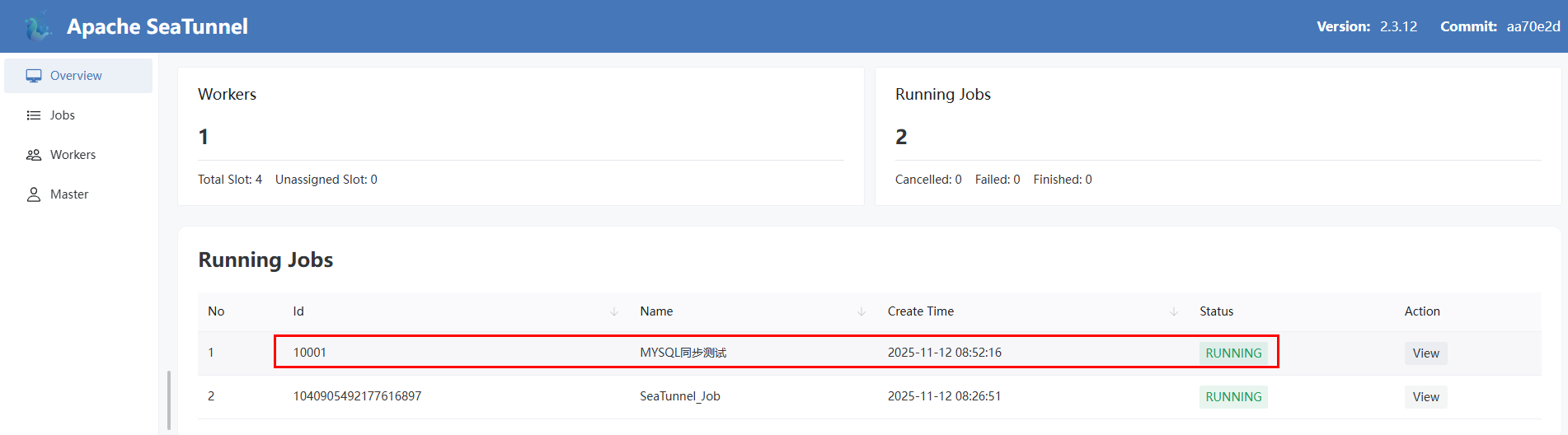
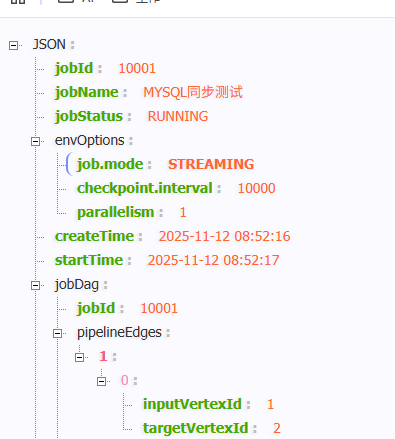
- 获取任务执行情况
http://192.168.2.17:8080/job-info/10001
- 停止任务
http://192.168.2.17:8080/stop-job
参数:
{
"jobId": 10001,
"isStopWithSavePoint": false
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号