

数据结构--跳表(Skip List) - 实践
什么?就是1. 跳表
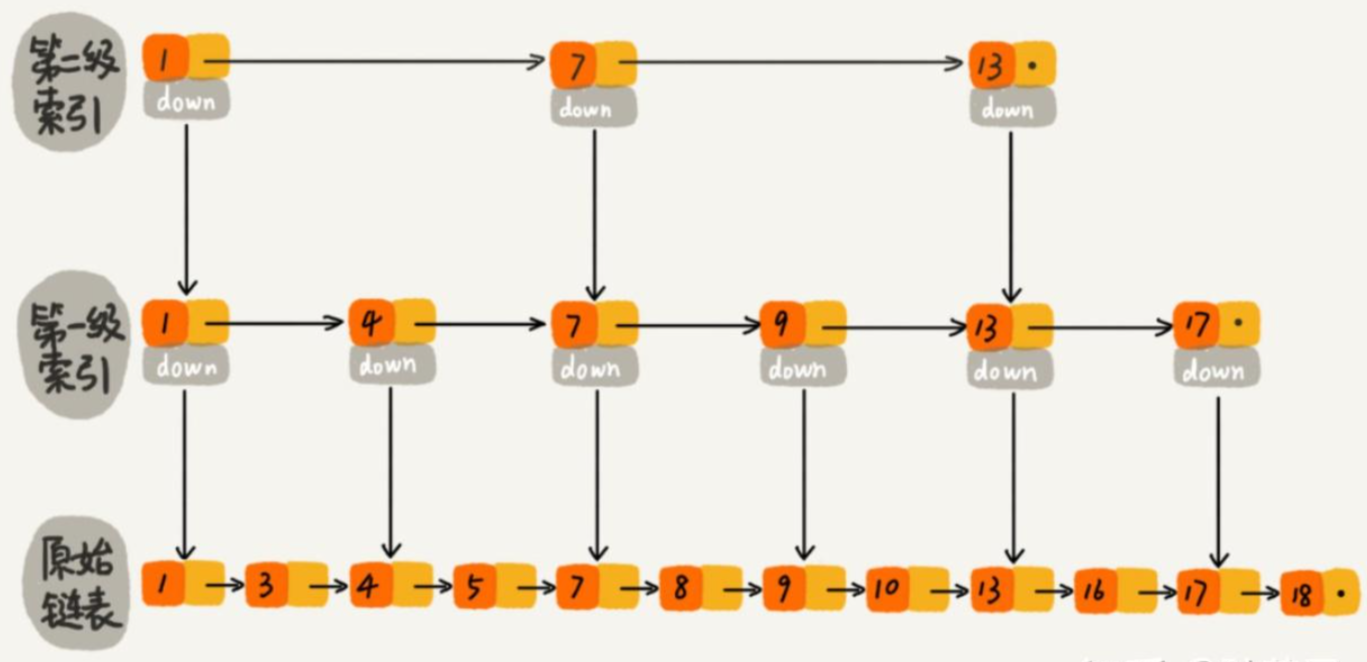
跳表是一种基于链表的数据结构,它在普通有序链表的基础上加了一些“索引层”来加快查找效率。
可以把它想象成:
一楼 → 普通链表,节点挨个排好。
二楼 → 在一楼的基础上,每隔几个节点抽一个“代表”建一条快速通道。
三楼 → 再从二楼抽节点,建更快的通道。
查找时,你先走“高速通道”(上层链表),当要找的数比当前大时往右走,比当前小或到头了就往下一层走,最终一定能到目标。
直观类比:
一本本翻,跳表相当于有“目录索引”,先高效缩小范围,再定位。就是就像在图书馆找书,普通链表2. 跳表的特点
支持快速查找、插入、删除
时间复杂度接近O(log n)(和二叉搜索树、红黑树差不多)。
结构简单,容易实现
相比红黑树,跳表代码更直观。
拥护范围查询
缘于本质是链表,向后遍历特殊方便(比树结构更好)。
3. 跳表的层级结构
第0层(最底层):普通有序链表,所有元素都在这里。
第1层:每隔 2 个元素抽一个“索引”。
第2层:每隔 4 个元素抽一个“索引”。
第3层:每隔 8 个元素抽一个“索引”。
以此类推……
每一层是下一层的“加速索引”。
4. 跳表的操作
4.1 查找
例子:找数字 8
从最高层开始,从左往右走,直到下一个比 8大 → 向下一层。
重复这个过程,直到走到最底层,找到 8。
平均复杂度:O(log n)。
4.2 插入
例子:插入 12
先按照查找方法,找到应该插入的位置(比如在 11和 13之间)。
把节点插入最底层链表。
用“随机算法”决定是否提升到上层索引。
举个例子:掷硬币,正面就往上升一层,反面就停止。
所以节点有可能只存在于底层,也可能出现在很多层。
随机策略保证了层高分布,大多数节点只在底层,少数节点充当“高速索引”。
4.3 删除
和查找类似,先找到目标节点。
然后把它从各层链表里删除即可。
5. 跳表的时间复杂度
查找:O(log n)
插入:O(log n)
删除:O(log n)
因为跳表的层高大约是就是 这log n层,每层走几步就能下去。
6. 跳表的空间复杂度
由于每层都要存索引,空间复杂度是O(n)。
但源于索引是随机的,平均情况下不会太多。
7. 跳表的应用场景
Redis 中的有序集合(Sorted Set,zset)
用跳表实现的,可以敏捷完成范围查询和排序。就是内部就
内存数据库 / 搜索引擎
用来做索引,加速查找。
8. 跳表和其他结构对比
数据结构 查找时间 插入删除 实现难度 范围查询 有序链表 O(n) O(1) 简单 简单 二叉搜索树 O(log n) O(log n) 较复杂 较复杂 红黑树 / AVL树 O(log n) O(log n) 复杂 较复杂 跳表 O(log n) O(log n) 简单 简单 跳表是 用链表实现了树的效果。
9. 小结
跳表是一个 带多级索引的有序链表。
通过“索引层”加快查找速度,平均复杂度 O(log n)。
插入和删除时,用随机算法决定是否提升层级。
应用相当广泛,特别是在Redis Sorted Set 中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号