


深入解析:2025年SEVC SCI2区,基因改造多种群粒子群算法+云环境工作流调度,深度解析+性能实测

1.摘要
云计算已成为处理大规模应用的主流模式,但在动态资源环境中,高效调度具复杂依赖关系的工作流任务并合理分配虚拟执行单元,仍面临严峻挑战。传统启发式算法在解决此类多目标优化疑问时,往往难以兼顾收敛速度与解的多样性。针对这一疑问,本文提出了一种基因改造多种群粒子群算法(GMPSO),以建立工作流调度中工期与能耗的协同优化。GMPSO依据基于适应度的子种群划分,结合遗传算法的全局搜索与粒子群优化的局部精细搜索,并设计了负载感知的初始化机制、差异化的多种群搜索策略以及自适应遗传扰动算子,从而显著提升搜索效率与解的质量。
2.架构模型

本文总体架构模型如图所示,主要由三部分组成:工作流模型、调度执行模型以及云资源模型。多目标优化模型(综合考虑工期与能耗需求)被嵌入到调度模型中,用于指导任务排序与资源分配。
资源模块由多种类型的虚拟机(VM)实例构成,每个虚拟机在同一时刻只能执行一个任务,并按队列顺序依次处理待执行任务。在资源模块中,经过排序的任务会被映射到相应的虚拟机上,最终执行结果返回至应用层。
工作流模型
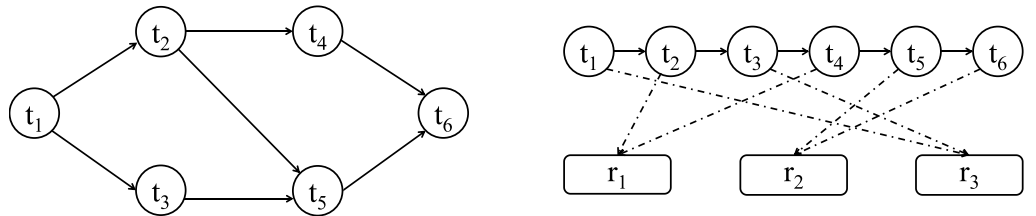
工作流被建模为有向无环图(DAG),节点表示任务,边表示依赖关系。任务需在前驱完成后才能执行,初始任务无前驱,结束任务无后继,可存在多个入口与出口。
云资源模型
云环境由不同类型虚拟机组成,每台虚拟机一次仅能执行一个任务。任务与虚拟机通过整数编码映射,不同虚拟机的计算能力与带宽决定任务执行时间与通信开销。
调度模型
工期(Makespan)
在计算工作流任务的工期时,必须考虑任务之间的依赖关系。设T s T_sTs和T f T_fTf分别表示任务的最早开始时间和最早完成时间,则任务t i t_iti在虚拟机r a r_ara上的最早开始时间T S ( t i , r a ) T_S(t_i,r_a)TS(ti,ra)定义如下:
T S ( t i , r a ) = max { T F ( t j , r a ) + T C ( t j , t i ) } T_S(t_i,r_a)=\max\{T_F(t_j,r_a)+T_C(t_j,t_i)\}TS(ti,ra)=max{TF(tj,ra)+TC(tj,ti)}
其中,t j t_jtj是t i t_iti前驱任务,T S ( t i , r a ) T_S(t_i,r_a)TS(ti,ra)等于所有前驱任务的最晚完成时间与其通信时间之和。
任务t i t_iti在r a r_ara上的最早完毕时间记为:
T F ( t i , r a ) = T S ( t i , r a ) + T E ( t i , r a ) T_F(t_i,r_a)=T_S(t_i,r_a)+T_E(t_i,r_a)TF(ti,ra)=TS(ti,ra)+TE(ti,ra)
根据前述 DAG 结构,工作流序列的工期为:
ϕ = T F ( t e x i t , r a ) \phi=T_F(t_{exit},r_a)ϕ=TF(texit,ra)
能耗(Energy Consumption)
在 IaaS 云环境中,处理器能耗通常占据整体能耗的关键部分。根据任务是否在虚拟机上运行,处理器分为运行状态和空闲状态,其能耗分别为:
E R = ∑ a = 1 m ∑ i = 1 n [ U i a ⋅ T E ( t i , r a ) ⋅ Q R a ] E_R=\sum_{a=1}^m\sum_{i=1}^n[U_{i_a}\cdot T_E(t_i,r_a)\cdot Q_{R_a}]ER=a=1∑mi=1∑n[Uia⋅TE(ti,ra)⋅QRa]
E I = ∑ a = 1 m { ϕ − ∑ i = 1 n [ U i a ∗ T E ( t i , r a ) ] ∗ Q I a } E_I=\sum_{a=1}^m\{\phi-\sum_{i=1}^n[U_{i_a}*T_E(t_i,r_a)]*Q_{I_a}\}EI=a=1∑m{ϕ−i=1∑n[Uia∗TE(ti,ra)]∗QIa}
其中,U i a U_{ia}Uia 表示任务 t i t_iti是否运行在虚拟机r a r_ara上(取值为 0 或 1);Q R a Q_{Ra}QRa 和 Q I a Q_{Ia}QIa分别表示虚拟机r a r_ara在运行和空闲状态下的能耗。总能耗:
ψ = E R + E I \psi=E_R+E_Iψ=ER+EI
3.基因改造多种群粒子群算法GMPSO
基于负载感知的初始化
为满足任务的优先级约束,本文采用拓扑排序生成初始任务序列,并在此基础上设计了负载感知的任务—虚拟机映射策略。不同于传统的随机初始化,该手段充分考虑任务数据量与虚拟机性能的异构性:将数据量大于平均值的任务分配至高性能 VM 组,将数据量较小的任务分配至低性能 VM 组,并在组内优先选择当前负载最轻的 VM,从而提升资源利用率,避免关键任务被低算力 VM 拖慢执行进度或高性能 VM 长时间空闲。通过该机制,初始化阶段即可获得质量更高的调度方案,为后续优化提供良好起点,实用缓解算法过早收敛和局部最优的问题。

遗传算子

在调度问题中,遗传算子分为交叉与变异两类,均作用于任务序列与映射序列。
- 交叉:任务序列交叉需保持任务依赖关系,采用基于拓扑序的方法生成新个体;映射序列交叉则无约束,只需交换片段即可。
- 变异:任务序列变异受依赖约束,采用局部交换策略在前驱与后继范围内调整任务位置;映射序列变异不受约束,通过随机更改虚拟机编号搭建。


差异化多种群框架
在GMPSO 中,个体按适应度分为优良、一般和劣质三类,并采用差异化算子:优良子种群以小概率交叉保持精英质量并防止早熟收敛;劣质子种群以高概率变异增强多样性、拓展搜索空间;一般子种群则兼顾交叉与变异,在全局探索与局部收敛间起到平衡作用。随着演化推进,交叉与变异概率由 Sigmoid 函数动态调节,以保证稳定收敛至帕累托前沿。

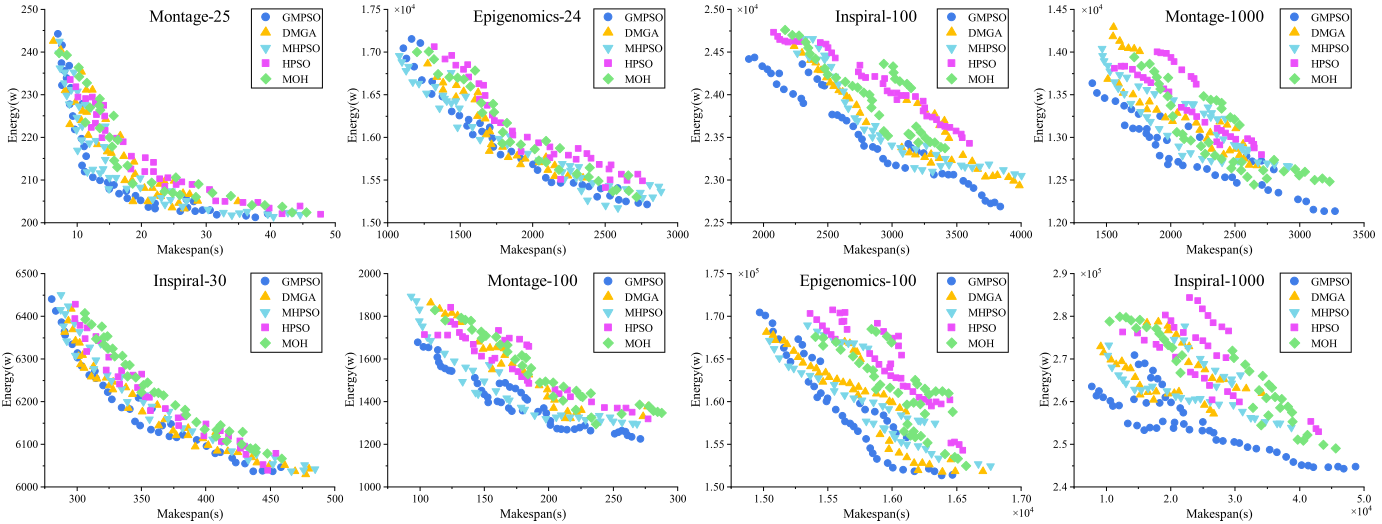
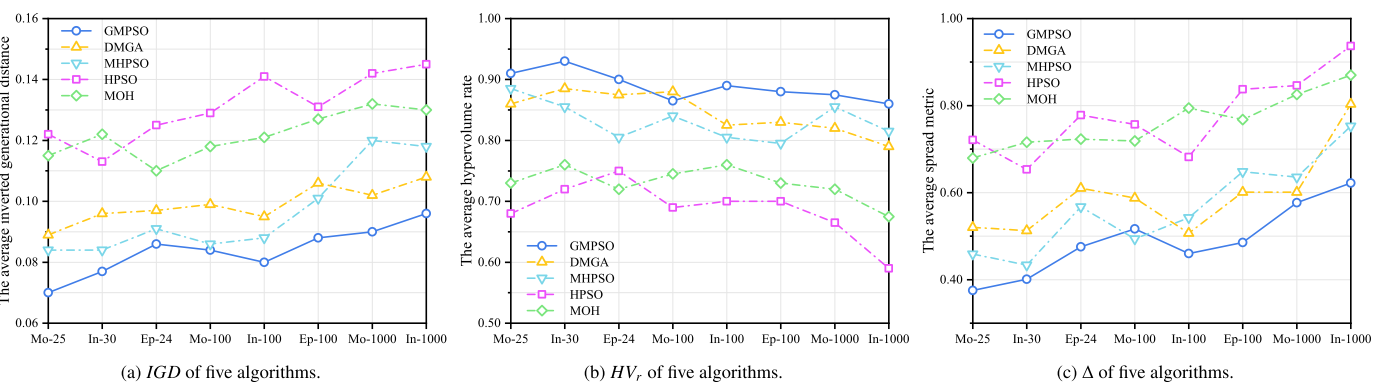
4.结果展示
5.参考文献
[1] Zhang P, Gao J, Tan L, et al. Genetically-modified multi-population particle swarm optimization for workflow scheduling in cloud environment[J]. Swarm and Evolutionary Computation, 2025, 98: 102113.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号