


实用指南:MySQL进阶-索引(全面讲解)
目录
1.索引概述
索引(index)是帮助MySQ高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就行在这些数据结构上达成高级查找算法,这种数据结构就是索引。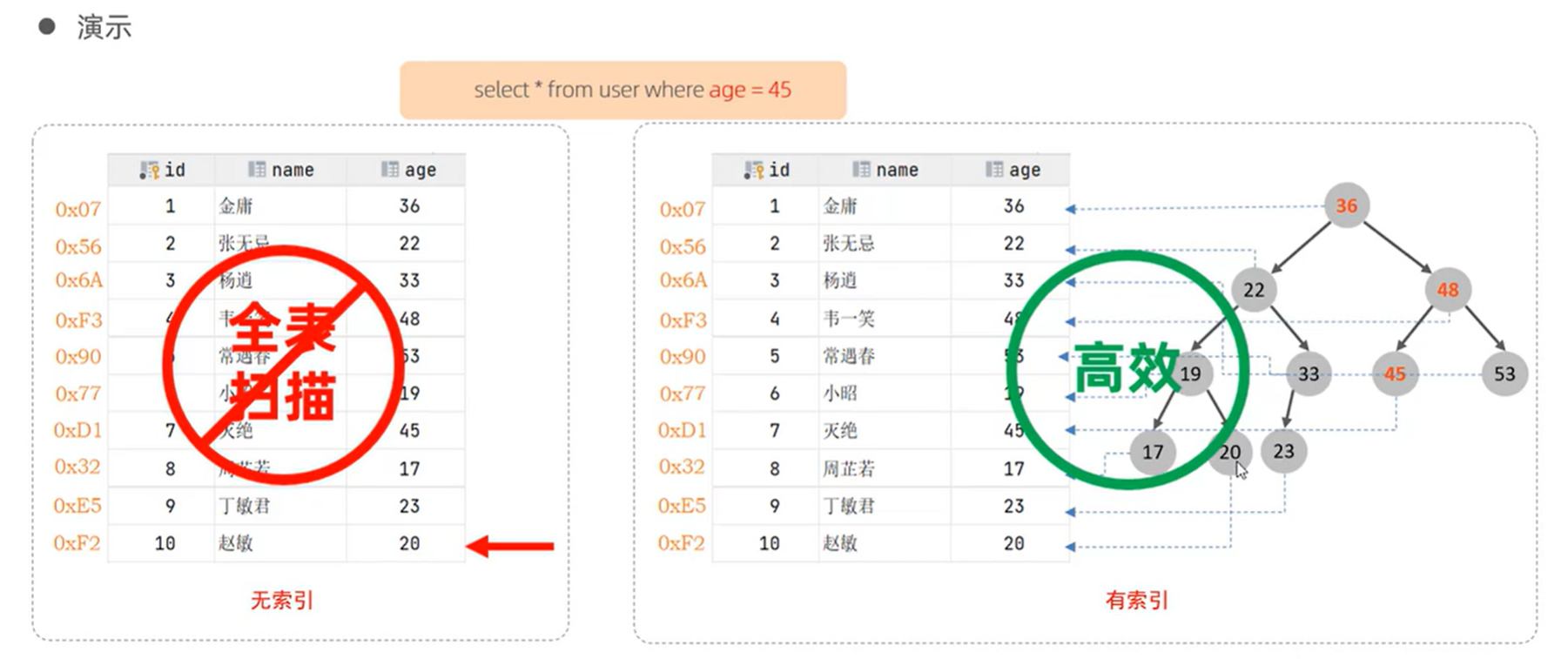

2.索引结构
| 索引类型 | 描述 | 特点 | 适用场景 | 支持的引擎 |
|---|---|---|---|---|
| B+树索引 | 基于B+树的数据结构,支持高效的范围查询和顺序访问。 | - 支持范围查询和排序操作。- 支持前缀索引和复合索引。- 拥护唯一性和非唯一性索引。 | - 大部分关系型数据库应用。- 需要高效范围查询和排序的场景。 | 大部分存储引擎,如 InnoDB、MyISAM。 |
| Hash索引 | 基于哈希表实现,通过哈希函数将键值映射到哈希表中。 | - 只协助精确匹配查询,不帮助范围查询。- 查询速度快,适合等值查询。 | - 需迅速等值查询的场景。- 例如,缓存系统中的键值对查询。 | - Memory 存储引擎。- 一些 NoSQL 数据库(如 Redis)。 |
| R-tree索引 | 一种空间索引,用于地理空间数据,如多边形、矩形等。 | - 专门用于空间数据的索引。- 帮助空间范围查询和空间关系查询。 | - 地理信息系统(GIS)应用。- 需要处理空间数据的场景。 | - MyISAM 存储引擎。- 一些专门的GIS数据库。 |
| Full-text索引 | 用于全文搜索的索引,依据建立倒排索引实现快速文本匹配。 | - 通过倒排索引搭建快速文本匹配。- 支持全文搜索和模糊查询。 | - 需要全文搜索的场景。- 例如,搜索引擎、文档管理系统。 | - InnoDB 存储引擎。- 一些专门的全文搜索引擎(如 Lucene、Solr、Elasticsearch)。 |
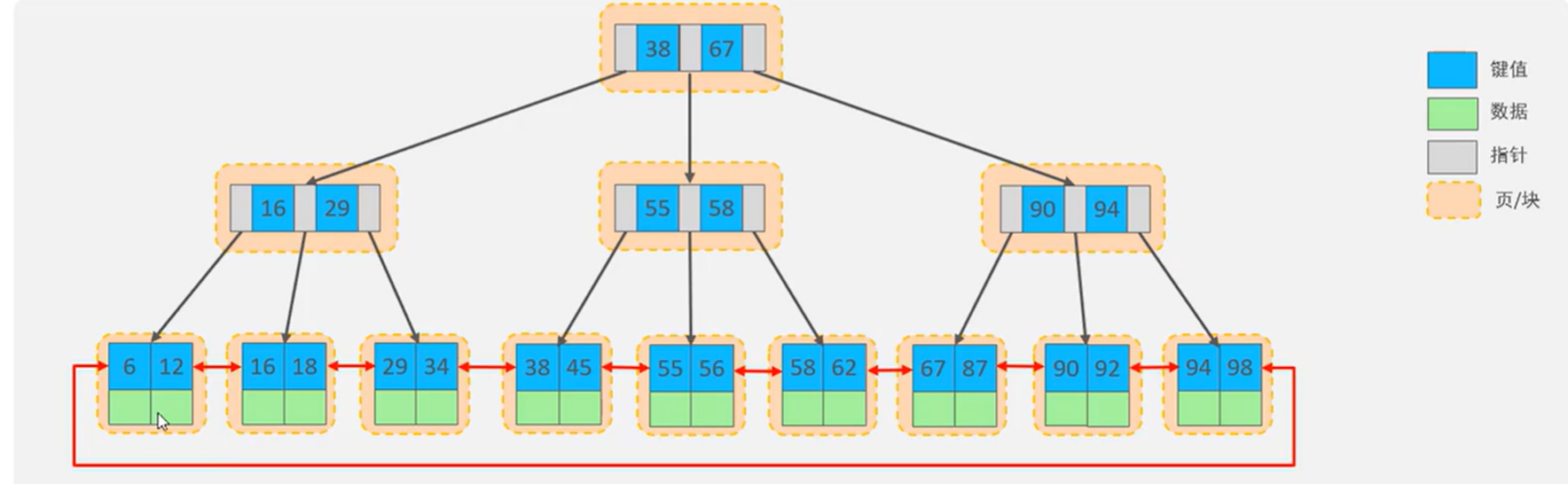
B-Tree
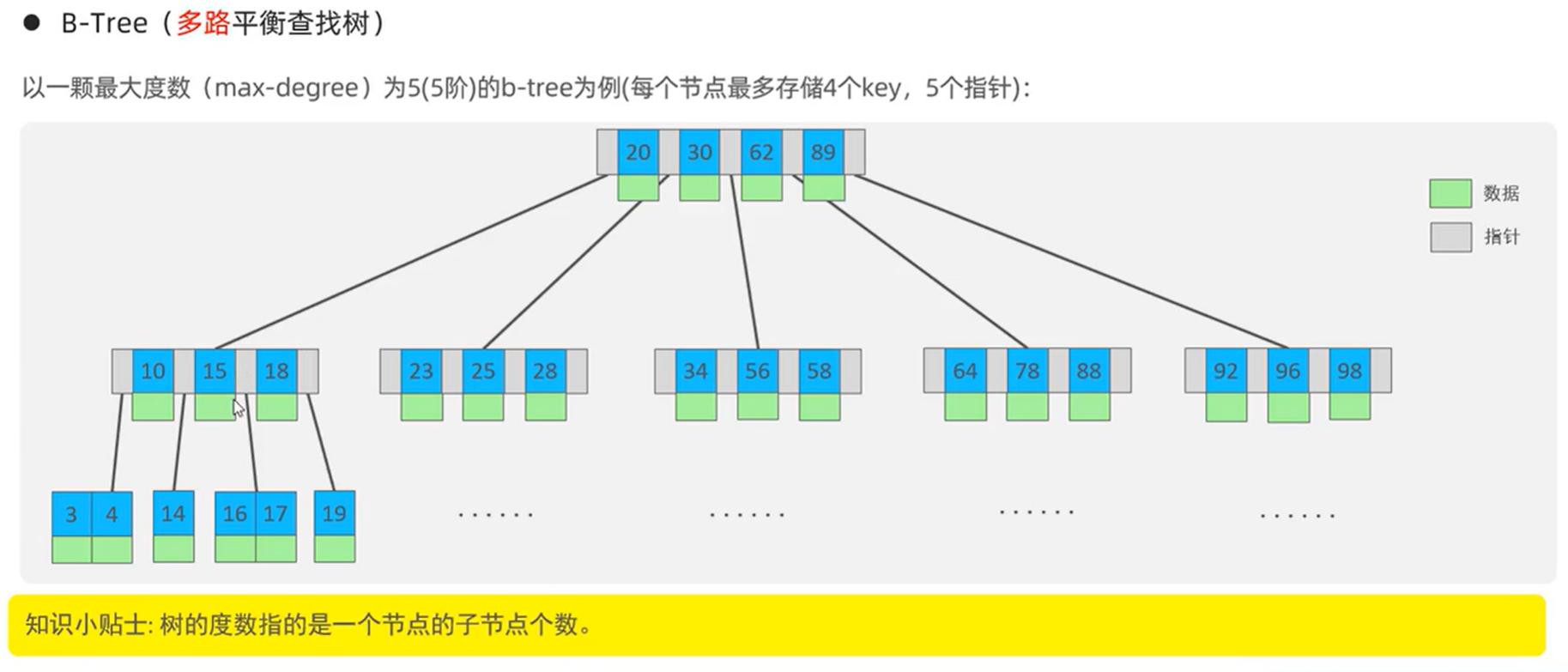
素材演变过程为向上分裂,n阶树中每个节点最多存储n-1个key,n个指针,拥有n个子节点。
B+Tree
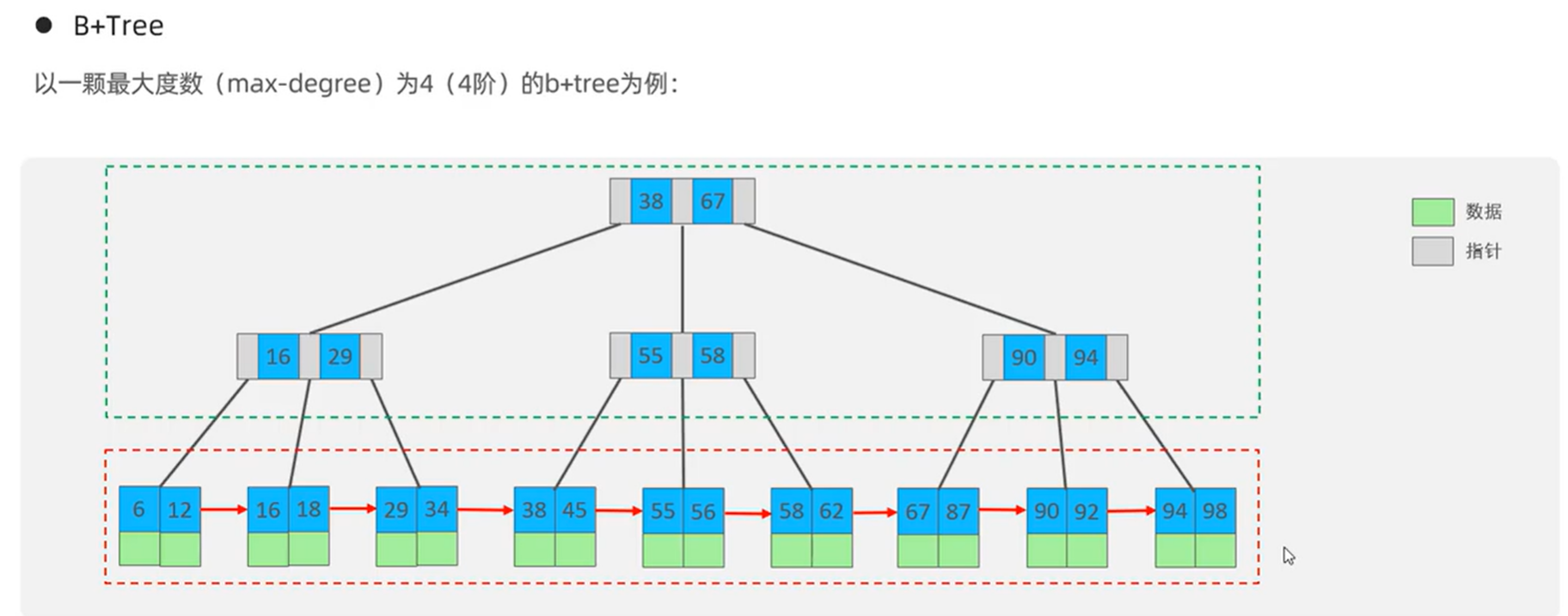
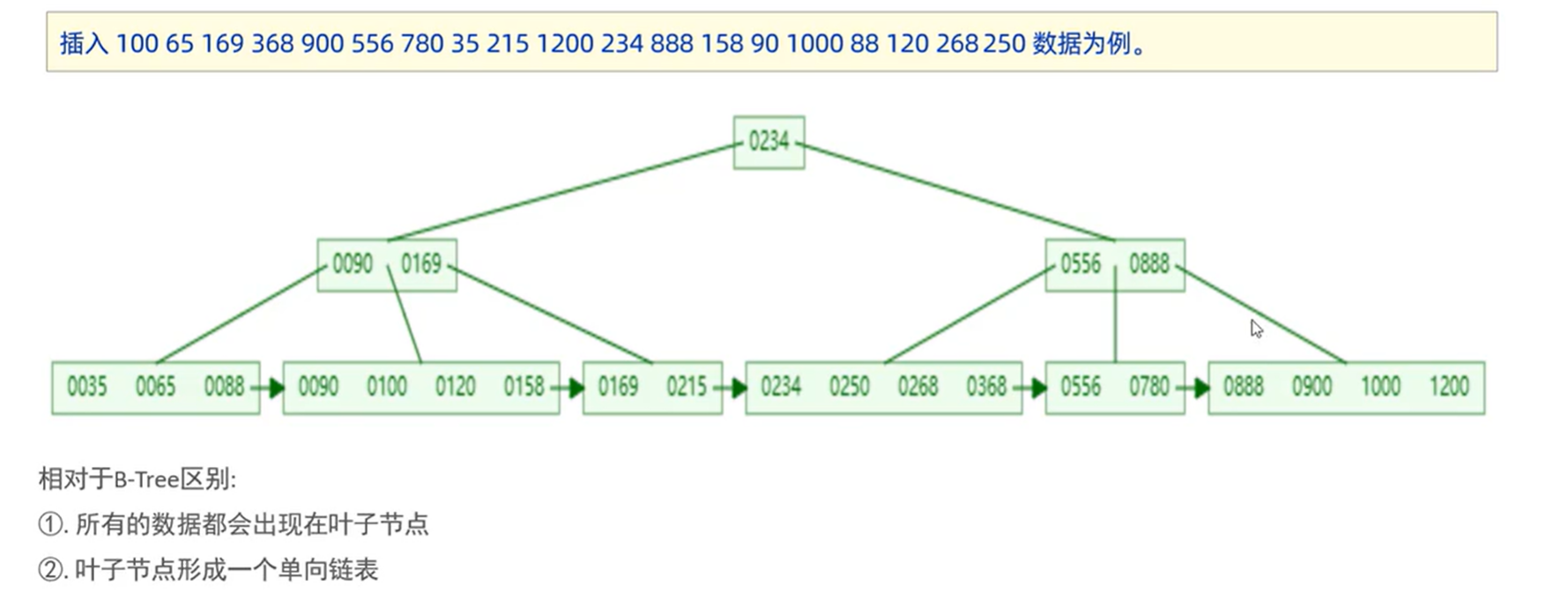
MySQL中的优化B+Tree
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
Hash索引
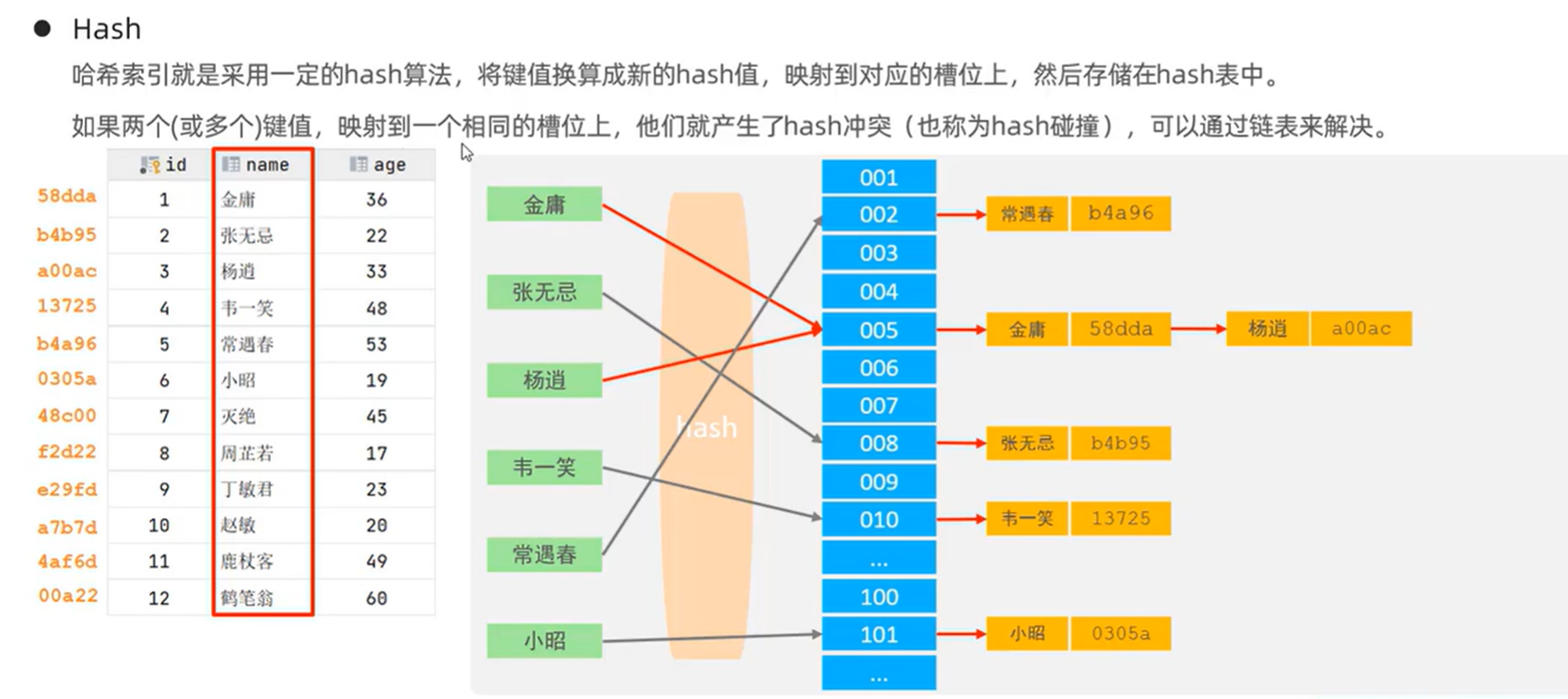
| 特点 | 描述 |
|---|---|
| 对等比较支持 | Hash 索引只能用于对等比较(如 =、IN),不支持范围查询(如 BETWEEN、>、< 等)。 |
| 不支持范围查询 | 由于 Hash 索引基于哈希表实现,无法帮助范围查询。 |
| 排序操作 | 无法利用 Hash 索引完毕排序管理。 |
| 查询效率 | 查询效率高,通常只需要一次检索即可完成,效率通常高于 B+Tree 索引。 |
| 存储引擎支持 | 在 MySQL 中,支持 Hash 索引的存储引擎主要是 Memory 引擎。 |
| 自适应 Hash 作用 | InnoDB 存储引擎具有自适应 Hash 功能,Hash 索引是存储引擎根据 B+Tree 索引在指定条件下自动构建的。 |
3.为什么INNODB使用B+Tree![]()

4.索引分类

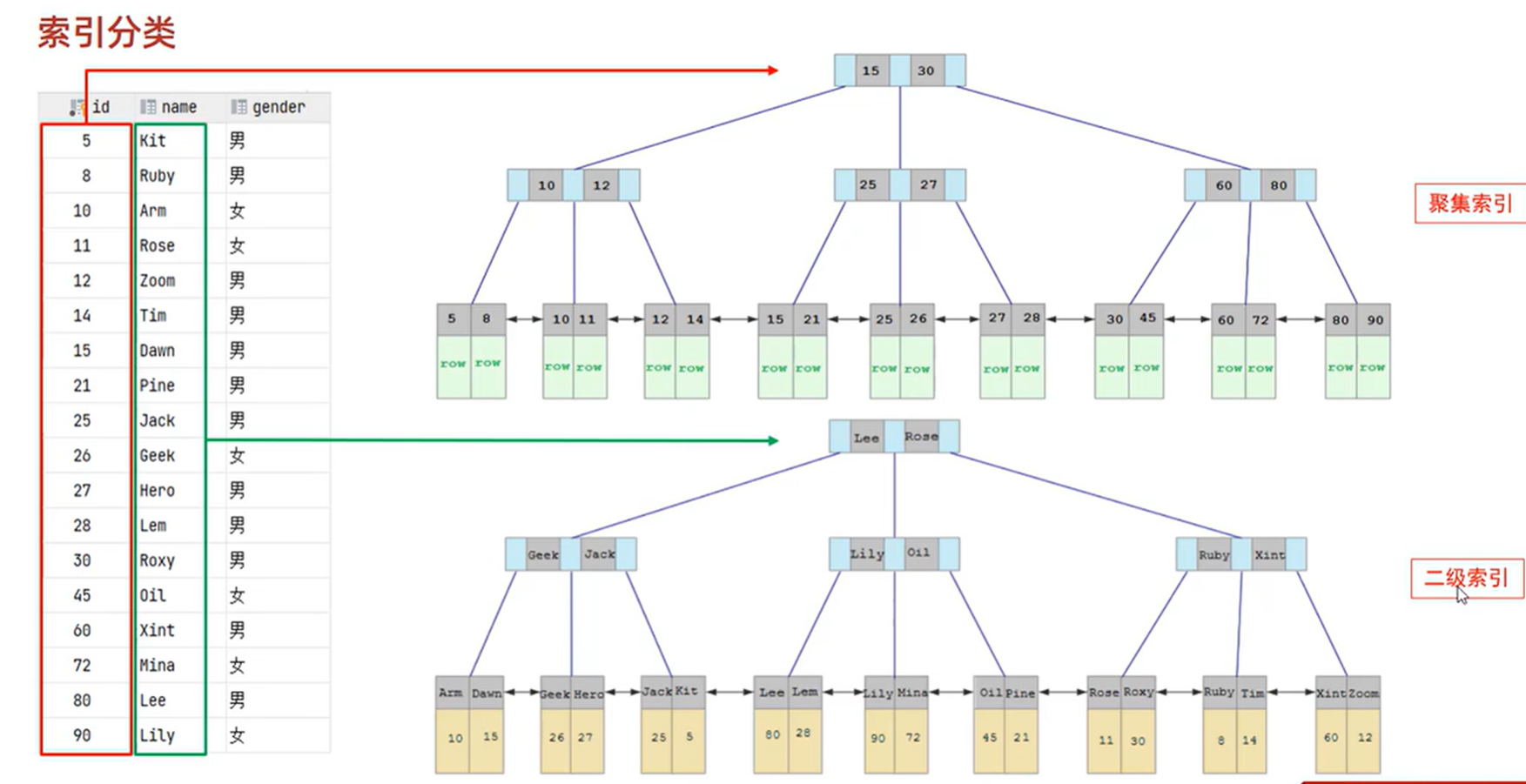
特性 聚集索引 二级索引 定义 表中数据的存储顺序与索引的顺序一致 基于表中的非主键列创建的索引 数据存储 素材行按照索引顺序存储 叶子节点存储主键值,利用主键值回表查询素材行 每个表的数量 每个表只能有一个聚集索引 一个表能够有多个二级索引 查询效率 高效,直接定位到资料行 较低,需要回表查询完整的数据行 适用场景 主键查询、范围查询、排序和分组 非主键查询、多列查询、过滤和排序

B+Tree只有叶子节点存储数据,内部节点只存储指针和键。
一页代表一个节点,16K。 由于一行数据大小为1K,则一页存16行数据。
一层树只有1页*16行数据。
2层树由于一层存指针和键值,16*1024字节=n*8+(n+1)*6 =>n=1170个
则一个节点(一页)存1170个键,1171个指针。
说明一层有1170个键,1171个指针,指向第二层1171个页
2层树有1171*1171*16行数据.=18736行内容
3层树有1171*1171*16行数据=21939856行素材
5.索引语法
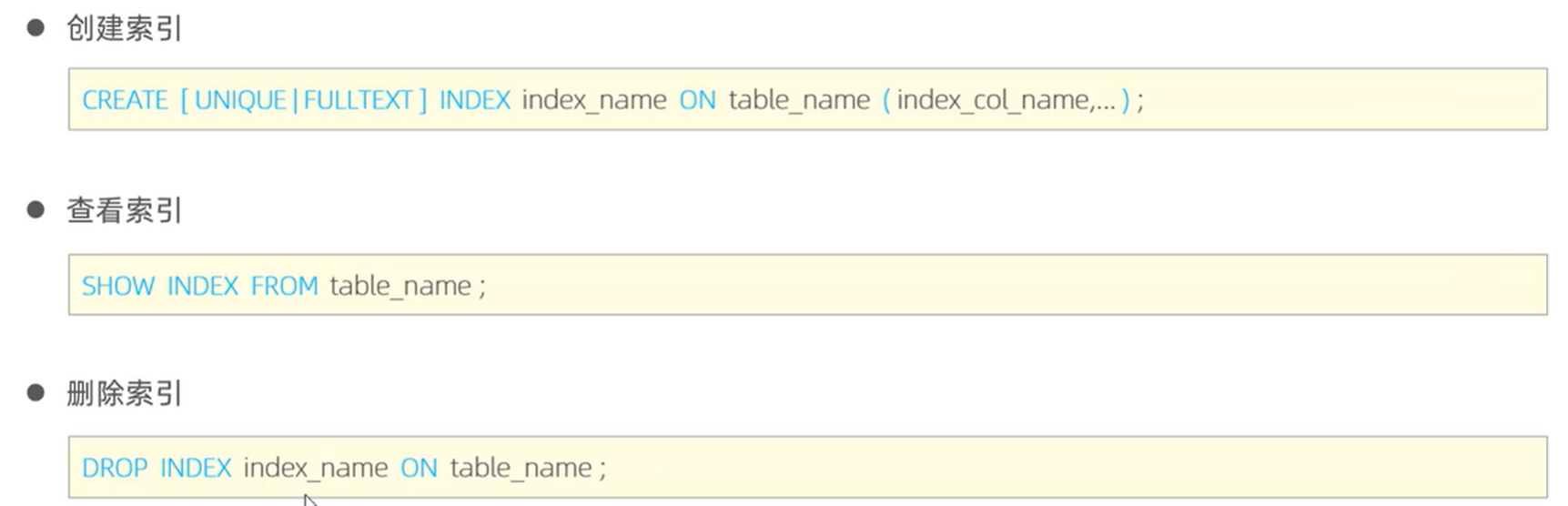

6.性能分析
查看执行频率
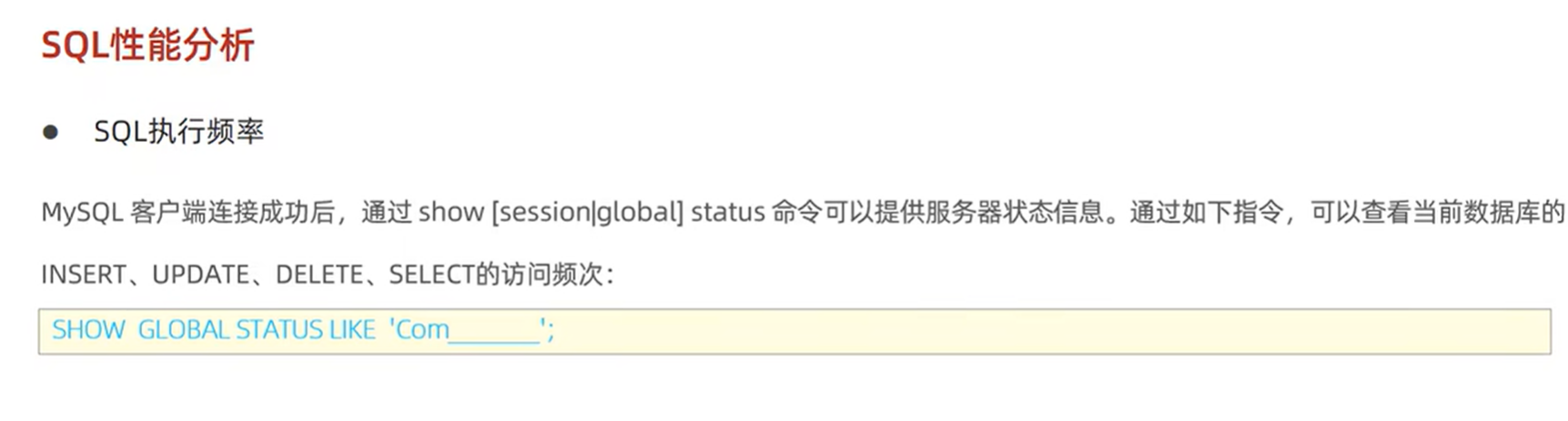
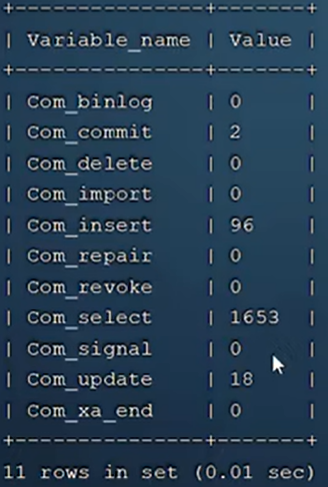
判断当前数据库在增删改查中,哪个操作频繁,针对其进行优化。
慢查询日志


show profiles
查看每条SQL语句的耗时情况,以及具体在哪一块的耗时。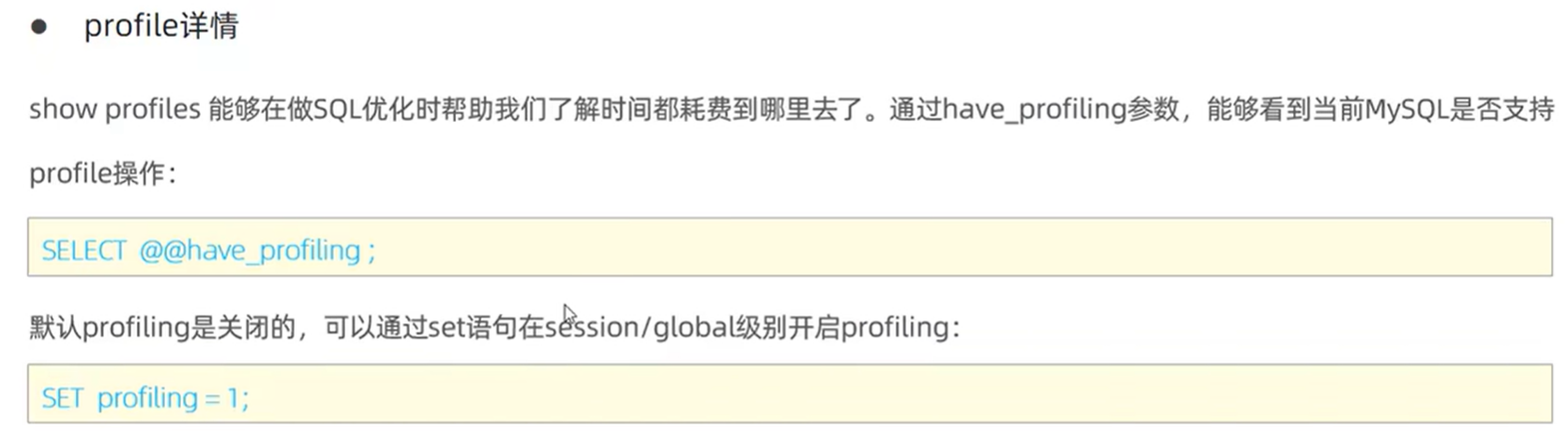

explain执行计划![]()
![]()


7.索引使用规则
最左前缀法则![]()
![]()

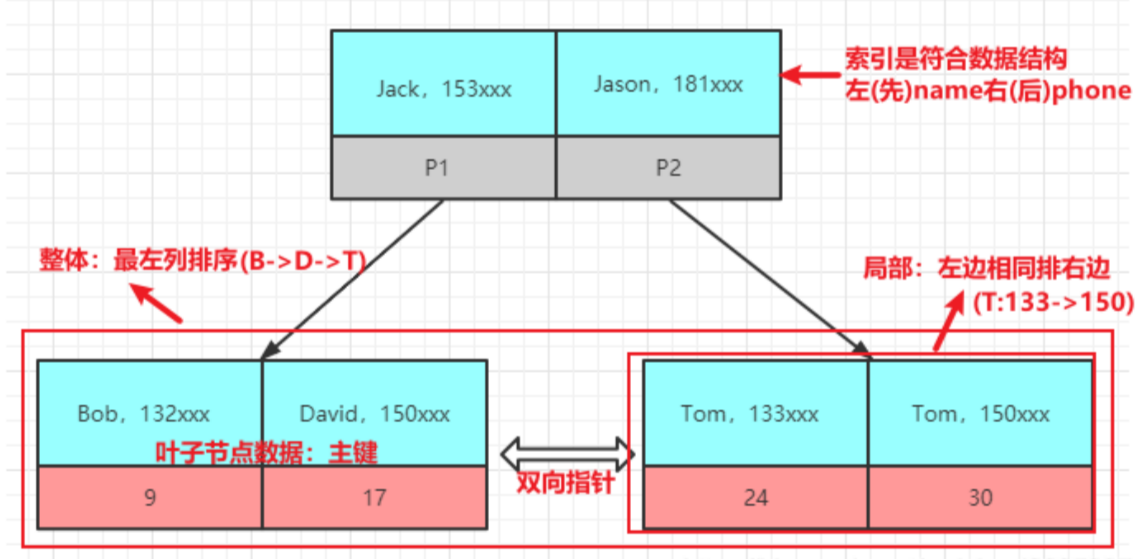
联合索引满足最左前缀法则的原因主要与 B+Tree 的结构特性有关:
查询优化:B+Tree 的查询是从最左边的列开始的,逐步向右匹配。只有最左边的列(或多个列)可以用于优化查询。
索引覆盖:如果查询的列都在复合索引中,那么这个查询可以被索引覆盖,从而避免回表查询,进一步提高查询性能。
由于联合索引的B+Tree构造顺序的优先级是从左至右。所以在左列未知的情况下,右边的内容多是无序(例如该树中电话列)。
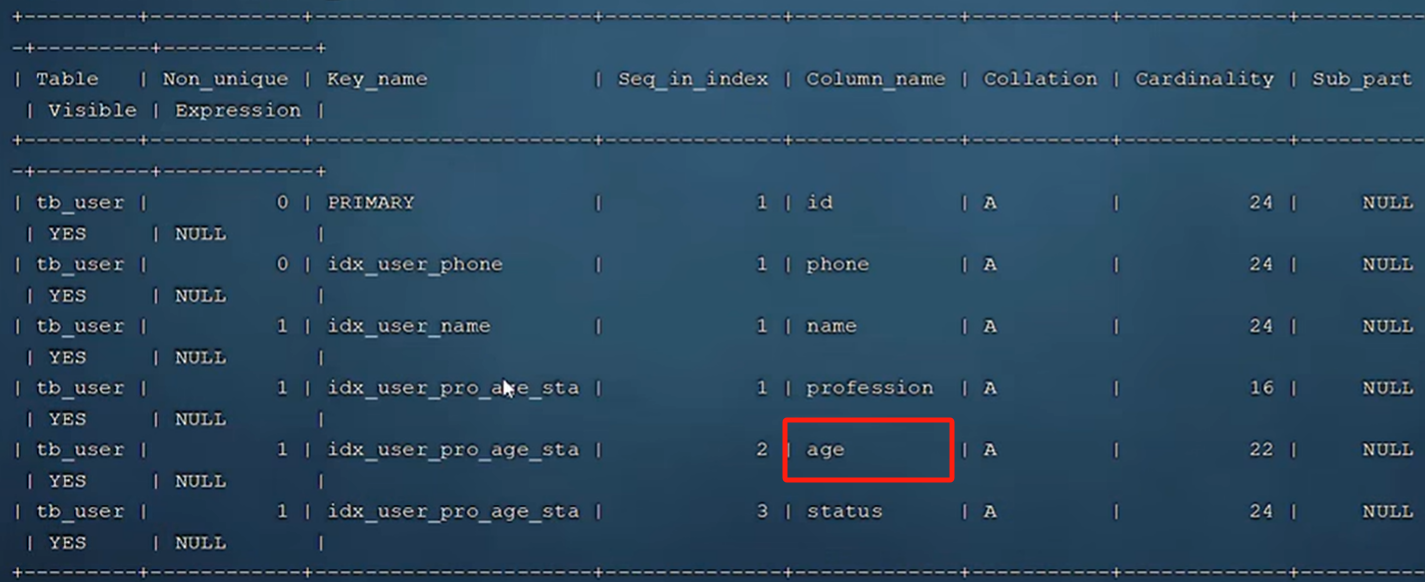
idx_user_pro_age_sta 以该联合索引为例演示:

索引长度为54,满足最左前缀法则

索引长度为49,满足最左前缀法则。 则status字段的索引长度为5

索引长度为47,满足最左前缀法则。 则age字段的索引长度为2

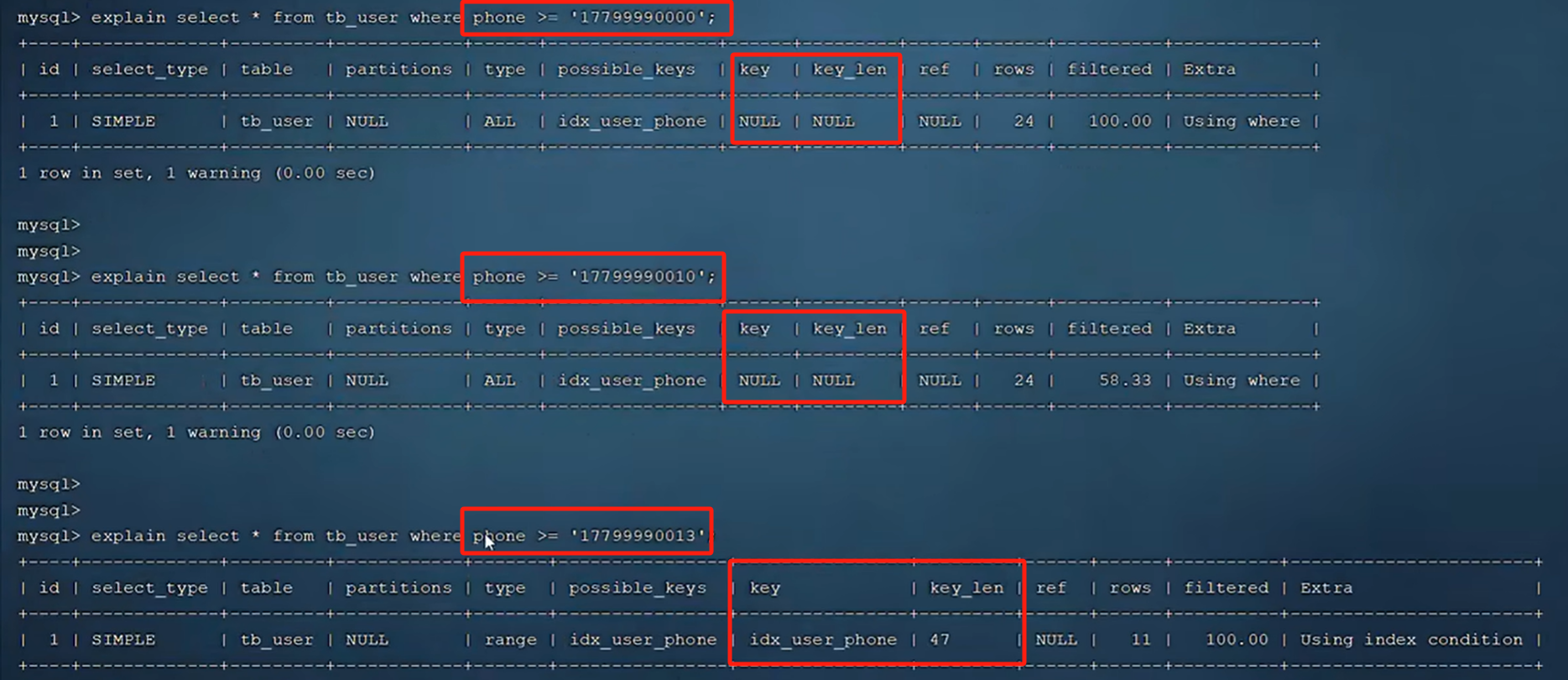
由于跳过profession字段,不满足最左前缀法则,不走索引,type=ALL为全表扫描。
索引长度为47,满足最左前缀法则,由于未包含age字段,后续字段索引失效。
索引失效
范围查询![]()
![]()


索引长度为49,由于age字段使用了范围查询,所以右侧列索引失效。
将范围查询替换为 (>=,<=) 索引长度为54,右侧列生效。
在实际业务中尽量包含等于的范围查询可以提高索引的查询效率,防止索引失效。
索引列运算

字符串不加引号


同一查询语句,由于status字段的字符串未加引号,索引长度从54->49,索引失效。


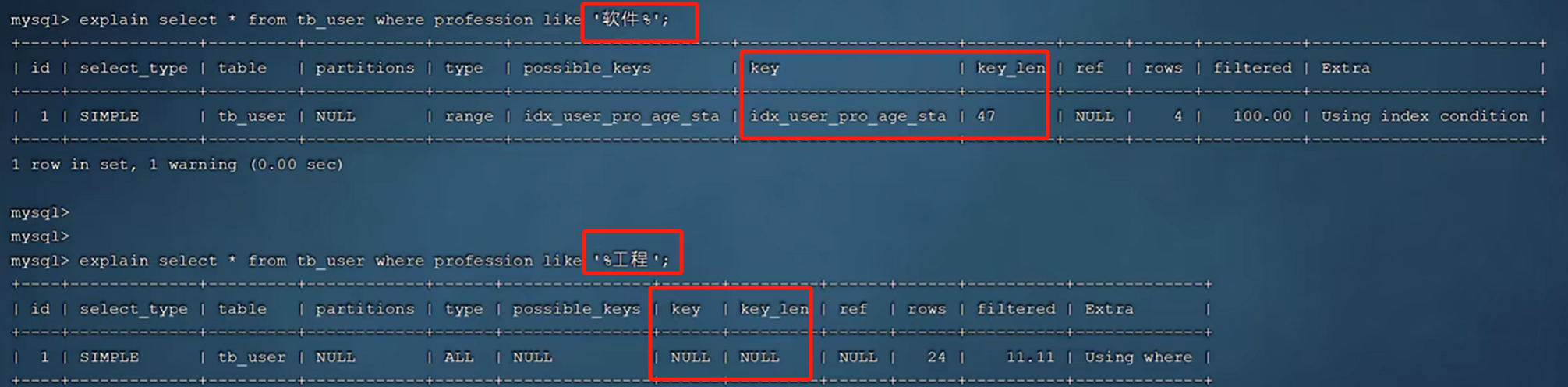
模糊查询
只要头部加了%模糊匹配,则失效。

or语句连接
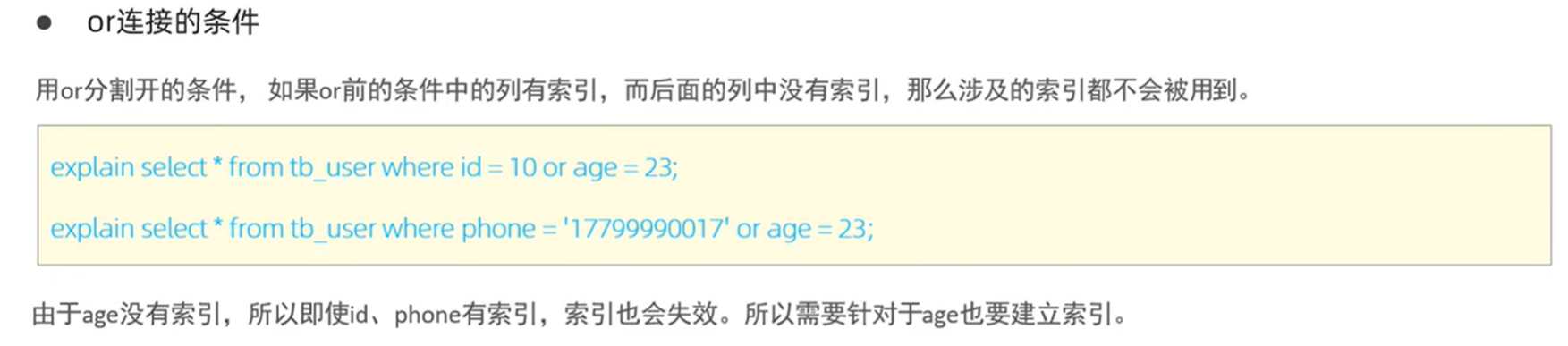
原表中只有包含age的联合索引,单独查询age时不生效,无单列索引。

在or条件中,哪怕id有primary主键索引,但age无索引,于是整个查询索引失效。

同理。

在单独给age添加索引后,整个查询的索引生效。
数据分布影响
MySQL会评估采用索引和全表扫描的效率来决定是否使用索引。
要是查询内容为表中大部分数据满足则走全表,反之查询内容为小部分数据则走索引。
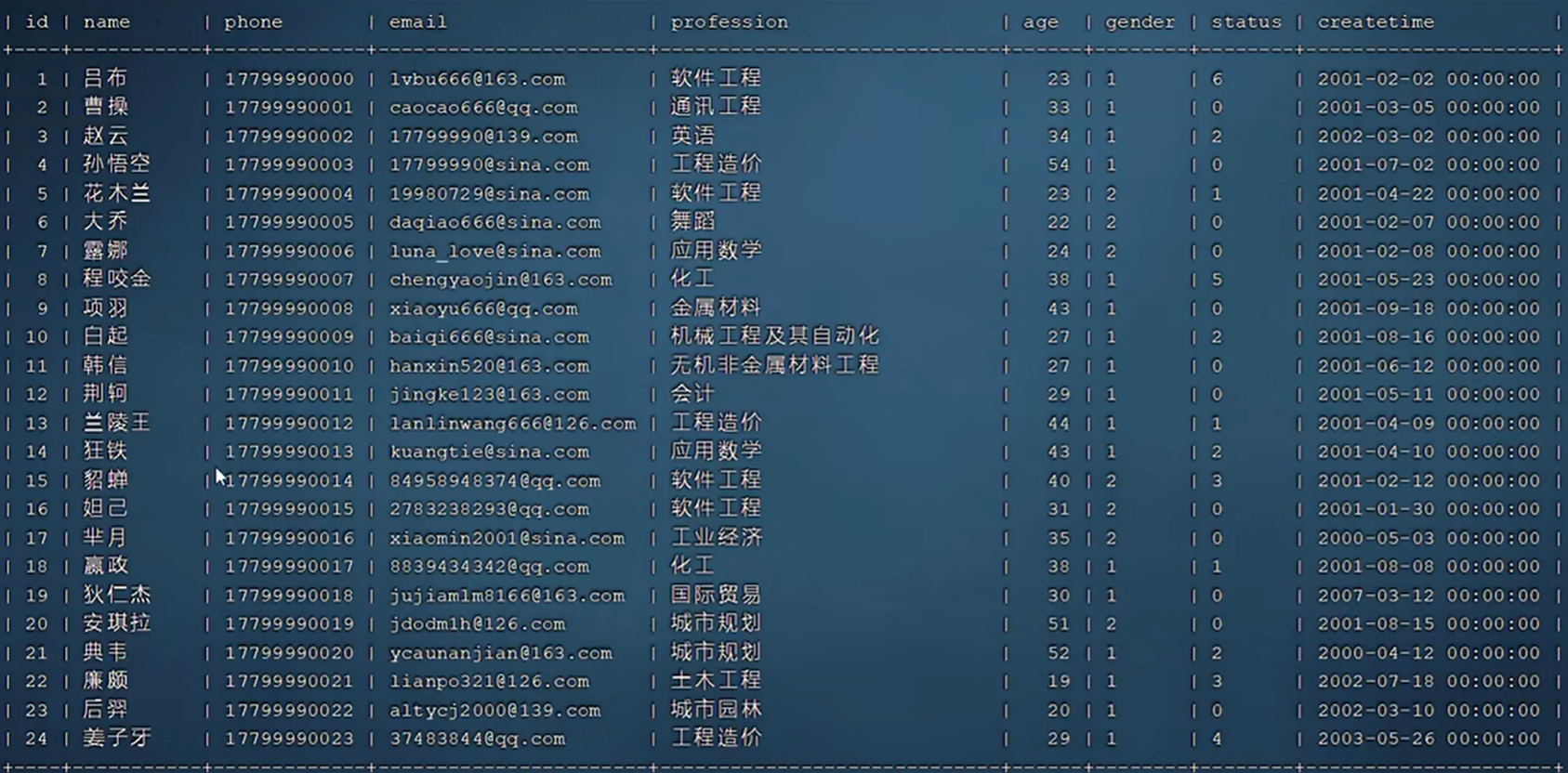
表中成员手机号为0-23
当查询为>0,则表中所有数据,评估为全表扫描效率高。
当查询>10,则为表中大部分数据,仍然评估为全表扫描效率高。
当>13时,则为小部分数据,评估为索引查询。

建议,具体由MySQL自己判断。就是ues
禁止采用该索引。就是ignore
force为必须采用该索引。
覆盖索引&回表查询

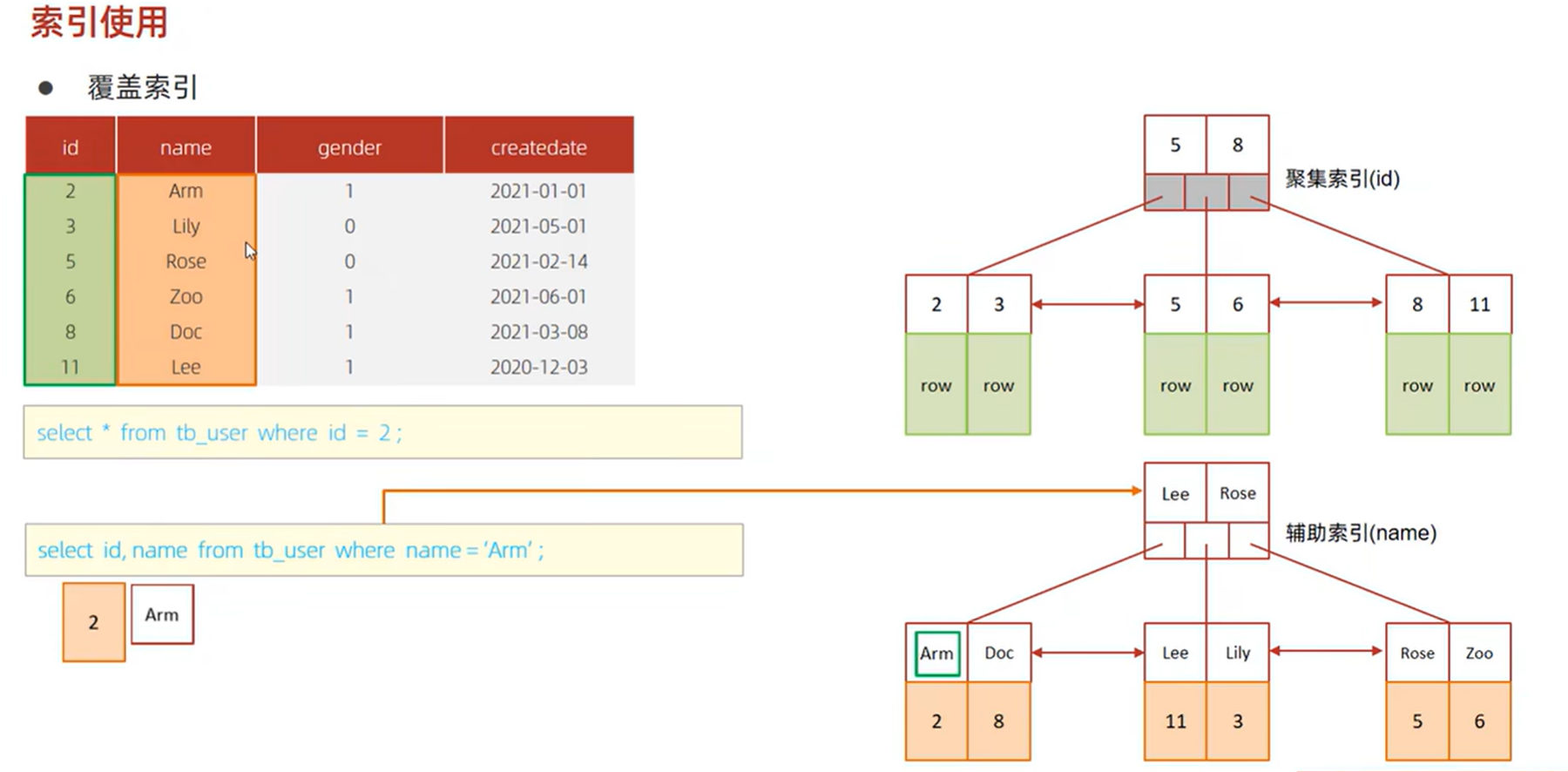
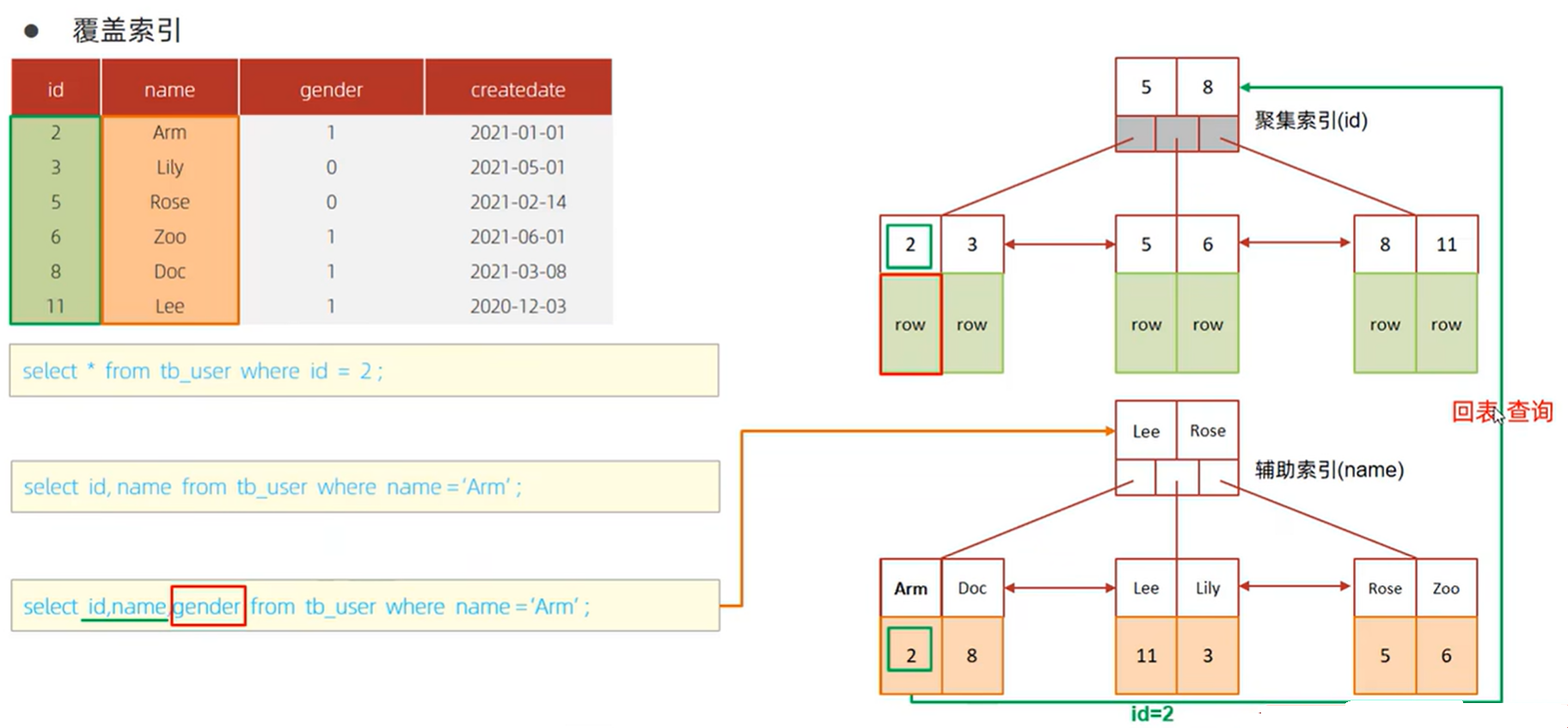
查询借助辅助索引找到了name和id列,但是未找到gender列
再通过id值,回表通过聚集索引到对应行过滤得到gender列
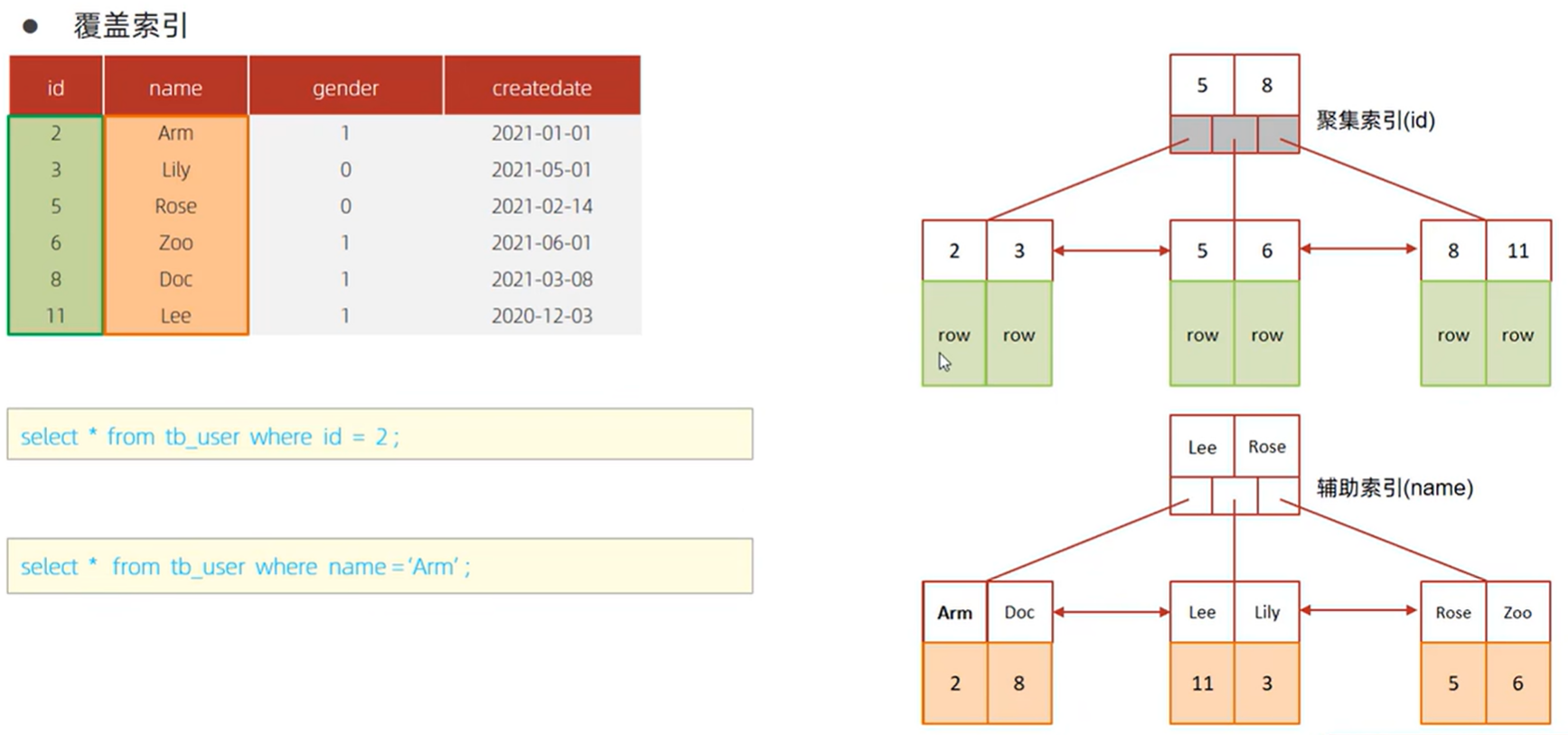
同样返回所有字段,通过聚集索引id可以直接得到。而凭借辅助索引得到id还需通过回表查询,性能低。

假如单独建立username的单列索引的话,由于查询列囊括password,单次查询无法得到该字段。
再次通过id进行回表查询得到对应行再过滤得到password。
所以最佳方案为:建立username和password的联合索引。
前缀索引![]()
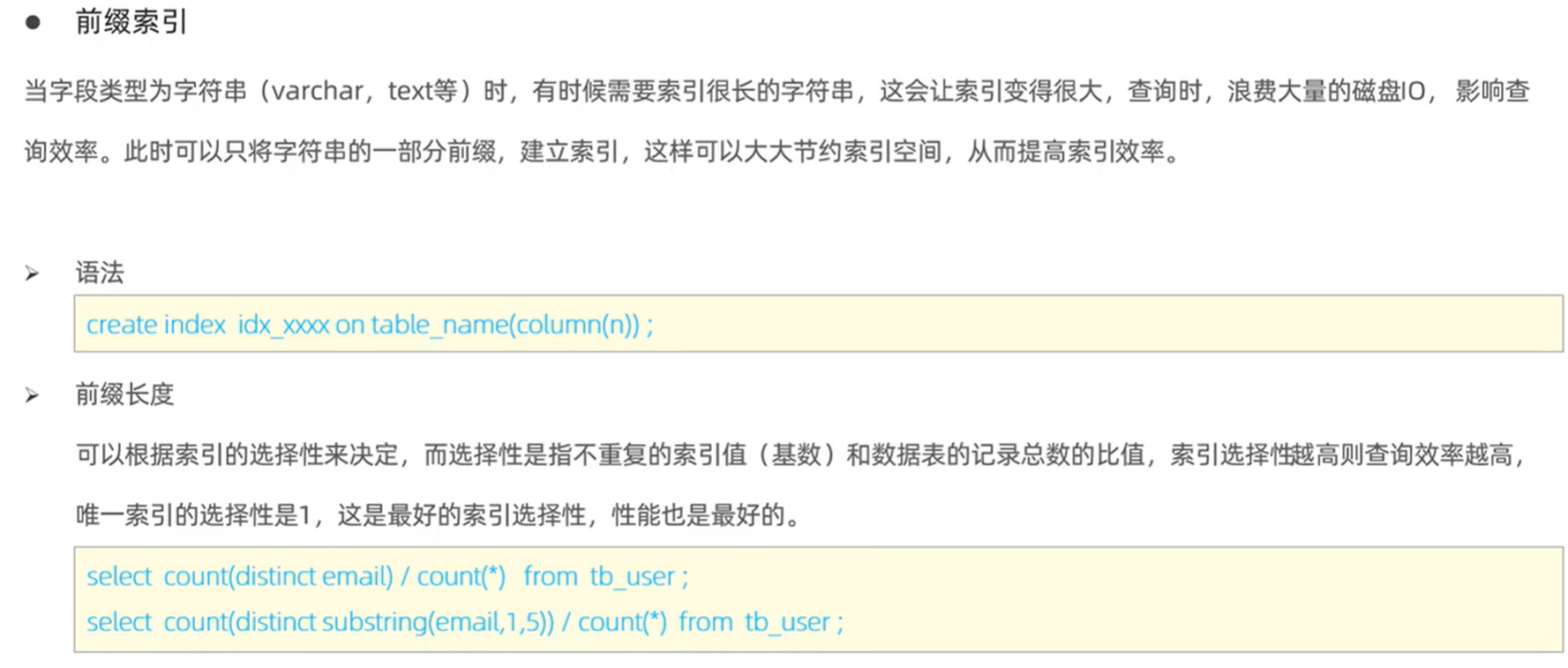
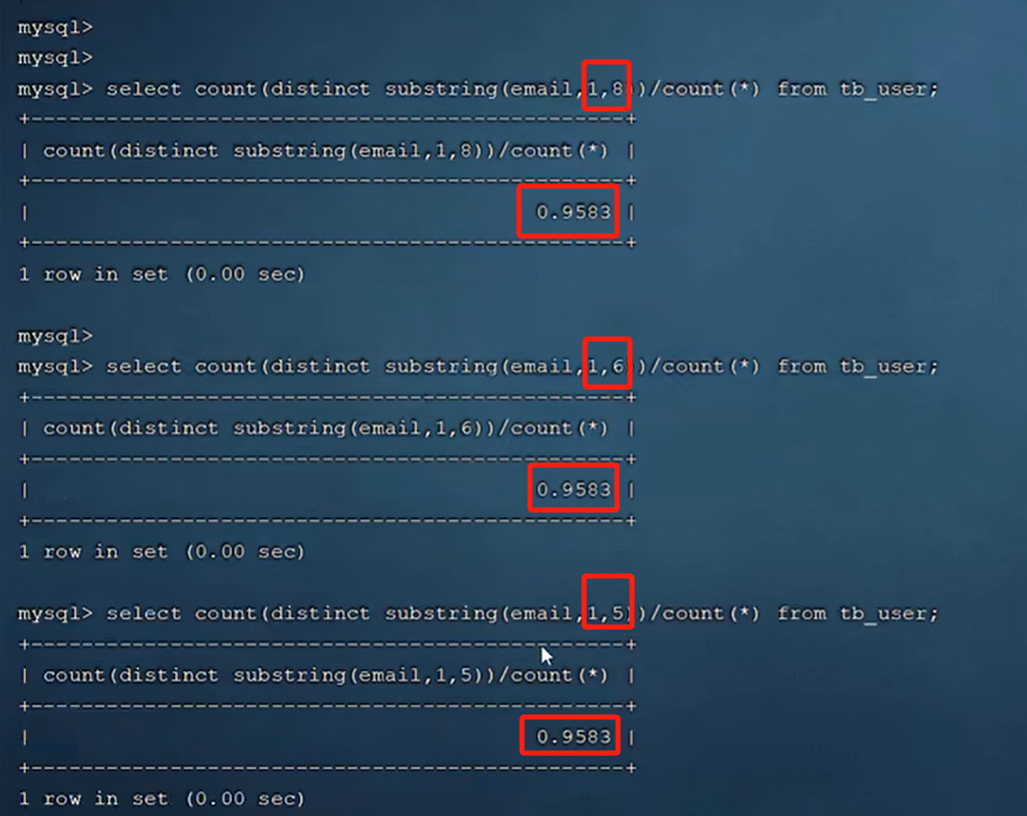
根据选择性和索引字段长度,权衡合适的前缀长度。
查询过程
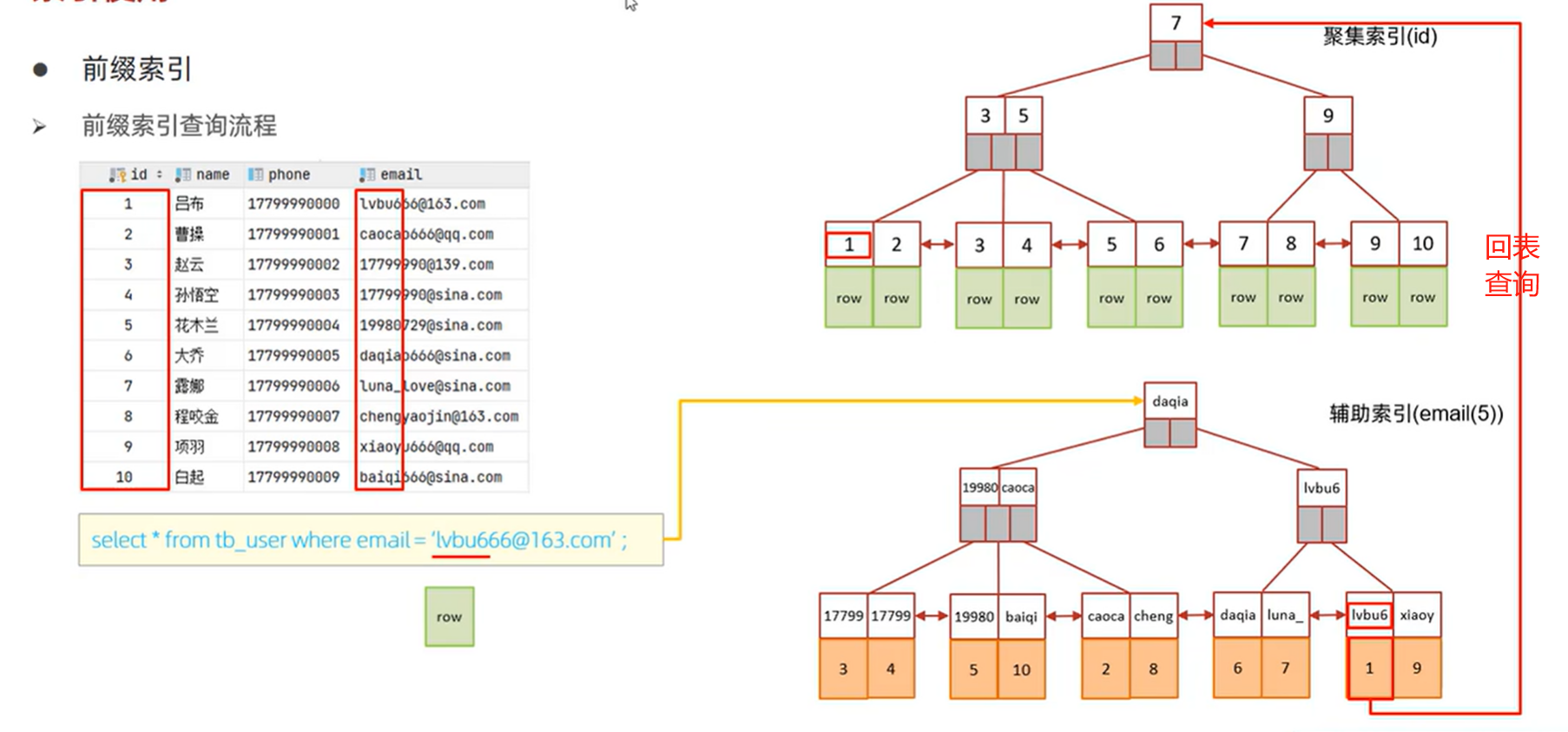
存在则根据其主键值回表查询对应完整行资料就是1.经过前缀索引找到对应行,要
2.根据查询到的完整行数据与where语句中条件比对,如果不同数据库会(凭借叶子节点中的链表)继续查找下一个匹配的前缀索引条目,直到找到完全匹配的行或所有匹配的前缀索引条目都已检查完毕。
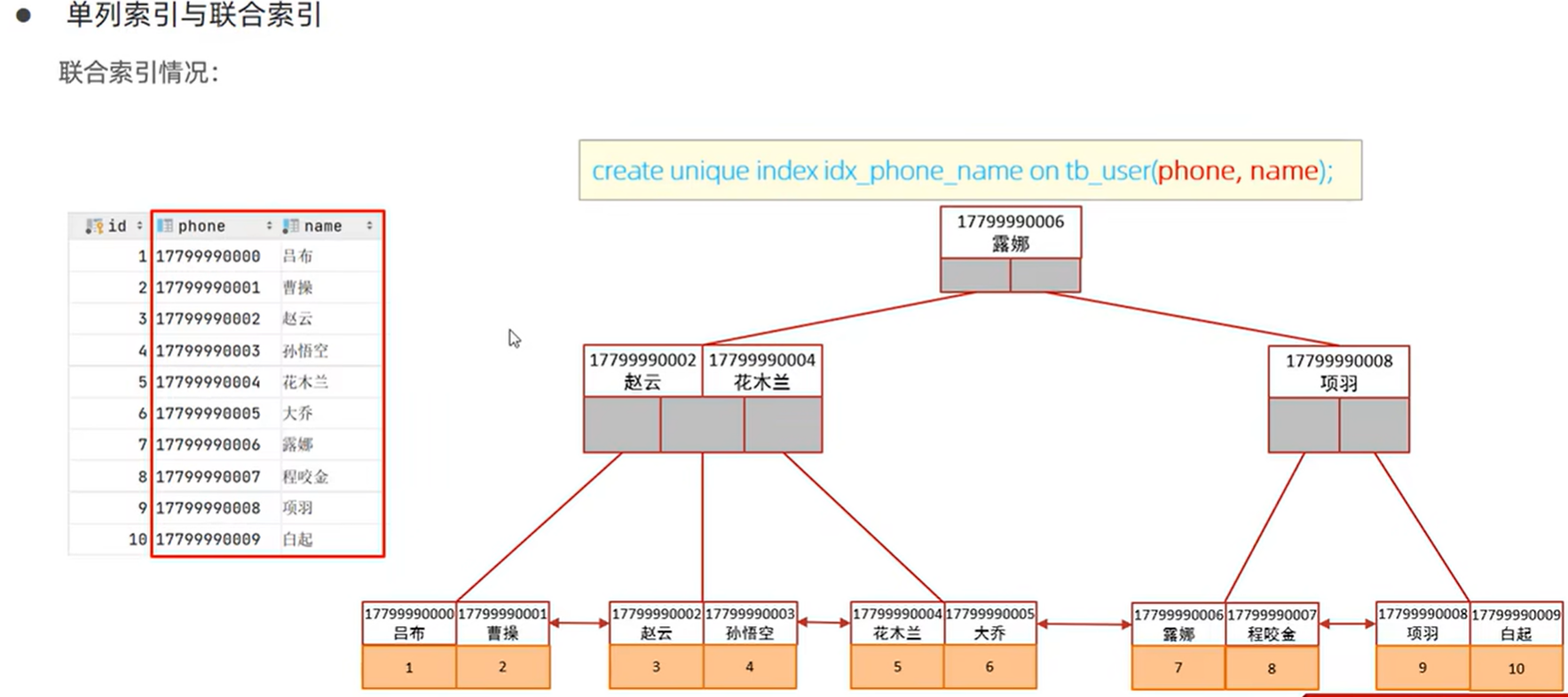
单列索引&联合索引![]()
![]()


一次查询中MySQL会选一种索引完成本次查询,由于该查询中只用了phone字段的索引,name字段没走索引,该表返回列包含name字段需进行回表查询 Extra=NULL

8.索引设计原则![]()

9.索引分类总结
数据结构
| 索引类型 | 结构 | 查询效率 | 适用场景 |
|---|---|---|---|
| B+树索引 | 多路平衡树 | 范围查询和顺序访问高效 | 关系型数据库,需要高效范围查询和排序的应用 |
| 哈希索引 | 哈希表 | 精确匹配查询高效 | 缓存系统,需要快速等值查询的场景 |
| 倒排索引 | 倒排表 | 全文搜索和模糊查询高效 | 全文搜索引擎,需要全文搜索和模糊查询的应用 |
| R 树索引 | 空间索引 | 空间范围查询和空间关系查询高效 | 地理信息系统,需要处理空间数据的应用 |
B+树索引:适用于关系型数据库,支持高效范围查询和排序。
哈希索引:适用于需要飞快等值查询的场景,如缓存体系。
倒排索引:适用于全文搜索引擎,支持全文搜索和模糊查询。
R 树索引:适用于地理信息系统,支持空间范围查询和空间关系查询。
InnoDB构建
| 特性 | 聚簇索引 | 非聚簇索引 |
|---|---|---|
| 定义 | 必须存在,默认为主键索引,若没有主键则选取任意唯一索引作为聚簇索引 | 基于表中的非主键列创建的索引 |
| 数据存储 | 完整行数据 | 叶子节点存储主键值,依据主键值回表查询素材行 |
| 每个表的数量 | 每个表只能有一个聚簇索引 | 一个表可以有多个非聚簇索引 |
| 查询效率 | 高效,直接定位到数据行 | 较低,需要回表查询完整的数据行 |
| 适用场景 | 主键查询、范围查询、排序和分组 | 非主键查询、多列查询、过滤和排序 |
索引性质
| 索引类型 | 定义 | 特点 | 适用场景 |
|---|---|---|---|
| 普通索引 | 基于一个或多个列创建的索引 | 通过不唯一,能够包含重复值 | 得飞快查找但不要求唯一性的列 |
| 主键索引 | 用于唯一标识表中的每一行 | 唯一,非空 | 需要唯一标识每一行的列 |
| 唯一索引 | 用于确保索引列的值是唯一的 | 唯一,可以包含 NULL 值 | 需要确保列值唯一但允许 NULL 值的列 |
| 联合索引 | 基于多个列创建的索引 | 多列,遵循最左前缀法则 | 需要在多个列上进行查询的场景 |
| 全文索引 | 用于全文搜索 | 支持复杂的文本匹配和模糊查询 | 需要全文搜索的列 |
| 空间索引 | 用于处理地理空间数据 | 支持空间范围查询和空间关系查询 | 地理信息系统和需要处理空间数据的应用 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号