


Day11_【pandas】开源库 - 指南
Pandas数据分析开源库,是一个强大的分析结构化数据的工具集, 它的使用基础是Numpy(提供高性能的矩阵运算) 用于数据挖掘和数据分析,同时也提供数据清洗功能。
数据结构
两种数据结构:Series,DataFrame
| 特性 | Series | DataFrame |
|---|---|---|
| 定义 | 一维带标签的数组,可以存储任何数据类型。 | 二维带标签的数据结构,类似于电子表格或 SQL 表,由行和列组成。 |
| 维度 | 一维 | 二维 |
| 索引 | 拥有一个索引(Index),用于标识每个元素。 | 拥有行索引和列索引,分别标识行和列。 |
| 数据类型 | 所有元素必须是相同的数据类型(同质)。 | 不同列可以有不同的数据类型(异质)。 |
| 创建方式 | 通常由一个列表、NumPy 数组或字典创建。 | 通常由字典(键为列名,值为数据)、二维数组或多个 Series 组合创建。 |
| 类比 | 类似于 Excel 中的一列,或 SQL 表中的一列。 | 类似于整个 Excel 表格或 SQL 表。 |
| 操作 | 支持向量化操作,如数学运算、过滤等。 | 支持对行、列进行选择、过滤、聚合、合并等复杂操作。 |
| 示例 | pd.Series([1, 2, 3], index=['a', 'b', 'c']) | pd.DataFrame({'A': [1, 2], 'B': [3, 4]}, index=['row1', 'row2']) |
Series
1.创建方式
1.ndarray
'''1.numpy的darray创建series'''
import numpy as np
import pandas as pd
arr = np.array([1, 2, 3, 4, 5])
print(arr)
print(type(arr))
s1 = pd.Series(arr)
print(s1)
print(type(s1))2.python的list
'''2.直接传入python列表,创建series'''
import numpy as np
import pandas as pd
s2 = pd.Series([1, 2, 3, 4, 5])
print(s2)
print(type(s2))
'''2.1传入python列表,并指定索引'''
# 索引个数必须与元素个数对等
s3 = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s3)
print(type(s3))3.元组
'''3.元组,创建series'''
import numpy as np
import pandas as pd
s4 = pd.Series((1, 2, 3, 4, 5))
print(s4)
print(type(s4))4.字典
'''4.字典,创建series'''
import numpy as np
import pandas as pd
s5 = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5})
print(s5)
print(type(s5))2.常用属性
| 属性/方法 | 说明 | 示例 |
|---|---|---|
| loc | 根据行索引获取某行数据,这是属于 DF 的对象 | s.loc['a'] → 获取索引为 'a' 的元素值 |
| iloc | 根据行位置获取某行数据,这是属于 DF 的对象 | s.iloc[0] → 获取第一个元素值 |
| dtype | 获取 Series 的元素类型 | s.dtype → int64 或 object 等 |
| dtypes | 获取 Series 的元素类型(与 dtype 相同) | s.dtypes → int64 或 object 等 |
| T | 转置(对于 Series 没有实际意义,但保持与 DataFrame 的一致性) | s.T → 返回自身 |
| shape | 获取 Series 的维度 | s.shape → (n,),其中 n 是元素个数 |
| size | 获取 Series 的元素个数 | s.size → 3 |
| values | 获取 Series 的元素值 | s.values → array([10, 20, 30]) |
| index | 获取 Series 的索引,功能类似于 keys() | s.index → Index(['a', 'b', 'c']) |
| name | 获取 Series 的名称 | s.name → 'scores' |
例:
以下例子的文件展示
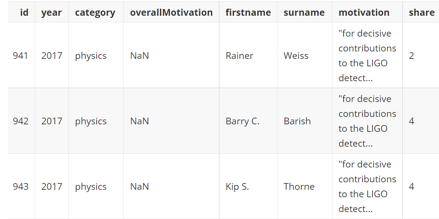
'''
读取csv文件,进行series常用属性的演示
'''
'''1.pd.read_csv()'''
df = pd.read_csv(r"C:\Users\24251\Desktop\employment\02-数据处理和统计分析\数据集\nobel_prizes.csv", index_col='id')
print(df.head())
print(type(df)) # dataframe
# pd.read_csv返回的是df对象,需要转成所要的series,通过获取df的其中一行可以得到series
first_row = df.iloc[0]
print(first_row)
print(type(first_row)) # series
'''2.dtype,dtypes'''
print(first_row.dtype)
print(first_row.dtypes)
'''3.shape'''
print(first_row.shape)
'''4.size'''
print(first_row.size)
'''5.index'''
print(first_row.index)
'''6.values'''
print(first_row.values)
'''7.keys()=values'''
print(first_row.keys())3.常用方法
| 序号 | 方法 / 属性 | 说明 |
|---|---|---|
| 1 | .head(n) | 获取前 n 行数据,默认 n=5 |
| 2 | .tail(n) | 获取后 n 行数据,默认 n=5 |
| 3 | .index | 返回 Series 的行索引(标签) |
| 4 | .values | 返回 Series 的值,类型为 NumPy 数组 |
| 5 | .dtype | 返回元素的数据类型(如 int64, float64, object 等) |
| 6 | .shape | 返回形状,格式为 (n,),n 是元素个数 |
| 7 | .size | 返回元素总数(包括 NaN) |
| 8 | .name | 返回 Series 的名称(如果设置了) |
| 9 | .count() | 返回非空值的数量(自动排除 NaN) |
| 10 | .sum() | 计算所有元素的和(仅数值型) |
| 11 | .mean() | 计算平均值(仅数值型) |
| 12 | .median() | 计算中位数(仅数值型) |
| 13 | .mode() | 返回众数(可能出现多个) |
| 14 | .std() | 计算标准差(仅数值型) |
| 15 | .var() | 计算方差(仅数值型) |
| 16 | .min() | 返回最小值(数值型或可比较类型) |
| 17 | .max() | 返回最大值(数值型或可比较类型) |
| 18 | .abs() | 返回每个元素的绝对值(仅数值型) |
| 19 | .round(decimals) | 对数值四舍五入到指定小数位 |
| 20 | .cumsum() | 计算累积和(仅数值型) |
| 21 | .cumprod() | 计算累积积(仅数值型) |
| 22 | .describe() | 生成描述性统计摘要:<br>• 数值型:count, mean, std, min, 25%, 50%, 75%, max<br>• 类别型:count, unique, top, freq |
| 23 | .value_counts() | 统计每个唯一值的出现频次,结果按频次降序排列,默认排除 NaN |
.describe() 方法详解
| 数据类型 | .describe() 输出内容 |
|---|---|
| 数值型(numeric) | count, mean, std, min, 25%, 50%, 75%, max |
| 类别型/对象型(object) | count, unique, top(出现最多值), freq(最高频次) |
例子:
import pandas as pd
# 创建一个带有索引和名称的 Series
s = pd.Series([10, 20, 30, 40, 50], index=['a', 'b', 'c', 'd', 'e'], name='scores')
print("Series 内容:")
print(s)
print()
# 输出常用方法的结果
print("方法演示:")
print(f"head(3) -->\n{s.head(3)}")
print(f"tail(2) -->\n{s.tail(2)}")
print(f"index --> {s.index}")
print(f"values --> {s.values}")
print(f"dtype --> {s.dtype}")
print(f"shape --> {s.shape}")
print(f"size --> {s.size}")
print(f"name --> {s.name}")
print(f"count() --> {s.count()}")
print(f"sum() --> {s.sum()}")
print(f"mean() --> {s.mean()}")
print(f"median() --> {s.median()}")
print(f"mode() --> {s.mode()}")
print(f"std() --> {s.std()}")
print(f"var() --> {s.var()}")
print(f"min() --> {s.min()}")
print(f"max() --> {s.max()}")
print(f"abs() --> {s.abs()}")
print(f"round(0) --> {s.round(0)}")
print(f"cumsum() --> {s.cumsum()}")
print(f"cumprod() --> {s.cumprod()}")4.series布尔索引
# 1:导包
import pandas as pd
# 2: 读取数据,加载csv文件,返回df对象
df = pd.read_csv(r"C:\Users\24251\Desktop\employment\02-数据处理和统计分析\数据集\scientists.csv")
# print(df.head())
# 3:手动传入布尔值,获取内容
bool_list = [True, False, False, True, False, False, True, True]
print(df[bool_list]) # 获取布尔值对应的行数据,将布尔值为True的数据返回,因此索引:0,3,6,7
print("---------------------------")
# 4: 根据条件传入布尔值,筛选内容
# 需求:筛选出年龄大于平均年龄的科学家。
# 4.1: 获取年龄列的数据
ages_series = df['Age']
print(ages_series)
# 4.2: 计算年龄的平均值
mean_age = ages_series.mean()
print(mean_age) # 59.125 平均年龄
# 4.3:判断当前年龄是否大于平均年龄
"""
0 False
1 True
2 True
3 True
4 False
5 False
6 False
7 True
"""
print(ages_series > mean_age)
print("-----------------------")
# 4.4:获取当前年龄大于平均年龄的行数据
print(ages_series[ages_series > mean_age])
print("-----------------------")
# 4.5:获取当前年龄大于平均年龄的姓名
print(df["Name"][ages_series > mean_age])5.series的运算
1.Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
2.所有二元运算(两个 Series 之间)都会先按索引对齐,再计算,未对齐位置为 NaN
DataFrame
简介
最核心,最常用的数据结构。类似于excel工作表和sql数据库表
1.创建方式
1.字典(最常用)
'''1.字典方式 创建dataframe'''
import pandas as pd
dict_data = {
'name': ['张三', '李四', '王五'],
'age': [18, 19, 20],
'sex': ['男', '女', '男']
}
df1 = pd.DataFrame(dict_data)
print(df1)
print(type(df1))
'''1.1字典方式,index指定行索引,colums指定列顺序,如果列名在字典里不存在,值为nan'''
df2 = pd.DataFrame(dict_data, index=['a', 'b', 'c'], columns=['id', 'age', 'name'])
print(df2)
print(type(df2))2.dataframe属性
| 属性 | 说明 | 示例 |
|---|---|---|
.shape | 返回 DataFrame 的维度,格式为 (行数, 列数) | df.shape → (5, 3) |
.size | 返回 DataFrame 中元素的总个数(行 × 列) | df.size → 15 |
.ndim | 返回数据的维度数,DataFrame 为 2 | df.ndim → 2 |
.index | 返回行索引(行标签),可为默认 RangeIndex 或自定义标签 | df.index → RangeIndex(start=0, stop=5, step=1) |
.columns | 返回列索引(列名),是所有列的标签 | df.columns → Index(['A', 'B', 'C'], dtype='object') |
.values | 返回 DataFrame 的所有数据,类型为 NumPy 二维数组 | df.values → [[1,2,3], [4,5,6], ...] |
.dtypes | 返回每列的数据类型,返回一个 Series | df.dtypes → A int64<br> B float64<br> C object |
.empty | 判断 DataFrame 是否为空(无元素或全为空) | df.empty → False |
.T 或 .transpose() | 返回转置后的 DataFrame(行列互换) | df.T → 行变为列,列变为行 |
.axes | 返回一个列表,包含 .index 和 .columns | df.axes → [Index([...]), Index([...])] |
.memory_usage() | 返回每列占用的内存大小(字节),可查看内存使用情况 | df.memory_usage() → 各列内存占用 |
3.dataframe方法
| 方法 | 说明 | 示例 |
|---|---|---|
.head(n) | 查看前 n 行数据(默认 n=5) | df.head(3) |
.tail(n) | 查看后 n 行数据(默认 n=5) | df.tail(2) |
.info() | 显示 DataFrame 的结构信息:列名、非空值数量、数据类型、内存使用等 | df.info() |
.describe() | 生成数值列的描述性统计:计数、均值、标准差、最小值、四分位数、最大值 | df.describe() |
.describe(include='all') | 对所有列(包括类别型)进行统计 | df.describe(include='all') |
.dtypes | 返回每列的数据类型(属性,但常与方法并用) | df.dtypes |
.columns | 返回列名索引(属性) | df.columns |
.shape | 返回维度(属性) | df.shape |
.isnull() | 返回布尔 DataFrame,标记 NaN 位置 | df.isnull() |
.notnull() | 返回布尔 DataFrame,标记非 NaN 位置 | df.notnull() |
.dropna() | 删除包含 NaN 的行或列 | df.dropna()<br>df.dropna(axis=1) 删除含空列 |
.fillna(value) | 填充 NaN 值 | df.fillna(0)<br>df.fillna(method='ffill') 向前填充 |
.drop(columns=['A', 'B']) | 删除指定列 | df.drop(columns='Age') |
.drop_duplicates() | 删除重复行 | df.drop_duplicates() |
.duplicated() | 返回布尔 Series,标记重复行 | df.duplicated() |
.sort_values(by, ascending=True) | 按某列或多列排序 | df.sort_values('Age', ascending=False) |
.groupby(by) | 按列分组,用于聚合操作 | df.groupby('City').mean() |
.agg() | 聚合操作,可指定多个函数 | df.groupby('City').agg(['mean', 'sum']) |
.value_counts() | 用于 Series,统计每列值频次(常用于类别列) | df['Gender'].value_counts() |
.nunique() | 返回每列唯一值个数 | df.nunique() |
.query(expr) | 使用字符串表达式筛选数据 | df.query('Age > 25 and Salary < 10000') |
.loc[行标签, 列标签] | 按标签选择数据 | df.loc[0, 'Name']<br>df.loc[:, 'Age'] |
.iloc[行位置, 列位置] | 按整数位置选择数据 | df.iloc[0, 1]<br>df.iloc[1:3, :] |
.assign(新列=值) | 创建新列并返回新 DataFrame | df.assign(BMI=df['Weight']/df['Height']**2) |
.rename(columns={...}) | 重命名列名 | df.rename(columns={'A': 'Col1'}) |
.astype(dtype) | 转换数据类型 | df['Age'].astype(str) |
.apply(func) | 对每列或每行应用函数 | df[['Age']].apply(np.mean) |
.merge(df2, on=...) | 类似 SQL 的合并操作 | pd.merge(df1, df2, on='ID') |
.concat([df1, df2]) | 沿轴连接多个 DataFrame | pd.concat([df1, df2], axis=0) |
.to_csv('file.csv') | 导出为 CSV 文件 | df.to_csv('data.csv', index=False) |
.to_excel('file.xlsx') | 导出为 Excel 文件 | df.to_excel('data.xlsx', sheet_name='Sheet1') |
.read_csv() / .read_excel() | 读取数据(类方法) | pd.read_csv('data.csv') |
4.dataframe的布尔索引
以下演示的前五行内容如下
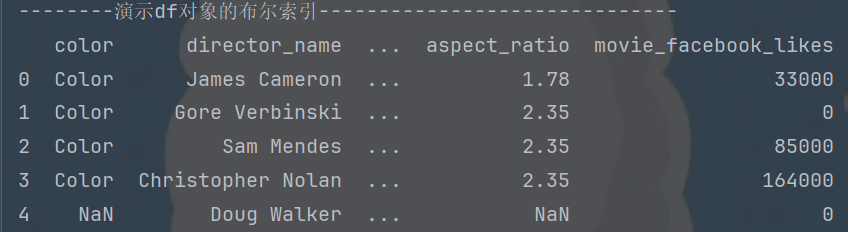
print("--------演示df对象的布尔索引------------------------------")
# 需求:查找movie.csv中,电影时长>平均时长的电影信息
# 1:读取movie.csv文件
movie_df = pd.read_csv(r"C:\Users\24251\Desktop\employment\02-数据处理和统计分析\数据集\movie.csv")
print(movie_df.head())
print(movie_df.duration.mean())
# 2:获取符合条件的数据,即:电影时长>平均时长的电影信息
result = movie_df[movie_df.duration > movie_df.duration.mean()]
# 3:打印符合条件的电影名字和电影时长数据
print(result[["director_name", 'duration']].head())
print("===================")
print(result.head()[[True, False, True, True, False]]) # head默认打印五条,可以通过true或者false控制打印的行索引5.dataframe的运算
- 当DataFrame和数值进行运算时,DataFrame中的每一个元素会分别和数值进行运算
- 字符串与数字不可相加
- 两个DataFrame之间进行计算,会根据索引进行对应计算
- 两个DataFrame会根据索引进行计算,索引不匹配的会返回NaN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号