


Spring生命周期大揭秘:你的Bean到底经历了什么? - 实践

Spring框架的核心设计哲学在于控制反转(IoC)和依赖注入(DI),而理解Bean的生命周期是掌握这一哲学的关键——资深Spring框架贡献者Juergen Hoeller曾如此强调其重要性。
摘要
大家好,我是 励志成为糕手!上一篇我们讲了Spring IOC容器,让我们对spring入门有了一个粗略的框架,今天我们来着重分析 Spring Bean 的生命周期。不难发现,在日常开发和面试辅导中,许多开发者虽然能背诵Spring生命周期的基本阶段,却难以解释三级缓存如何解决循环依赖,或不清楚@PostConstruct与InitializingBean的执行顺序差异。这种理解断层常导致性能问题、资源泄漏甚至生产环境故障。
本文将深入Spring的核心运行机制,通过源码级分析、可视化流程图和实战代码示例,带你全方位解析Bean从创建到销毁的完整旅程。无论你是遭遇过诡异的循环依赖问题,还是希望优化应用启动性能,这篇文章都将提供清晰的解决路径。
一、Bean生命周期全景
Spring Bean的生命周期本质上是容器管理对象的过程,可分为四个核心阶段:实例化(Instantiation)→ 属性赋值(Populate)→ 初始化(Initialization)→ 销毁(Destruction)9。这与Spring源码中的doCreateBean()方法结构直接对应:
// 简化的Spring源码逻辑
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, Object[] args) {
// 1. 实例化阶段
BeanWrapper instanceWrapper = createBeanInstance(beanName, mbd, args);
// 2. 属性赋值阶段
populateBean(beanName, mbd, instanceWrapper);
// 3. 初始化阶段
exposedObject = initializeBean(beanName, exposedObject, mbd);
return exposedObject;
}
// 销毁在容器关闭时触发:ConfigurableApplicationContext.close()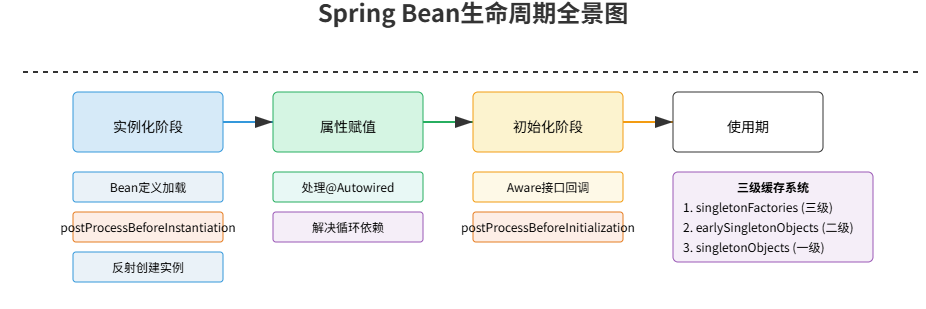
图1:Bean生命周期核心阶段的源码映射(基于Spring 5.x)
不同作用域的生命周期差异
| 生命周期特性 | Singleton Bean | Prototype Bean |
|---|---|---|
| 创建时机 | 容器启动时创建 | 每次getBean()时创建 |
| 缓存位置 | 单例池(singletonObjects) | 不缓存 |
| 销毁管理 | 容器关闭时销毁 | 不管理,依赖GC回收 |
| 循环依赖支持 | 三级缓存支持 | 不支持 |
表1:单例与原型Bean的生命周期对比
ps:这里singleton是单例模式,而prototype是原型模式,每次使用时创建。
二、实例化阶段:Bean的诞生
实例化是Bean生命周期的起点,Spring通过反射机制调用构造方法创建对象。此阶段的核心步骤包括:
1. 构造方法推断策略
存在
@Autowired注解的构造器 → 优先使用无注解时选择无参构造器
既无注解又无无参构造 → 抛出BeanInstantiationException
2. 三级缓存提前曝光
为解决循环依赖,Spring在实例化后立即将原始对象包装成ObjectFactory放入三级缓存:
// 三级缓存定义
Map singletonObjects = new ConcurrentHashMap<>(); // 一级缓存:完整Bean
Map earlySingletonObjects = new ConcurrentHashMap<>(); // 二级缓存:早期引用
Map> singletonFactories = new HashMap<>(); // 三级缓存:对象工厂3. 实例化扩展点
InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()
在实例化前执行,可返回代理对象替换目标BeanInstantiationAwareBeanPostProcessor.postProcessAfterInstantiation()
在实例化后执行,可阻断属性填充阶段

图2:实例化阶段的扩展点与流程
三、属性赋值与依赖注入
属性赋值阶段的核心任务是解决依赖关系,Spring提供三种注入方式:
1. 注入方式优先级
构造器注入(Constructor Injection) - 强依赖性首选
Setter注入(Setter Injection) - 可选依赖
字段注入(Field Injection) - 不推荐(破坏封装性)
@Component
public class OrderService {
// 构造器注入(Spring 4.3+可省略@Autowired)
private final PaymentService paymentService;
@Autowired
public OrderService(PaymentService paymentService) {
this.paymentService = paymentService;
}
}2. 循环依赖解决机制
当Bean A依赖Bean B,而Bean B又依赖Bean A时:
A实例化 → 将ObjectFactory放入三级缓存
A属性注入需要B → 触发B创建
B实例化 → 将ObjectFactory放入三级缓存
B属性注入需要A → 从三级缓存获取A的早期引用
B完成初始化 → 移入一级缓存
A获得完整B实例 → 完成初始化
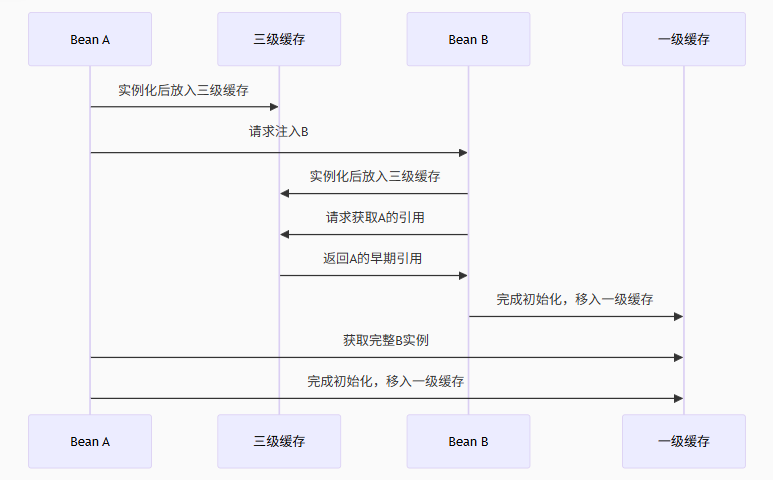
图3:循环依赖解决序列图
关键限制:Spring只能解决通过setter/字段注入的单例Bean循环依赖。构造器注入的循环依赖无法解决,需使用
@Lazy或重构代码。
四、初始化阶段:Bean的成人礼
初始化是Bean投入使用前的最后准备,包含以下有序步骤:
1. Aware接口回调
Spring通过Aware接口向Bean注入容器基础设施:
public class SystemMonitor implements ApplicationContextAware {
private ApplicationContext context;
@Override
public void setApplicationContext(ApplicationContext ctx) {
this.context = ctx; // 获得ApplicationContext引用
}
}Aware接口执行顺序:
BeanNameAware → 设置Bean ID
BeanClassLoaderAware → 设置类加载器
BeanFactoryAware → 设置BeanFactory
ApplicationContext相关Aware(EnvironmentAware、ResourceLoaderAware等)
2. 初始化方法执行顺序
@PostConstruct注解方法 - JSR-250标准
InitializingBean.afterPropertiesSet() - Spring接口
自定义init-method - XML/@Bean指定
@Component
public class DatabaseInitializer {
@PostConstruct // 1. 最先执行
public void initAnnotation() {
System.out.println("@PostConstruct方法执行");
}
@Override // 2. 其次执行
public void afterPropertiesSet() {
System.out.println("InitializingBean.afterPropertiesSet()执行");
}
@Bean(initMethod = "customInit") // 3. 最后执行
public void customInit() {
System.out.println("自定义init-method执行");
}
}3. BeanPostProcessor的魔法
这是Spring扩展能力最强的接口,作用于初始化前后:
@Component
public class CustomBeanPostProcessor implements BeanPostProcessor {
// 初始化前调用
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
System.out.println(beanName + "初始化前处理");
return bean;
}
// 初始化后调用(AOP代理在此生成)
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof OrderService) {
return Proxy.newProxyInstance(/*创建代理*/);
}
return bean;
}
}性能提示:BeanPostProcessor作用于所有Bean,实现时应通过beanName/类型判断避免无谓处理。
五、销毁阶段:Bean的优雅退场
当容器关闭时(调用close()),单例Bean进入销毁阶段,执行顺序为:
@PreDestroy注解方法 - JSR-250标准
DisposableBean.destroy() - Spring接口
自定义destroy-method - XML/@Bean指定
@Component
public class ResourceCleanup implements DisposableBean {
@PreDestroy // 1. 最先执行
public void preDestroy() {
System.out.println("@PreDestroy方法执行");
}
@Override // 2. 其次执行
public void destroy() {
System.out.println("DisposableBean.destroy()执行");
}
@Bean(destroyMethod = "customCleanup") // 3. 最后执行
public void customCleanup() {
System.out.println("自定义destroy-method执行");
}
}注意:在销毁方法中释放数据库连接、文件句柄等资源,避免内存泄漏。
六、生命周期中的特殊场景处理
1. 循环依赖的深度解析
三级缓存设计的精妙之处在于:
一级缓存(singletonObjects):存放完整Bean,避免重复创建
二级缓存(earlySingletonObjects):暂存早期引用,避免重复生成代理
三级缓存(singletonFactories):延迟决定返回原始对象还是代理
2. 作用域对生命周期的影响
Request/Session作用域:Bean生命周期绑定到HTTP请求/会话
@RefreshScope(配置热更新):
配置变更时调用
destroy()清理旧Bean下次请求时重新初始化
七、生命周期优化实践
1. 启动加速策略
延迟初始化:
@Lazy注解延迟非关键Bean创建分阶段初始化:
@DependsOn控制初始化顺序避免过度使用BeanPostProcessor:其在每个Bean初始化时都会执行
2. 资源泄漏预防
@Component
public class DatabaseConnectionPool implements DisposableBean {
private List connections = new ArrayList<>();
@PostConstruct
public void init() throws SQLException {
// 初始化连接池
for(int i=0; i<10; i++){
connections.add(DriverManager.getConnection("jdbc:url"));
}
}
@Override
public void destroy() {
// 确保关闭所有连接
for(Connection conn : connections) {
try { conn.close(); }
catch (SQLException ex) { /*日志记录*/ }
}
}
}3. 生命周期监控实现
通过自定义BeanPostProcessor注入监控逻辑:
public class MonitoringBeanPostProcessor implements BeanPostProcessor {
private Map initTimes = new ConcurrentHashMap<>();
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
initTimes.put(beanName, System.currentTimeMillis());
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
Long start = initTimes.get(beanName);
if (start != null) {
long cost = System.currentTimeMillis() - start;
System.out.printf("Bean [%s] 初始化耗时 %d ms%n", beanName, cost);
}
return bean;
}
}八、总结:掌握生命周期的价值
理解Spring Bean生命周期不是学术演习,而是解决实际工程问题的关键钥匙。通过本文的深度剖析,我们能够:
精准诊断启动问题 - 当应用启动缓慢时,通过初始化阶段监控定位耗时Bean
避免循环依赖陷阱 - 理解三级缓存机制,在架构设计时合理规划依赖方向
高效管理资源 - 在销毁阶段可靠释放连接、文件句柄等稀缺资源
扩展Spring能力 - 通过BeanPostProcessor等扩展点实现AOP、监控等高级功能
Spring的设计哲学体现在它的扩展性与一致性中——Bean生命周期的每个阶段都提供了精确的干预点,开发者无需修改框架即可实现深度定制。
在微服务和云原生时代,Spring Boot基于这些生命周期机制实现了自动配置(Auto-configuration)、健康检查(Health Check) 等特性。掌握这些基础原理,能让我们在复杂系统调试和性能优化中游刃有余。
参考资料:
我是 励志成为糕手 ,感谢你与我共度这段技术时光!
✨ 如果这篇文章为你带来了启发:
✅ 【收藏】关键知识点,打造你的技术武器库
【评论】留下思考轨迹,与同行者碰撞智慧火花
【关注】持续获取前沿技术解析与实战干货技术探索永无止境,让我们继续在代码的宇宙中:
• 用优雅的算法绘制星图
• 以严谨的逻辑搭建桥梁
• 让创新的思维照亮前路
保持连接,我们下次太空见!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号