

Hive常用函数总结
1.数值函数
(1).round() 四舍五入
(2).ceil() 向上取整
(3).floor() 向下取整
2.字符串函数
(1).substring() 字符串截取
该函数一共有三个参数
1).第一个参数表示要截取的字符串
2).第二个参数表示截取的起始位置,可以匹配instr使用
3).第三个函数是一个可选参数,表示要截取的长度,如果不写,则表示截取到最后的一位。
(2).replace(): 替换函数
(3).regexp_replace(): 正则替换
根据正则表达式替换匹配上的字符串为另外的字符串
如:select regexp_replace(“wod122”,”\d+”,”你好”);
将字符串中的数字替换为“你好”
(4).regexp() 正则匹配函数
语法:字符 regexp 需要匹配的正则表达式
如:select “adb123” regexp “\d+$”;
匹配以数字结尾的字符串,如果可以匹配上这返回true
(5).split(str,key): 切割字符串
将字符串str,根据key进行切割,返回一个字符串数组,这里的key是一个正则表达式
select split(“adfd1213adfs”,”\d+”);
--["adfd","adfs"]
(6).nvl(x,y). 空值替换函数
如果x为空,则默认值为y
如:select nvl(null,4); -- 4
将null替换为4
(7).concat() 字符串拼接函数
语法:concat(str1,str2,…)
(8).concat_ws(key,str1,str2,…)
将key后面参数的所有字符串,使用key分隔拼接
(9).get_json_object(str,y) 操作json的函数
Str: 为要操作的json
y:为要获取的key,如果是json数组则需要使用$[x],key的方式去访问
如:select get_json_object('[{"name":"年后"},{"name":"昊天"}]',"$[1].name");
--昊天
3.日期函数
(1).unix_timestamp[x]
返回当前时间或指定时间的时间戳
select unix_timestamp();-- 返回当前的时间戳
如果传入时间,那么返回传入参数的时间戳,返回的是0时区的时间
(2).from_unixtime(longtime,temp)
将时间戳转换模版的时间格式
如:select from_unixtime(1730821688,'yyyy-MM-dd HH:mm:ss');
--2024-11-05 15:48:08
返回的是0时区的时间
(3).from_utc_timestamp(longtime,时区字符串)
将指定的时间戳转换为指定的时区的时间
如:select from_utc_timestamp(cast(1730821688 as bigint) * 1000,"GMT+8")
-- 2024-11-05 23:48:08.000000000
(4).current_date()
返回当前的系统日期
(5). current_timestamp()
返回当前系统的时间,这里的时间包括时分秒,并且获取的是当前机器所在的时区的时间
(6).month(): 获取日期的月份
(7).day(): 获取日期的天
(8).hour(): 获取指定日期的小时
(9).year(): 返回给定的时间的年份
(10).datediff(t1,t2)
获取给定两个时间的相差的天数
是使用第一个时间减去第二个时间
(11).date_add(date,countday) 日期加一个天数
(12). date_format(date,key)
将给定的时间,转换为指定时间的模版格式
4.流程控制函数
(1).case when 多分支函数
select stu_id,
course_id,
case
when score <= 60 then "不及格"
when score < 80 then "及格"
when score >= 80 then "优秀"
else "不存在"
end
from score_info;
(2).if单分支函数
select stu_id,
course_id,
if(score>=80,"优秀","不及格") as haha
from score_info;
5.复杂类型函数
(1).array()数组数组构造函数
select `array`(1,2,3,4,5)
--[1,2,3,4,5]
(2).array_contains(array,x)
判断一个元素是否在数组中,如果存在就返回true,否则返回flase
如:判断5是否在数组中
Select array_contains(array(1,2,3,4,5))
(3).sort_array()
给数组排升序,而且无法修改排序的方式(以及只能排升序)
select sort_array(`array`(1,5,3,4,2))
--[1,2,3,4,5]
(4).size()获取数组的长度
(5).map(key1,value1,key2,value2,…)
Map构造函数
如:select map(“hadoop”,1,”flink”,2)
(6).map_keys()获取map的所有key
(7).map_values()获取map的所有key
(8).struct()结构体函数
创建结构体,无需传入结构体的字段名称
如:select struct("hadoop","flink","java")
--{"col1":"hadoop","col2":"flink","col3":"java"}
(9).named_struct(字段名称1,值1,字段名称2,值2,…)
如:select named_struct("name","小顾","age",34)
6.高级聚合函数
(1).collect_list()
将查询的列聚合在一个list集合中
如:select collect_list(job) from employee;
-- ["销售","行政","研发","研发","销售","行政","前台","前台"]
(2).collect_set()
将制定列的内容聚合在set集合中,并去重
如:select collect_set(job) from employee;
-- ["销售","行政","研发","前台"]
7.UDTF函数
(1).explode(arr) 接收数组时
将一个数组炸裂为多行,及:一行输出多行
类似于Spark中的flatMap的扁平化操作
如:select explode(`array`(1,2,3,4,7))
--
1
2
3
4
7
(2).explode(map) 传入map
会将key和value分别炸裂为两列的多行元素
(3).posexplode(array)
会在explode基础上返回每一行在数组中的索引
如:select posexplode(`array`(1,2,6,3))
--
0,1
1,2
2,6
3,3
(4).inline(array(struct()))
将结构体数组转换为一张表的数据,如果不使用as修改字段名称,默认使用结构体的字段名
(5).lateral view()
一般情况会配合UDTF函数使用。
如:select name,sex,friends,friends_temp from employee lateral view explode(friends) temp_table_name as friends_temp;
其中:temp_table_name为每一个行炸裂后的表的临时名称
friends_temp炸裂后字段,可能代表多个字段
结果如下:

8.窗口函数
(1).基于行的窗口函数
函数() over(范围)
基于行的是指:上一行到当前行
如:sum(score) over (order by score rows between unbounded preceding and current row )
这里的先根据score排序升序,然后再重第一行到当前行就和得到的结果如下:

可以任意指定范围。
(2).基于值的窗口函数
基于值的窗口函数与基于行的窗口函数语法类似,只是窗口函数的关键字rows变为了range

当窗口的范围涉及到加减等计算操作时,指定的排序列及计算窗口的列必须是数值类型。
(3).lead() over() 和 lag() over()
1.lead获取当前行的下边某一行的某一列的值。
2.lag获取当前行上边某一行的某一列的值。
如:
select *,lead(score,1) over(partition by stu_id order by score) as temp_score from score_info;
这里的lead(score,1)表示获取score的列下边一行的值
注意:lag和lead窗口函数不支持自定义窗口的范围

(4).first_value() 和 last_value()
First_value获取当前窗口的第一行的值,
Last_value获取当前窗口中第一行到当前行的最后一行,及当前行。
如:
select *
, first_value(score,false) over (partition by stu_id order by score) as first_temp
, last_value(score,false) over (partition by stu_id order by score) as last_temp
from score_info;
这里的first_value(score,false)中,score表示要获取值的列,false表示一个booler值,表示是否要跳过空值
结果如下:

(5).row_number() over()
排名函数,可以给每一行一个排名,如果值相同时,排名不会相同。
语法:row_number() over(partition by 分组的字段 order by 排序的字段 排序方式)。
如:
select t.*,row_number () over(partition by stu_id order by score desc) as rank_temp from score_info t;
结果如下:
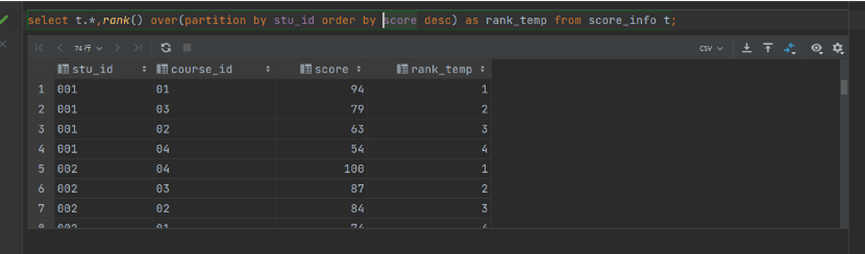
(6).dense_rank() over() 和 rank() over()
排名函数,可以给每一行给一个排名,如果值相同时,排名相同。
dense_rank不会跳过排名,排名是连续的,而rank()会跳过排名。
如: 1,2,2,3
dense_rank的排名为: 1,2,2,3;
而rank()的排名为:1,2,2,4
语法:dense_rank() over(partition by 分组的字段 order by 排序的字段 排序方式)
如:
select t.*,dense_rank() over(partition by stu_id order by score desc) as rank_temp from score_info t;
结果如下:

本文来自博客园,作者:业余砖家,转载请注明原文链接:https://www.cnblogs.com/yeyuzhuanjia/p/18908053

 浙公网安备 33010602011771号
浙公网安备 33010602011771号