

pymssql连接SQLServer数据库查询出的中文为乱码
问题描述:
执行如下代码时出现报错问题,输出的内容本应为中文,但是输出为乱码。
#coding=utf8 import pymssql import pandas as pd # 数据库连接配置 config = { "server": host, "port": port, "user": user, "password": password, "database": database, "charset": "utf8" } conn = pymssql.connect(**config) query = f""" SELECT ep.value AS column_comment FROM sys.columns c LEFT JOIN sys.extended_properties ep ON ep.major_id = c.object_id AND ep.minor_id = c.column_id AND ep.name = 'MS_Description' WHERE c.object_id = OBJECT_ID('StopRecord') ORDER BY c.column_id """ df = pd.read_sql_query(query, conn) print(df.to_string())
执行结果如下所示:

说明:
网上有人建议将 "charset": "utf8" 改为 "charset": "cp936" ,经过验证并不管用。
解决办法:
(1)将SQL语句将varchar转为nvarchar类型
这里我新添加了一列: convert(nvarchar(50), ep.value) AS column_comment2 ,对比看下效果。
SELECT ep.value AS column_comment, convert(nvarchar(50), ep.value) AS column_comment2 FROM sys.columns c LEFT JOIN sys.extended_properties ep ON ep.major_id = c.object_id AND ep.minor_id = c.column_id AND ep.name = 'MS_Description' WHERE c.object_id = OBJECT_ID('StopRecord') ORDER BY c.column_id
查看效果:
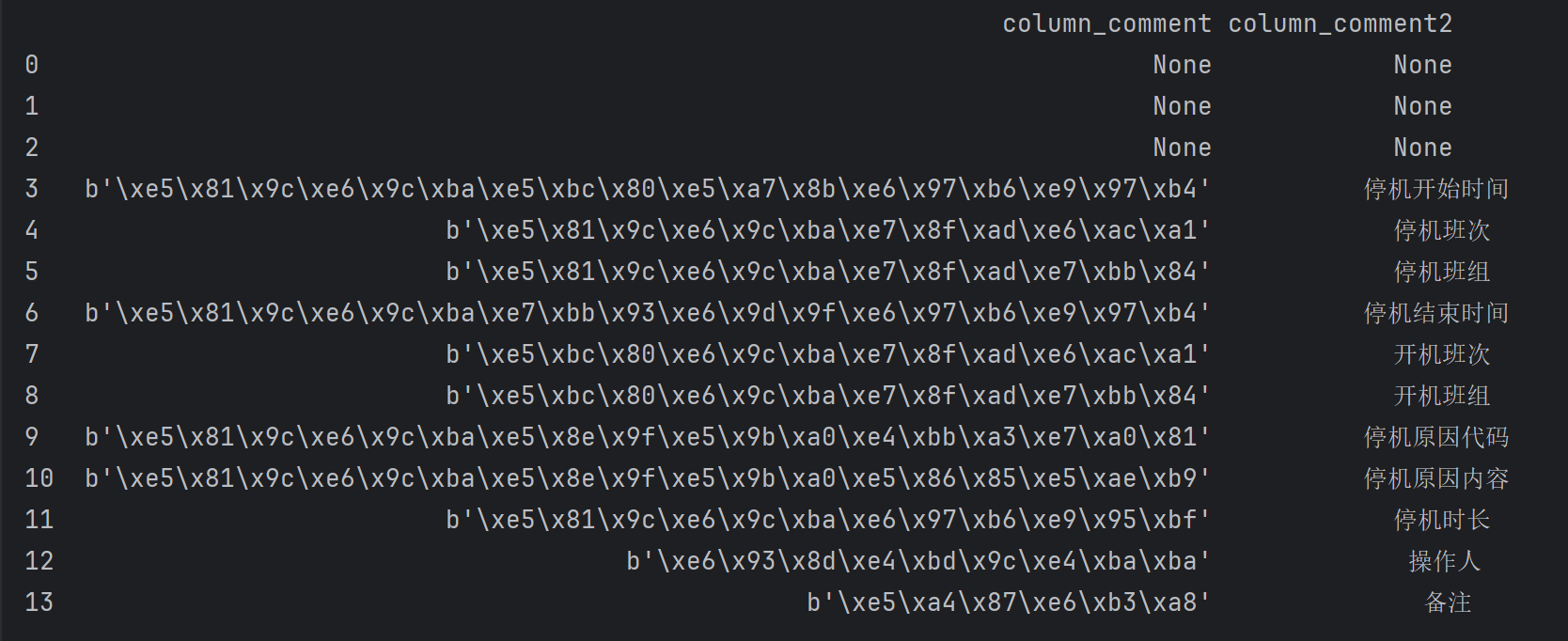
(2)将含有中文的列手动解码
将返回的DataFrame进行解码,添加如下一行:
# 若数据库返回字节流(bytes),需手动解码 df['column_comment'] = df['column_comment'].apply(lambda x: x.decode('utf-8') if isinstance(x, bytes) else x)
完整代码:
#coding=utf8 import pymssql import pandas as pd # 数据库连接配置 config = { "server": host, "port": port, "user": user, "password": password, "database": database, "charset": "utf8" } conn = pymssql.connect(**config) query = f""" SELECT ep.value AS column_comment FROM sys.columns c LEFT JOIN sys.extended_properties ep ON ep.major_id = c.object_id AND ep.minor_id = c.column_id AND ep.name = 'MS_Description' WHERE c.object_id = OBJECT_ID('StopRecord') ORDER BY c.column_id """ df = pd.read_sql_query(query, conn) # 若数据库返回字节流(bytes),需手动解码 df['column_comment'] = df['column_comment'].apply(lambda x: x.decode('utf-8') if isinstance(x, bytes) else x) print(df.to_string())
效果:

(3)使用pyodbc替换pymssql
前提:
1、安装 ODBC Driver 17 for SQL Server
2、安装pyodbc
3、代码
import pyodbc import pandas as pd # 数据库连接配置 host = "host" port= 1433 user = "username" password = "password" database = "database" # 构建连接字符串 conn_str = ( f"DRIVER={{ODBC Driver 17 for SQL Server}};" f"SERVER={host};" f"PORT={port};" f"DATABASE={database};" f"UID={user};" f"PWD={password};" f"charset=UTF-8;" # 关键参数 f"unicode_results=True;" # 关键参数 f"autocommit=True" ) conn = pyodbc.connect(conn_str) query = f""" SELECT ep.value AS column_comment FROM sys.columns c LEFT JOIN sys.extended_properties ep ON ep.major_id = c.object_id AND ep.minor_id = c.column_id AND ep.name = 'MS_Description' WHERE c.object_id = OBJECT_ID('StopRecord') ORDER BY c.column_id """ df = pd.read_sql_query(query, conn) print(df.to_string())
查看效果:

本文来自博客园,作者:业余砖家,转载请注明原文链接:https://www.cnblogs.com/yeyuzhuanjia/p/18876073

 浙公网安备 33010602011771号
浙公网安备 33010602011771号