

MySQL窗口函数详解
一、窗口函数的组成部分
(1)窗口函数本身:这是执行计算的函数,如 SUM(), AVG(), ROW_NUMBER() 等。
(2)OVER子句:定义了窗口函数的计算范围。它由三部分组成:
①、PARTITION BY:将数据集分成多个独立的组,每个组内部进行计算。如果省略,整个数据集被视为一个单一的分区。
②、ORDER BY:在每个分区内对数据进行排序,这会影响某些窗口函数的计算结果,如 ROW_NUMBER(), RANK() 等。
③、ROWS或RANGE:定义了窗口的物理大小,即函数作用的行数范围。ROWS 是基于行号的,而 RANGE 是基于值的范围。
(3)窗口框架(Frame):在某些窗口函数中,你可以通过窗口框架进一步细化窗口的大小。窗口框架可以是静态的(如 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)或动态的(如 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)。
二、窗口函数的类型
(1)排名函数:如 ROW_NUMBER(), RANK(), DENSE_RANK(),它们为分区内的每一行分配一个唯一的序号或排名。
(2)聚合函数:如 SUM(), AVG(), MIN(), MAX() ,它们计算分区内所有行的聚合值。
(3)偏移函数:如 LEAD(), LAG(),它们允许你访问当前行的前面或后面的行的值。
(4)首尾函数:如 FIRST_VALUE(),LAST_VALUE(),NTH_VALUE() ,它们允许你访问当前窗口的首行、末行、第N行的值。
(5)分布函数:如 PERCENT_RANK(),NTILE(),CUME_DIST(),它们用于分析数据的分布特征或分组排名。
|
分类 |
函数 |
功能 |
|
排名窗口 |
ROW_NUMBER() |
计算行号。为每一行分配一个唯一的整数,从1开始递增。 |
|
RANK() |
计算排名,排名可能不连续。对每一行进行排名,当遇到相同值时,排名会跳过一些数字。 |
|
|
DENSE_RANK() |
计算排名,排名是连续的。对每一行进行排名,但不会跳过排名数字,即使遇到相同值。 |
|
|
聚合窗口 |
MAX(列名) |
计算窗口中的最大值。 |
|
MIN(列名) |
计算窗口中的最小值。 |
|
|
SUM(列名) |
对窗口中的数据求和。 |
|
|
AVG(列名) |
对窗口中的数据求平均值。 |
|
|
COUNT(列名) |
计算窗口中的记录数。 |
|
|
STDDEV(列名) |
计算总体标准差。使用公式 S = sqrt(sum((x_i - x_bar)^2) / N),其中 N 是样本中的数据点数量。 |
|
|
STDDEV_SAMP(列名) |
计算样本标准差。使用公式 S = sqrt(sum((x_i - x_bar)^2) / (N - 1)),其中 N 是样本中的数据点数量。 |
|
|
偏移(前后取值)窗口 |
LAG(列名,行数) |
取当前行往前(朝分区头部方向)第N行数据的值。 |
|
LEAD(列名,行数) |
取当前行往后(朝分区尾部方向)第N行数据的值。 |
|
|
首尾取值窗口 |
FIRST_VALUE(列名) |
取窗口内第一行的值。 |
|
LAST_VALUE(列名) |
取窗口内最后一行的值。 |
|
|
NTH_VALUE(列名,N) |
取窗口内第N行的值。 |
|
|
分布窗口 |
PERCENT_RANK() |
计算行的百分比排名。输出百分比格式。 |
|
CUME_DIST() |
计算行相对于所有其他行的累积分布。 |
|
|
NTILE(N) |
将数据顺序切分成N等份,返回数据所在等份的编号(从1到N)。 |
三、窗口函数的分区和排序
(1)PARTITION BY:这个子句将结果集分成多个独立的分区,每个分区都是一个独立的数据集,窗口函数在每个分区上独立计算。例如,如果你按部门对员工数据进行分区,每个部门将有自己的窗口函数计算结果。
(2)ORDER BY:这个子句在每个分区内对行进行排序。对于排名函数,ORDER BY 子句决定了行的排名顺序。对于聚合函数,ORDER BY 子句决定了窗口的计算顺序。
四、窗口函数的窗口框架
(1)ROWS:基于行号的窗口框架,可以是固定的行数(如 ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING),也可以是相对于当前行的位置(如 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)。
(2)RANGE:基于值的范围的窗口框架,它允许你基于列的值来定义窗口的大小。例如,RANGE BETWEEN 0 PRECEDING AND 0 FOLLOWING 会创建一个窗口,其中包含当前行和与当前行具有相同值的行。
rows或(range)子句往往来控制窗口边界范围,基本语法:
CURRENT ROW:当前行;
n PRECEDING:往前n行数据;
n FOLLOWING:往后n行数据;
UNBOUNDED PRECEDING: 表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点
默认框架:
range BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
示例:
rows between 2 preceding and current row # 取本行和前面两行(总共3行)
rows between unbounded preceding and current row # 取本行和之前所有的行
rows between current row and unbounded following # 取本行和之后所有的行
rows between 3 preceding and 1 following # 从前面三行和下面一行,总共五行
# 当order by后面没有rows between时,窗口规范默认是取本行和之前所有的行
# 当order by和rows between都没有时,窗口规范默认是分组下所有行(rows between unbounded preceding and unbounded following)
五、窗口函数示例
创建表
CREATE TABLE `emp` ( `empno` bigint DEFAULT NULL COMMENT '员工编号', `ename` varchar(20) DEFAULT NULL COMMENT '员工姓名', `job` varchar(20) DEFAULT NULL COMMENT '职位', `mgr` bigint DEFAULT NULL COMMENT '上级经理的员工编号', `hiredate` datetime DEFAULT NULL COMMENT '入职日期', `sal` bigint DEFAULT NULL COMMENT '基本工资', `comm` bigint DEFAULT NULL COMMENT '奖金', `deptno` bigint DEFAULT NULL COMMENT '部门编号' ) ;
插入数据
INSERT INTO `emp`(`empno`, `ename`, `job`, `mgr`, `hiredate`, `sal`, `comm`, `deptno`) VALUES (7369, 'SMITH', 'CLERK', 7902, '1980-01-02 00:00:00', 800, 0, 20), (7499, 'ALLEN', 'SALESMAN', 7698, '1981-01-02 00:00:00', 1600, 300, 30), (7521, 'WARD', 'SALESMAN', 7698, '1981-01-02 00:00:00', 1250, 500, 30), (7566, 'JONES', 'MANAGER', 7839, '1981-01-04 00:00:00', 2975, 0, 20), (7654, 'MARTIN', 'SALESMAN', 7698, '1981-01-09 00:00:00', 1250, 1400, 30), (7698, 'BLAKE', 'MANAGER', 7839, '1981-01-05 00:00:00', 2850, 0, 30), (7782, 'CLARK', 'MANAGER', 7839, '1981-01-06 00:00:00', 2450, 0, 10), (7788, 'SCOTT', 'ANALYST', 7566, '1987-01-04 00:00:00', 3000, 0, 20), (7839, 'KING', 'PRESIDENT', NULL, '1981-01-01 00:00:00', 5000, 0, 10), (7844, 'TURNER', 'SALESMAN', 7698, '1981-01-09 00:00:00', 1500, 0, 30), (7876, 'ADAMS', 'CLERK', 7788, '1987-01-05 00:00:00', 1100, 0, 20), (7900, 'JAMES', 'CLERK', 7698, '1981-01-02 00:00:00', 950, 0, 30), (7902, 'FORD', 'ANALYST', 7566, '1981-01-02 00:00:00', 3000, 0, 20), (7934, 'MILLER', 'CLERK', 7782, '1982-01-01 00:00:00', 1300, 0, 10), (7948, 'JACCKA', 'CLERK', 7782, '1981-01-04 00:00:00', 5000, 0, 10), (7956, 'WELAN', 'CLERK', 7649, '1982-01-07 00:00:00', 2450, 0, 10), (7956, 'TEBAGE', 'CLERK', 7748, '1982-01-02 00:00:00', 1300, 0, 10);
1、排名窗口函数(ROW_NUMVER、RANK、DENSE_RANK)
(1).ROW_NUMVER()
作用: 计算行号。为每一行分配一个唯一的整数,从1开始递增。(编号在组内连续并且唯一)
示例:
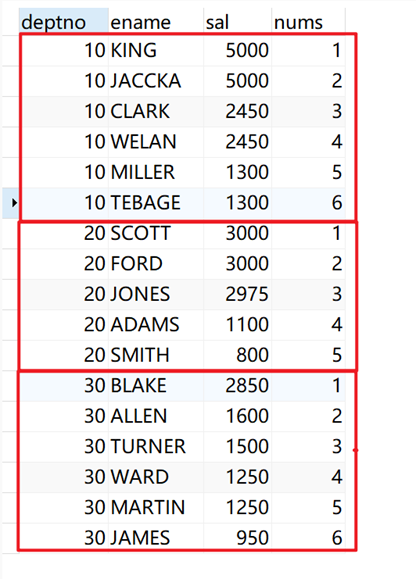
将所有职工根据部门(deptno)分组(作为开窗列),每个组内根据薪水(sal)做降序排序,获得职工在自己组内的序号:
SELECT deptno, ename, sal, row_number() over ( PARTITION BY deptno ORDER BY sal DESC ) AS nums FROM emp;
返回结果:
(2).RANK()
作用:计算排名,排名可能不连续。对每一行进行排名,当遇到相同值时,排名会跳过一些数字。
示例:
将所有职工根据部门(deptno)分组(作为开窗列),每个组内根据薪水(sal)做降序排序,获得职工自己组内的序号。
SELECT deptno, ename, sal, rank() over ( PARTITION BY deptno ORDER BY sal DESC ) AS nums FROM emp;
返回结果:

(3).DENSE_RANK()
作用:计算排名,排名是连续的。对每一行进行排名,但不会跳过排名数字,即使遇到相同值。
示例:
将所有职工根据部门(deptno)分组(作为开窗列),每个组内根据薪水(sal)做降序排序,获得职工自己组内的序号。命令示例如下:
SELECT deptno, ename, sal, dense_rank() over ( PARTITION BY deptno ORDER BY sal DESC ) AS nums FROM emp;
返回结果:

2、聚合窗口函数(MAX、MIN、SUM、AVG、COUNT、STDDEV、STDDEV_SAMP)
(1).MAX(列名)
作用:计算窗口中的最大值。
示例:
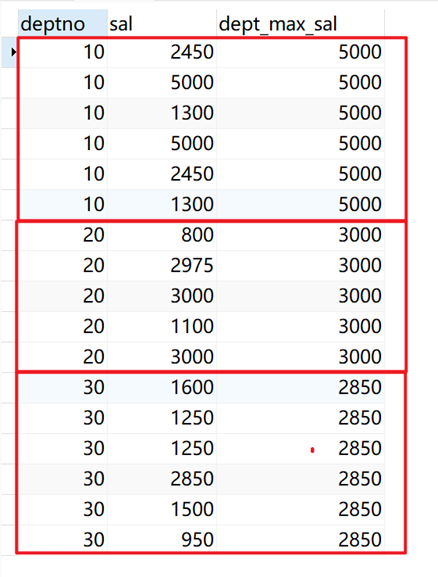
指定部门(deptno)为开窗列,计算薪水(sal)最大值,不排序,返回当前窗口(相同deptno)的最大值。
SELECT deptno, sal, max(sal) over ( PARTITION BY deptno ) dept_max_sal FROM emp;
返回结果:
(2).MIN(列名)
作用:计算窗口中的最小值。
示例:
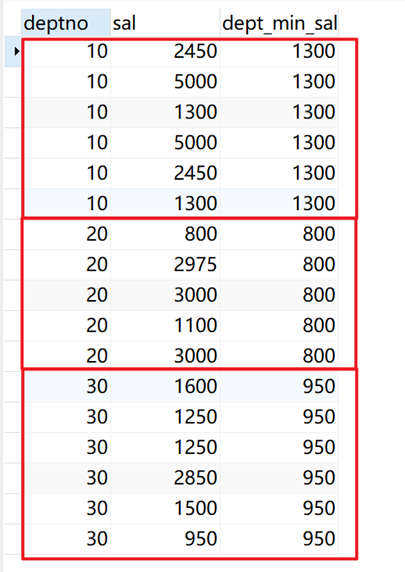
指定部门(deptno)为开窗列,计算薪水(sal)最小值,不排序,返回当前窗口(相同deptno)的最大值。
SELECT deptno, sal, min(sal) over ( PARTITION BY deptno ) dept_min_sal FROM emp;
返回结果:
(3).SUM(列名)
作用:对窗口中的数据求和。
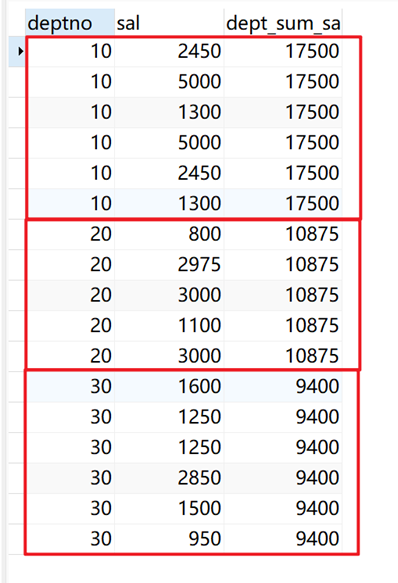
指定部门(deptno)为开窗列,计算薪水(sal)汇总值,不排序,返回当前窗口(相同deptno)的累计汇总值。
SELECT deptno, sal, sum(sal) over ( PARTITION BY deptno ) dept_sum_sal FROM emp;
返回结果:
(4).AVG(列名)
作用: 对窗口中的数据求平均值。
示例:
指定部门(deptno)为开窗列,计算薪水(sal)平均值,不排序,返回当前窗口(相同deptno)从开始行到最后一行的累计平均值。
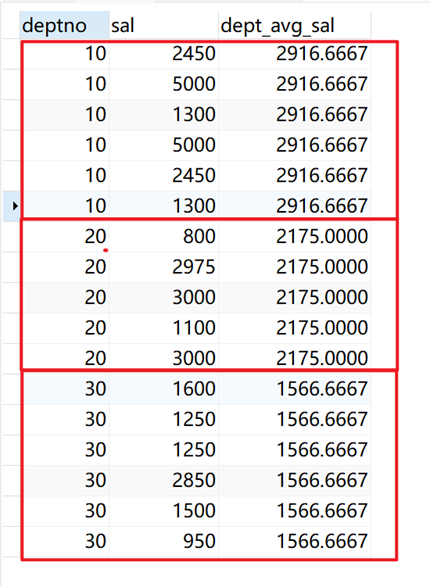
SELECT deptno, sal, avg(sal) over ( PARTITION BY deptno ) dept_avg_sal FROM emp;
返回结果:
(5).COUNT(列名)
作用:计算窗口中的记录数。
示例:
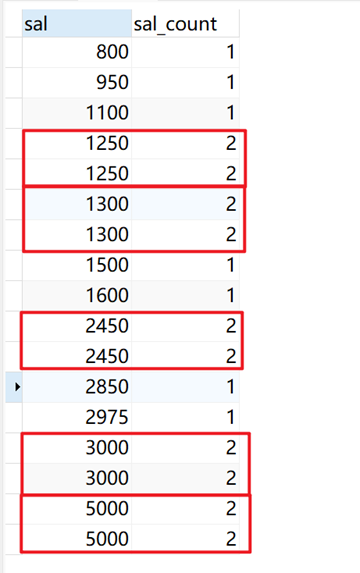
指定薪水(sal)为开窗列,不排序,返回当前窗口(相同sal)的从开始行到最后一行的累计计数值。
SELECT sal, count(sal) over ( PARTITION BY sal ) AS sal_count FROM emp;
返回结果:
(6).STDDEV(列名)
作用:计算总体标准差。使用公式 S = sqrt(sum((x_i - x_bar)^2) / N),其中 N 是样本中的数据点数量。
示例:
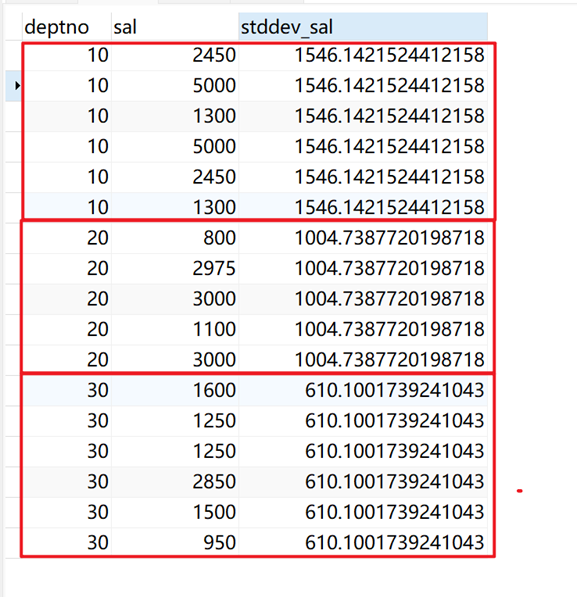
指定部门(deptno)为开窗列,计算薪水(sal)总体标准差,不排序,返回当前窗口(相同deptno)的累计总体标准差。
SELECT deptno, sal, stddev(sal) over ( PARTITION BY deptno ) stddev_sal FROM emp;
返回结果:
(7).STDDEV_SAMP(列名)
作用:计算样本标准差。使用公式 S = sqrt(sum((x_i - x_bar)^2) / (N - 1)),其中 N 是样本中的数据点数量。
示例:
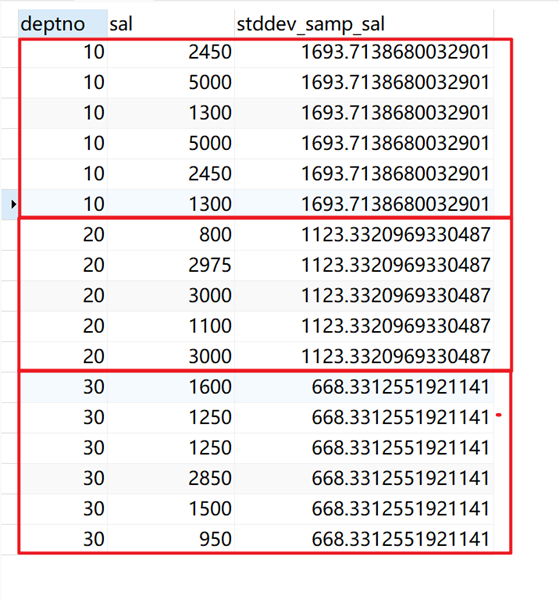
指定部门(deptno)为开窗列,计算薪水(sal)样本标准差,不排序,返回当前窗口(相同deptno)的累计样本标准差。
SELECT deptno, sal, stddev_samp(sal) over ( PARTITION BY deptno ) stddev_samp_sal FROM emp;
返回结果:
3、偏移(前后取值)窗口函数(LAG、LEAD)
(1).LAG(列名,N)
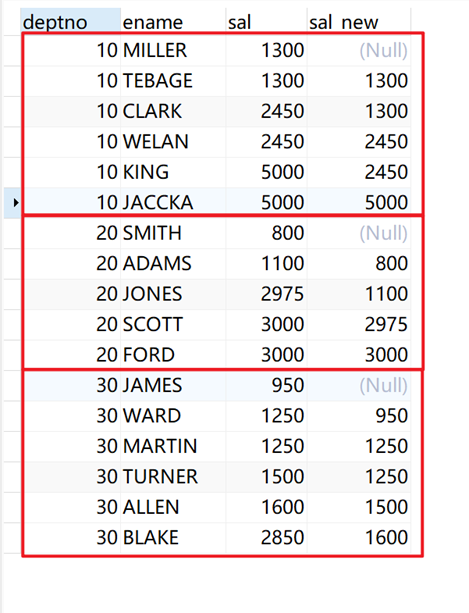
作用:取当前行往前(朝分区头部方向)第N行数据的值。
示例:
将所有职工根据部门(deptno)分组(作为开窗列),每位员工的薪水(sal)做偏移。
SELECT deptno, ename, sal, lag( sal, 1 ) over ( PARTITION BY deptno ORDER BY sal ) AS sal_new FROM emp;
返回结果:
(2).LEAD(列名,N)
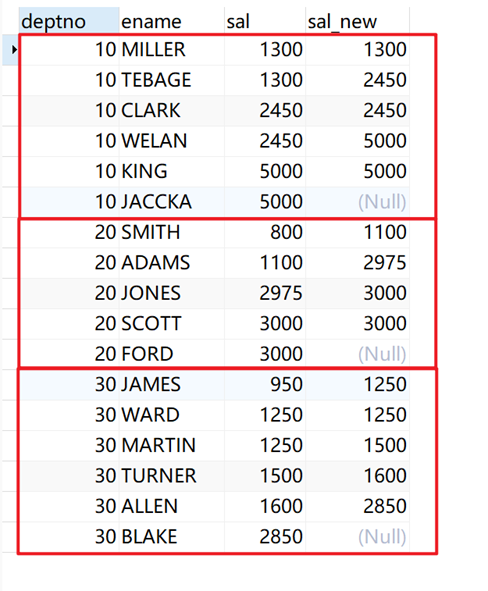
作用:取当前行往后(朝分区尾部方向)第N行数据的值。
示例:
将所有职工根据部门(deptno)分组(作为开窗列),每位员工的薪水(sal)做偏移。
SELECT deptno, ename, sal, lead( sal, 1 ) over ( PARTITION BY deptno ORDER BY sal ) AS sal_new FROM emp;
返回结果:
4、首尾取值窗口函数(FIRST_VALUE、LAST_VALUE、NTH_VALUE)
(1).FIRST_VALUE(列名)
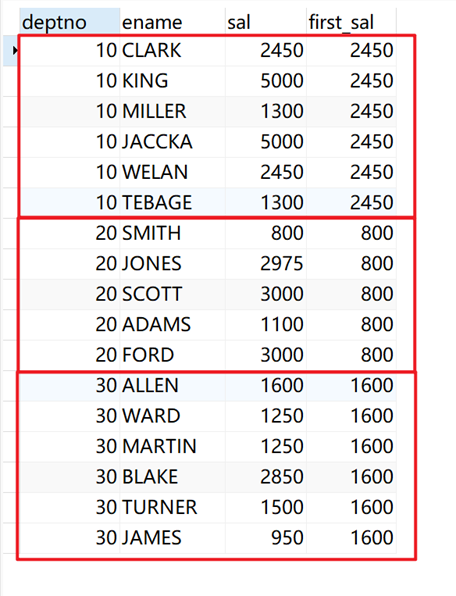
作用:取窗口内第一行的值。
示例:
将所有职工根据部门分组,返回每组中的第一行数据。
# 不指定ORDER BY
SELECT deptno, ename, sal, first_value( sal ) over ( PARTITION BY deptno ) AS first_sal FROM emp;
返回结果:
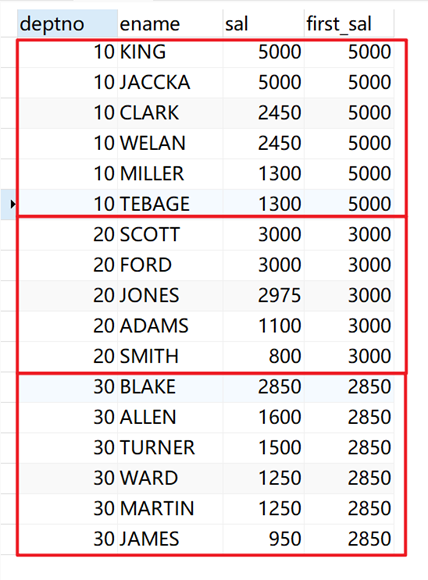
# 指定order by:
SELECT deptno, ename, sal, first_value( sal ) over ( PARTITION BY deptno ORDER BY sal DESC ) AS first_sal FROM emp;
返回结果:
(2).LAST_VALUE(列名)
作用:取窗口内最后一行的值。
示例:
将所有职工根据部门分组,返回每组中的最后一行数据。
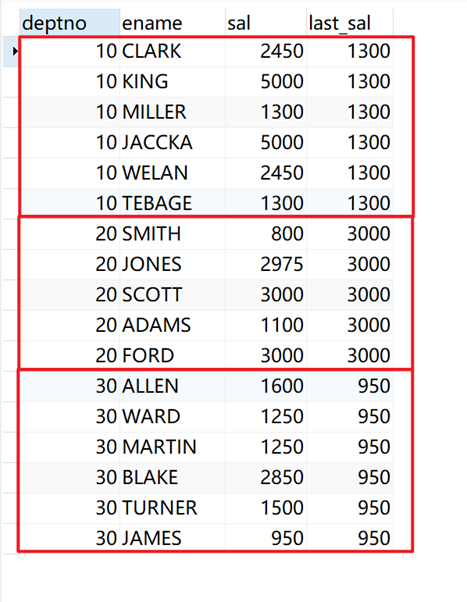
# 不指定order by,当前窗口为第一行到最后一行的范围,返回当前窗口的最后一行的值。
SELECT deptno, ename, sal, last_value( sal ) over ( PARTITION BY deptno ) AS last_sal FROM emp;
返回结果:
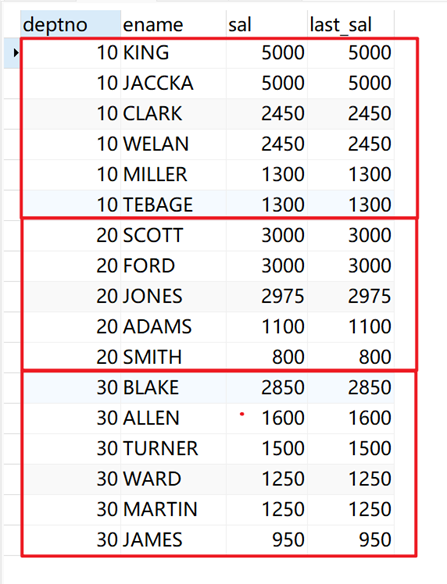
# 指定order by,当前窗口为第一行到当前行的范围。返回当前窗口的当前行的值。
SELECT deptno, ename, sal, last_value( sal ) over ( PARTITION BY deptno ORDER BY sal DESC ) AS last_sal FROM emp;
返回结果:
(3).NTH_VALUE(列名,N)
作用:取窗口内第N行的值。
示例:
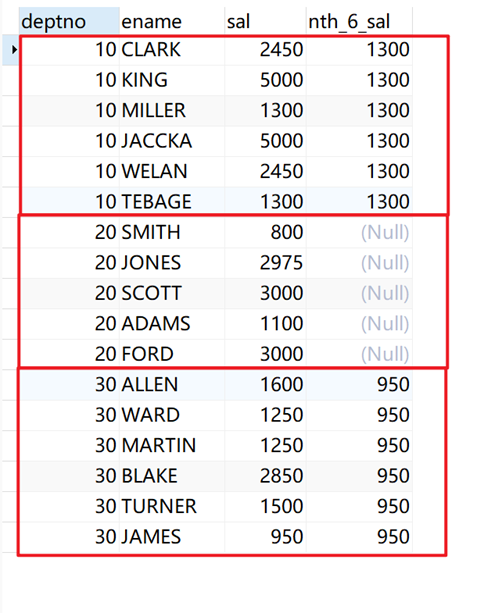
将所有职工根据部门分组,返回每组中的第6行数据。
# 不指定order by,当前窗口为第一行到最后一行的范围,返回当前窗口第6行的值。
SELECT deptno, ename, sal, nth_value( sal, 6 ) over ( PARTITION BY deptno ) AS nth_6_sal FROM emp;
返回结果:
# 指定order by,当前窗口为第一行到当前行的范围,返回当前窗口第6行的值。
SELECT deptno, ename, sal, nth_value( sal, 6 ) over ( PARTITION BY deptno ORDER BY sal ) AS nth_6_sal FROM emp;
返回结果:

5、分布窗口函数(PERCENT_RANK、CUME_DIST、NTILE)
(1).PERCENT_RANK()
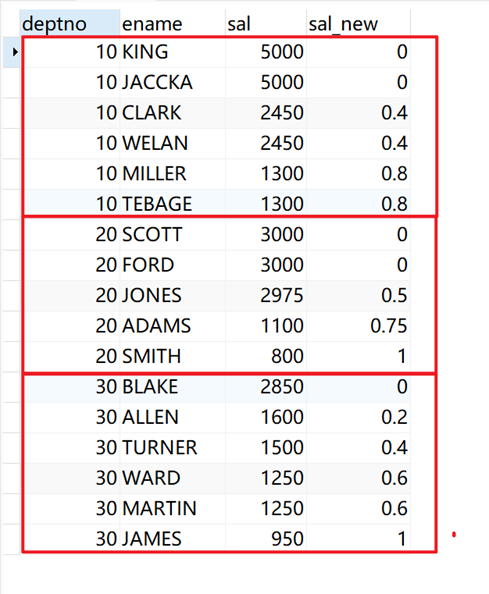
作用:计算行的百分比排名。输出百分比格式。
返回值等于“(rank - 1) / (partition_row_count - 1)”,其中:rank为该行数据的RANK窗口函数的返回结果,partition_row_count为该行数据所属分区的数据行数。
示例:
计算员工薪水在组内的百分比排名。
SELECT deptno, ename, sal, percent_rank() over ( PARTITION BY deptno ORDER BY sal DESC ) AS sal_new FROM emp;
返回结果:
(2).CUME_DIST()
作用:计算行相对于所有其他行的累积分布。
返回值等于row_number_of_last_peer / partition_row_count,其中:row_number_of_last_peer指当前行所属GROUP的最后一行数据的ROW_NUMBER窗口函数返回值,partition_row_count为该行数据所属分区的数据行数。
示例:
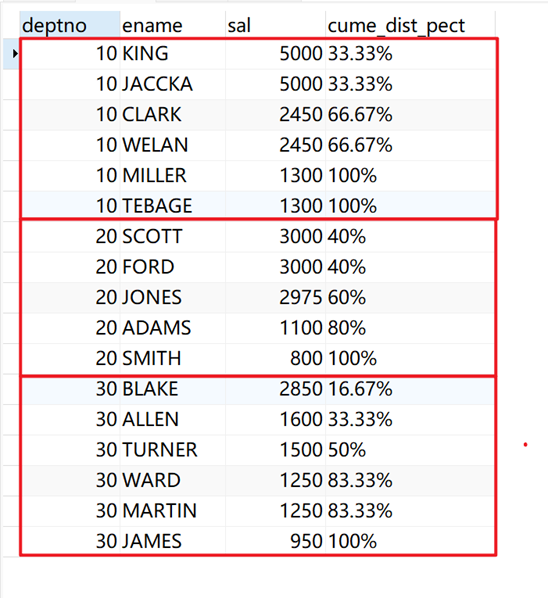
将所有职工根据部门(deptno)分组(作为开窗列),计算薪水(sal)在同一组内的前百分之几。
SELECT deptno, ename, sal, concat( round( cume_dist() over ( PARTITION BY deptno ORDER BY sal DESC )* 100, 2 ), '%' ) AS cume_dist_pect FROM emp;
返回结果:
(3).NTILE(N)
作用:将数据顺序切分成N等份,返回数据所在等份的编号(从1到N)。
用于将分区中的数据按照顺序切分成N等份,并返回数据所在等份的编号。如果分区中的数据不能被均匀地切分成N等份时,最前面的等份(编号较小的)会优先多分配1条数据。
示例:
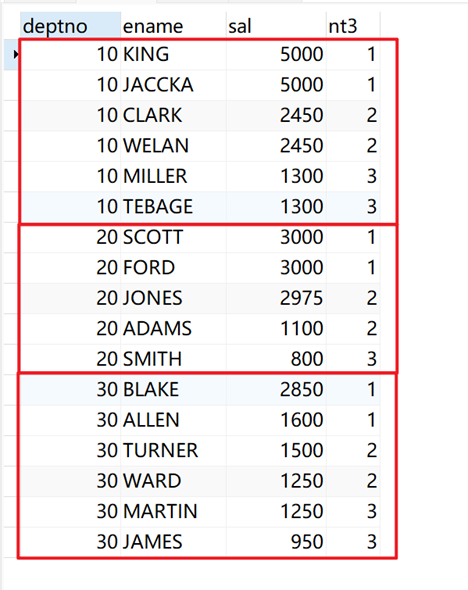
将所有职工根据部门按薪水(sal)从高到低切分为3组,并获得职工自己所在组的序号。
SELECT deptno, ename, sal, ntile( 3 ) over ( PARTITION BY deptno ORDER BY sal DESC ) AS nt3 FROM emp;
返回结果:
本文来自博客园,作者:业余砖家,转载请注明原文链接:https://www.cnblogs.com/yeyuzhuanjia/p/18839007

 浙公网安备 33010602011771号
浙公网安备 33010602011771号