
MaxCompute(ODPS)和Hive的区别
Hive概述
架构于Hadoop之上,可以将结构化的HDFS文件映射成一张表,并提供了类似于SQL语法的HQL查询功能。
核心本质:将HQL语句转换成MapReduce任务。
Hive的优缺点
优点
避免了开发人员去实现Map和Reduce的接口,大大降低了学习成本。
HQL语法类似于SQL语法,简单、容易上手。
缺点
执行效率比较低 Hive生成的MapReduce任务,不够智能化,容易造成数据倾斜。
Hive架构图
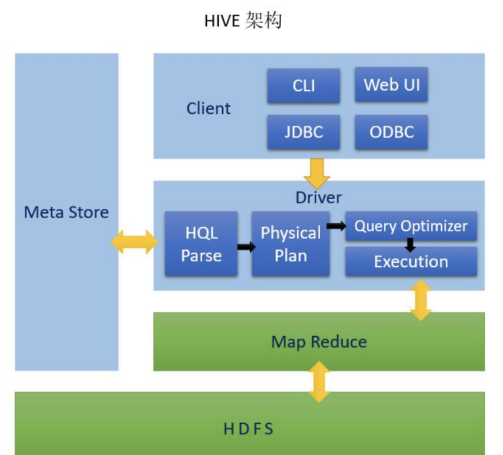
每个模块负责的内容:
Meta Store: 元数据,一般存储在mysql
Client: 客户端
Driver:驱动器
HQL Parse: 解析器,HQL解析和语法分析
Physical Plan: 编译生成逻辑执行计划
Query Optimizer: 对逻辑执行计划进行优化
Execution: 把逻辑执行计划转换成物理执行计划
Hadoop
Map Reduce: 执行计算
HDFS: 文件存储
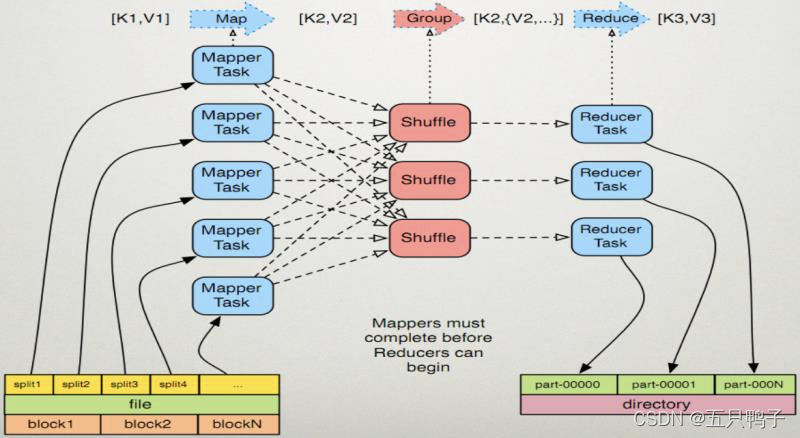
MapReduce 执行原理
MapReduce是一种分布式计算模型,由Map和Reduce组成。 Map()负责把一个大的block块进行切片并计算。 Reduce() 负责把Map()切片的数据进行汇总、计算。
执行的核心思想: 相同key的键值对为一组调用一次Reduce方法,方法内迭代这组数据进行计算。
【Map Reduce 详细步骤图】
ODPS与Hive的关系
ODPS是阿里基于Hive的核心思想构建的,不同的是Hive的文件存储在hdfs上,ODPS则存在阿里的盘古里,而且ODPS针对Hive做了一些优化。
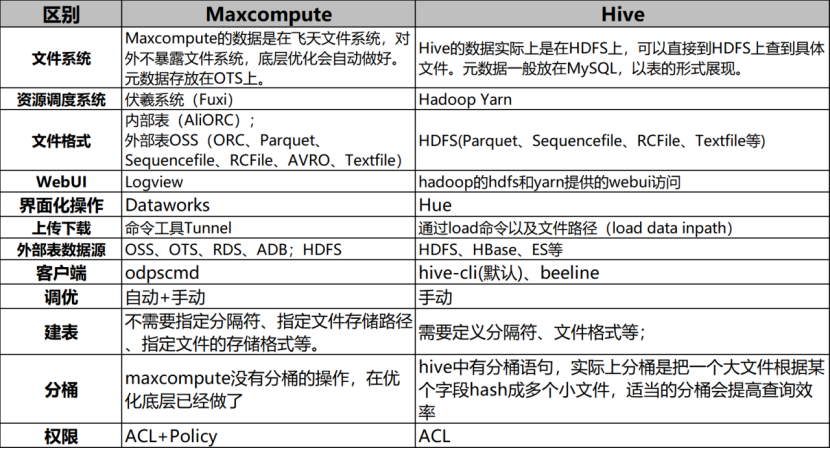
两者的区别
ODPS架构图
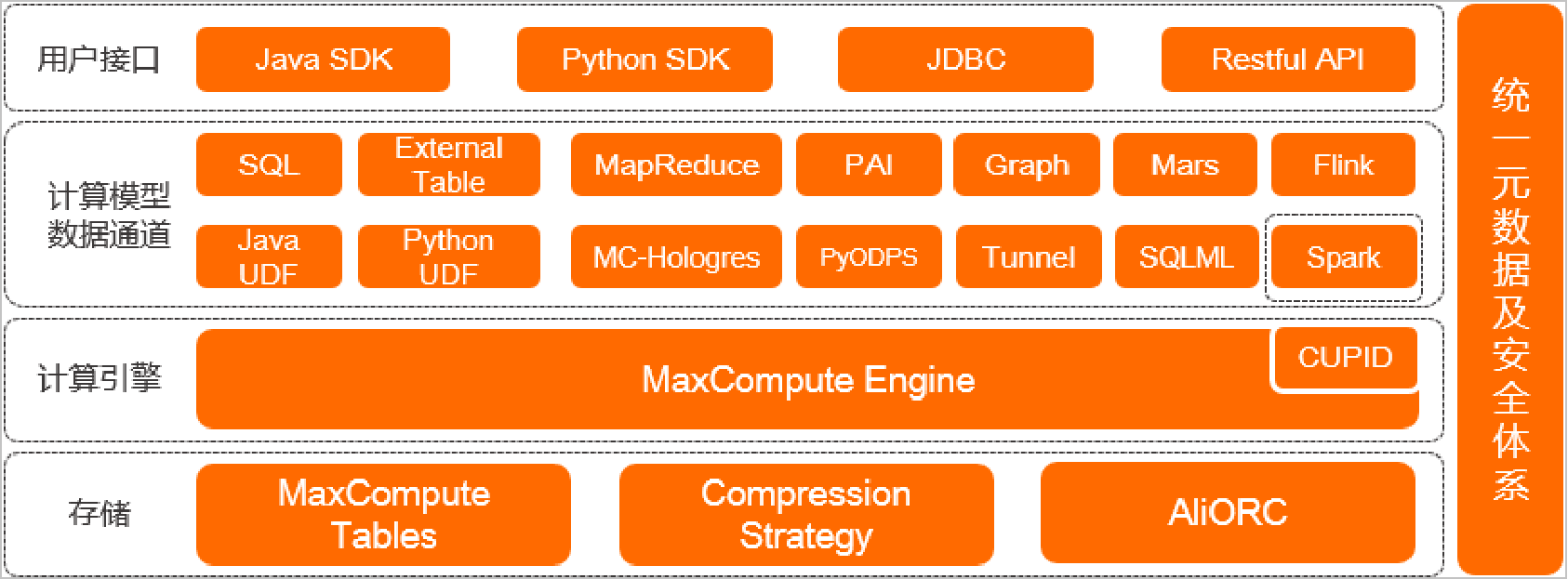
存储
MaxCompute Tables:表是MaxCompute的数据存储单元。不同类型作业的操作对象(输入、输出)都是表。
Compression Strategy:MaxCompute采用列压缩存储格式,通常情况下具备5倍压缩能力。
AliORC:MaxCompute数据存储格式全面升级为AliORC,具备更高存储性能。
计算引擎
MaxCompute本身具备计算引擎能力。在处理Spark作业时,MaxCompute运行在阿里云自研的CUPID平台之上,可以原生支持开源社区Yarn所支持的计算框架。
计算模型数据通道
MaxCompute支持多种数据通道满足多场景需求:SQL、PyODPS、MapReduce、Graph、Mars、PAI、Java/Python UDF等。
用户接口
MaxCompute提供如下用户接口:Java SDK、Python SDK、JDBC、Restful API
统一元数据及安全体系
MaxCompute提供项目元数据及使用历史数据,用户可以对作业的运行情况进行分析,用于优化作业或规划资源容量。
MaxCompute还提供了完善的安全管理体系,例如访问控制、数据加密、动态脱敏等为数据安全性提供保障。
ODPS针对Hive的优化
Query Optimizer 优化器的优化
RBO: 基于规则的优化器 (Oracle 6-9i, Hive)
• 一种过时的优化器框架,它只认规则,对数据不敏感。优化是 局部贪婪,容易陷入局部优但是全局差的场景,容易受应用规 则的顺序而生产迥异的执行计划,往往结果是不是最优的。
CBO:基于代价的优化器 (Oracle 8开始,Oracle 10g完 全取代RBO; MaxCompute)
• Volcano模型,展开各种可能等价的执行计划,然后依赖数据的统计信息,计算这些等价执行计划的“代价”,最后从中选 用cost最低的执行计划。
最典型的优化点:
distinct 的性能优化到和 group by 一致
reduce 分配更加平滑
本文来自博客园,作者:业余砖家,转载请注明原文链接:https://www.cnblogs.com/yeyuzhuanjia/p/16646151.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号