深入理解MySQL索引
1.索引的作用
索引是帮助数据库高效获取数据的数据结构。
2.InnoDB中索引的存储模型-B+树
InnoDB使用了B+树索引模型,所以数据都是存储在B+树中的。 每一个索引在InnoDB里面对应一棵B+树。
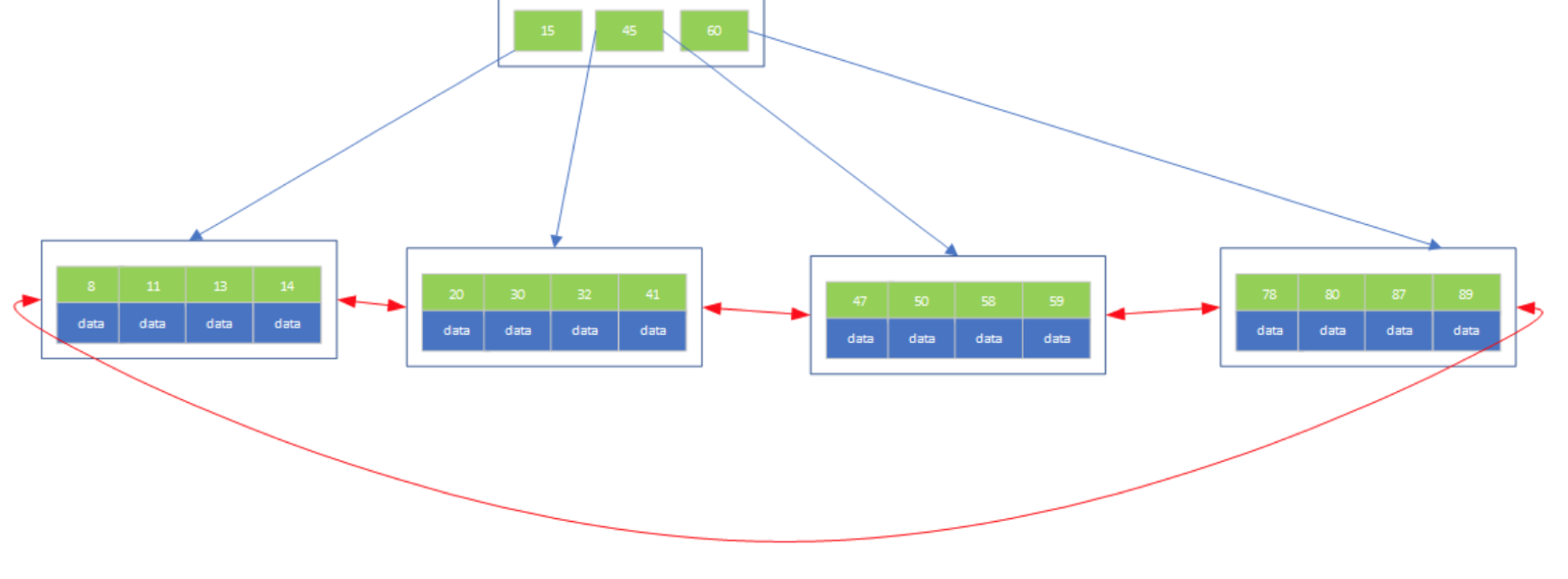
B+树的特点
1)B+树的内部结点只存放键,不存放值,因此可以在内存页中获取更多的键,这有利于更快的缩小查询范围
2)B+树的叶子结点是由一条链来连接的,因此,当需要进行一次全部数据遍历的时候,B+树只需要耗费O(logN)的时间就可以找到最小的一个结点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间
3.如何创建和删除索引
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
1)ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
2)CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引。
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。
4.索引的类型
1)按照是否为主键
主键索引(聚集索引):在叶子节点存储的是整行数据。
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,因为只要找到第一个索引值记录,其余的连续性的记录在物理表中也会连续存放,一起就可以查询到。
非主键索引(非聚集索引):在叶子节点存储的是主键的值。
索引的逻辑顺序与磁盘上行的物理存储顺序不同,非聚集索引在叶子节点存储的是主键,当我们使用非聚集索引查询数据时,需要拿到叶子上的主键再去表中查到想要查找的数据。这个过程就是我们所说的回表。
假设,我们有一个主键列为ID的表,表中有字段k,并且在k上有索引。 这个表的建表语句是:
mysql> create table T( id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6),两棵树的示例示意图如下。
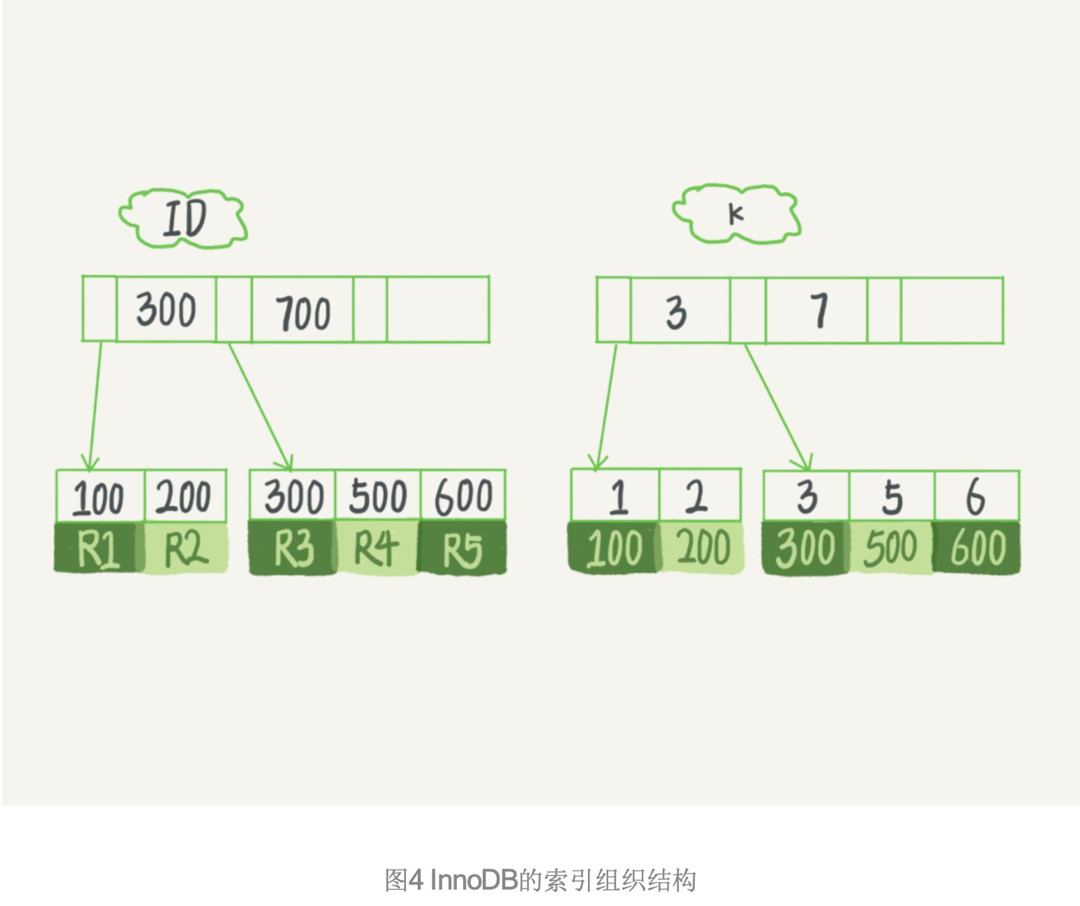
那么,基于主键索引和普通索引的查询有什么区别?
如果语句是select * from T where ID=500,即主键查询方式,则只需要搜索ID这棵B+树;
如果语句是select * from T where k=5,即普通索引查询方式,则需要先搜索k索引树,得到ID 的值为500,再到ID索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
那么有没有可能存在这样一种情况,仅仅使用普通索引而不需要回表就可以拿到所需的数据呢?答案是可以的,覆盖索引就可以满足这样的要求。
覆盖索引(其实覆盖索引不是一种索引,仅仅说是把索引列覆盖了而已)
覆盖索引就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。即普通索引中除了包含指向的ID之外,也可以存放数据。
因为覆盖索引可以减少树的搜索次数,显著提升查询性能,所有覆盖索引是一个常用的性能优化手段。
2)按照是否唯一
唯一索引:索引列中的元素是不可重复的,只能出现一次
3)按照索引包含的列的个数
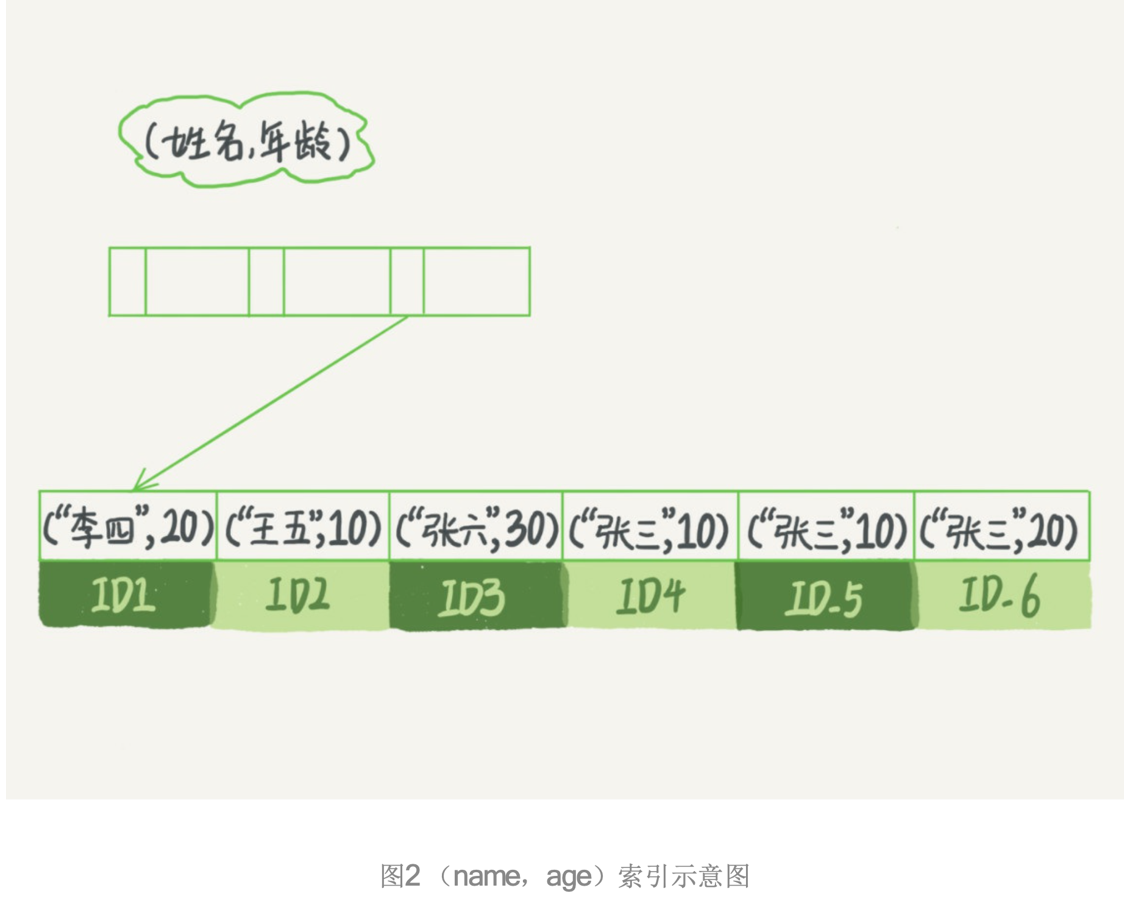
联合索引
联合索引又可称为复合索引,对于这种类型的索引,MySQL从左到右的使用索引中的字段,一次查询只能使用索引中的一部分,并且是做左侧部分,满足最左前缀原则。
最左前缀原则可以这样理解,例如索引key index(a,b,c),它就支持索引(a),(a,b),(a,b,c)3种类型的组合进行查找,不支持索引b、c查找。
利用复合索引中的附加列,可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
5.正确地使用索引
1).不要在索引列上进行运算,否则索引会失效。
例如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。应该改成create_time = unix_timestamp(’2014-05-29’);
2).索引列中不要包含NULL的值。
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
3).like语句
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
4).不使用NOT IN 、<>、!=操作(不包含在和不等于),但<,<=,=,>,>=,BETWEEN,IN是可以用到索引的
6.索引的不足之处
1)虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
2)建立索引后,索引文件会占用磁盘空间。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
参考文章
1.《MySQL实战45讲》
2.深入理解MySQL索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号