15.索引
定义解释
数据都是存在硬盘上的,那查询数据不可避免的需要进行IO操作;
索引就是一种数据结构,类似于书的目录。意味着以后再查数据应该先找目录再找数据,而不是用翻页的方式查询数据;
索引的分类与运用
索引的分类
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
分类:
1.primary key
2.unique key
3.index key
上面三种key前两种除了有加速查询的效果之外还有额外的约束条件(primary key:非空且唯一,unique key:唯一),
而index key没有任何约束功能只会帮你加速查询
索引的本质
就是通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,
也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
索引的功能
1.在表中有大量数据的前提下,创建索引速度会很慢
以后实际添加索引的时候,尽量在空表的时候添加,在创建表的时候就添加索引,此时添加索引是最快的
如果表中数据已经有了,还需要添加索引,也可以,只不过创建索引的速度会很慢,不建议这样做
2.在索引创建完毕后,对表的查询性能会大幅度提升,但是写的性能会降低
但是,写的性能影响不是很大,因为在实际中,写的频率很少,大部分操作都是查询
如何添加索引?到底给哪些字段加索引呢?
'''没有固定答案,具体给哪个字段加索引,要看你实际的查询条件'''
select * from user where name='' and password='';
# 索引的使用其实是需要大量的工作经验,才能正确的判断出
'''不要一创建表就加索引,在一张表中,最多最多不要超过15个索引,索引越多,性能就会下降'''
# 如何数据量比较小,不需要加索引,100w一下一般不用加,mysql针对于1000w一下的数据,性能不会下降太多.
b+树
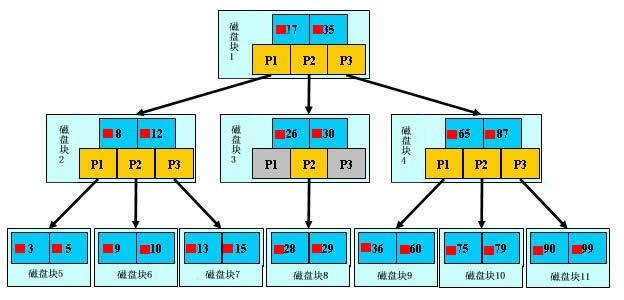
只有叶子结点存放真实数据,根和树枝节点存的仅仅是虚拟数据
查询次数由树的层级决定,层级越低次数越少
一个磁盘块儿的大小是一定的,那也就意味着能存的数据量是一定的。如何保证树的层级最低呢?一个磁盘块儿存放占用空间比较小的数据项
以后加索引的时候,尽量给字段中存的是数字的列加,我们使用主键查询速度很快
select * from user where name = ''
select * from user where id = '' # 主键查询的更快一些
聚集索引(primary key)
聚集索引其实指的就是表的主键,innodb引擎规定一张表中必须要有主键。先来回顾一下存储引擎。
myisam在建表的时候对应到硬盘有几个文件(三个)?
innodb在建表的时候对应到硬盘有几个文件(两个)?frm文件只存放表结构,不可能放索引,也就意味着innodb的索引跟数据都放在ibd表数据文件中。
特点:叶子结点放的一条条完整的记录
辅助索引(unique,index)
辅助索引:查询数据的时候不可能都是用id作为筛选条件,也可能会用name,password等字段信息,那么这个时候就无法利用到聚集索引的加速查询效果。就需要给其他字段建立索引,这些索引就叫辅助索引
特点:叶子结点存放的是辅助索引字段对应的那条记录的主键的值(比如:按照name字段创建索引,那么叶子节点存放的是:{name对应的值:name所在的那条记录的主键值})
select name from user where name='jack';
上述语句叫覆盖索引:只在辅助索引的叶子节点中就已经找到了所有我们想要的数据
select age from user where name='jack';
上述语句叫非覆盖索引,虽然查询的时候命中了索引字段name,但是要查的是age字段,所以还需要利用主键才去查找

 浙公网安备 33010602011771号
浙公网安备 33010602011771号