
窗口函数与普通聚合函数的区别:
窗口函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
一、基本语句形式:
Function(arg1,...) over(partition by ... order by ... Window_clause)
Window_clause: rows(物理窗口)/range(逻辑窗口) between start_expr and end_expr
start_expr: unbounded preceding(第一个) / current row(现在所在行) / n preceding(往前第n行) / n following(往后第n行)
end_expr: unbounded following(最后一个) / current row(现在所在行) / n preceding(往前第n行) / n following(往后第n行)
窗口函数带有一个开窗函数over(),包含三个分析子句:分组(partition by)、排序(order by)、窗口定位(rows,即Window_clause)。
二、函数形式
按照功能划分,可以把MySQL支持的窗口函数分为如下几类:
排序函数:row_number() / rank() / dense_rank()
分布函数:percent_rank() / cume_dist()
前后函数:lag() / lead()
头尾函数:first_val() / last_val()
其他函数:nth_value() / nfile()
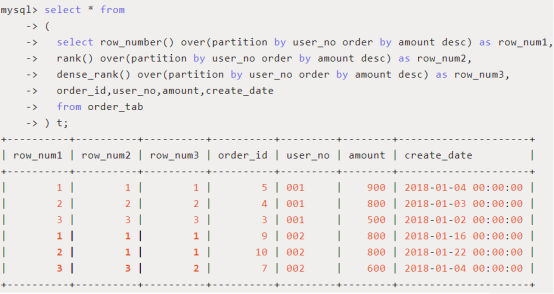
1、排序函数:row_number() / rank() / dense_rank()
用途:显示分区中的当前行号
使用场景:希望查询每个用户订单金额最高的前三个订单
PS:rank和dense_rank这两个函数和row_number()非常类似,只是在出现重复值时处理逻辑有所不同。rank()是跳跃排序,有两个第二名时接下来就是第四名,不会出现第三名;dense_rank()是连续排序,有两个第二名时仍然跟着第三名。
当有空值时,可设置空值优先排序或者最后排序,order by amount NULLS LAST(空值最后排序)
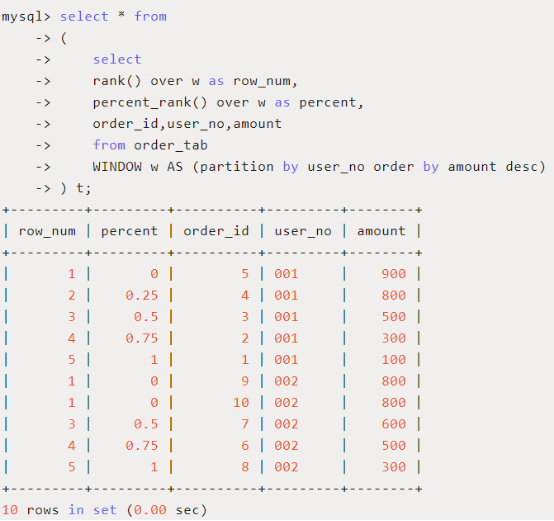
2、分布函数:percent_rank() / cume_dist()
Percent_rank()
用途:和之前的RANK()函数相关,(rank – 1) / (rows – 1)
其中,rank为rank()函数产生的序号,rows为当前窗口的记录总行数
Cume_dist()
用途:分组内小于等于当前rank值的行数/分组内总行数
应用场景:大于等于当前订单金额的订单比例有多少
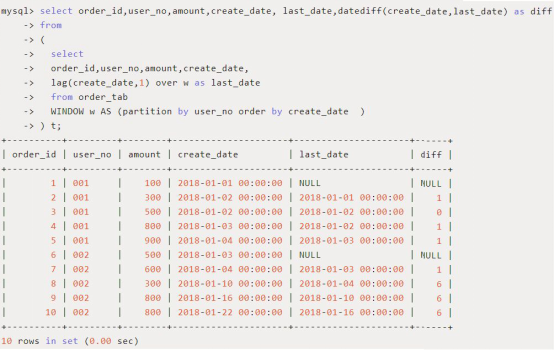
3、前后函数:lead(n) / lag(n)
用途:分区中位于当前行前n行(lead) / 后n行(lag)的记录值
使用场景:查询上一个订单距离当前订单的时间间隔
PS:可以把上下几行放在同一行中,进而可以进行计算。
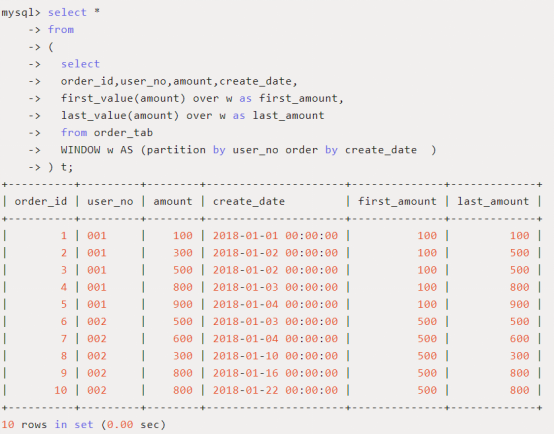
4、头尾函数:first_val(expr) / last_val(expr)
用途:得到分区中的第一个/最后一个指定参数的值
使用场景:查询截止到当前订单,按照日期排序第一个订单和最后一个订单的订单金额
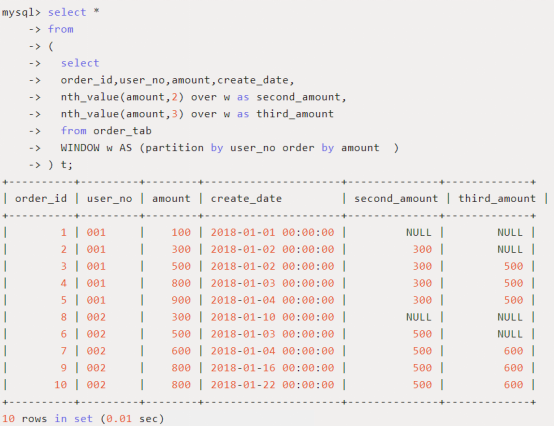
5、其他函数:nth_value(expr,n) / nfile(n)
nth_value(expr,n)
用途:返回窗口中第n个expr的值,expr可以是表达式,也可以是列名。
使用场景:每个用户订单中显示本用户金额排名第二和第三的订单金额
Nfile(n)
用途:将分区中的有序数据分为n个桶,记录桶号。
应用场景:将每个用户的订单按照订单金额分成3组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号