Pipelines
System.IO.Pipelines 是一个新库,旨在使在 .NET 中执行高性能 I/O 更加容易。
var pipe = new Pipe(); PipeReader reader = pipe.Reader; PipeWriter writer = pipe.Writer; async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); await Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) { // Allocate at least 512 bytes from the PipeWriter. Memory<byte> memory = writer.GetMemory(minimumBufferSize); try { int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None); if (bytesRead == 0) { break; } // Tell the PipeWriter how much was read from the Socket. writer.Advance(bytesRead); } catch (Exception ex) { LogError(ex); break; } // Make the data available to the PipeReader. FlushResult result = await writer.FlushAsync(); if (result.IsCompleted) { break; } } // By completing PipeWriter, tell the PipeReader that there's no more data coming. await writer.CompleteAsync(); } async Task ReadPipeAsync(PipeReader reader) { while (true) { ReadResult result = await reader.ReadAsync(); ReadOnlySequence<byte> buffer = result.Buffer; while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line)) { // Process the line. ProcessLine(line); } // Tell the PipeReader how much of the buffer has been consumed. reader.AdvanceTo(buffer.Start, buffer.End); // Stop reading if there's no more data coming. if (result.IsCompleted) { break; } } // Mark the PipeReader as complete. await reader.CompleteAsync(); } bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line) { // Look for a EOL in the buffer. SequencePosition? position = buffer.PositionOf((byte)'\n'); if (position == null) { line = default; return false; } // Skip the line + the \n. line = buffer.Slice(0, position.Value); buffer = buffer.Slice(buffer.GetPosition(1, position.Value)); return true; }
有两个循环:
FillPipeAsync从Socket读取并写入PipeWriter。ReadPipeAsync从PipeReader读取并分析传入的行。
没有分配显式缓冲区。 所有缓冲区管理都委托给 PipeReader 和 PipeWriter 实现。 委派缓冲区管理使使用代码更容易集中关注业务逻辑。
在第一个循环中:
- 调用 PipeWriter.GetMemory(Int32) 从基础编写器获取内存。
- 调用 PipeWriter.Advance(Int32) 以告知
PipeWriter有多少数据已写入缓冲区。 - 调用 PipeWriter.FlushAsync 以使数据可用于
PipeReader。
在第二个循环中,PipeReader 使用由 PipeWriter 写入的缓冲区。 缓冲区来自套接字。 对 PipeReader.ReadAsync 的调用:
-
返回包含两条重要信息的 ReadResult:
- 以
ReadOnlySequence<byte>形式读取的数据。 - 布尔值
IsCompleted,指示是否已到达数据结尾 (EOF)。
- 以
找到行尾 (EOL) 分隔符并分析该行后:
- 该逻辑处理缓冲区以跳过已处理的内容。
- 调用
PipeReader.AdvanceTo以告知PipeReader已消耗和检查了多少数据。
读取器和编写器循环通过调用 Complete 结束。 Complete 使基础管道释放其分配的内存。
反压和流量控制
理想情况下,读取和分析可协同工作:
- 写入线程使用来自网络的数据并将其放入缓冲区。
- 分析线程负责构造适当的数据结构。
通常,分析所花费的时间比仅从网络复制数据块所用时间更长:
- 读取线程领先于分析线程。
- 读取线程必须减缓或分配更多内存来存储用于分析线程的数据。
为了获得最佳性能,需要在频繁暂停和分配更多内存之间取得平衡。
为解决上述问题,Pipe 提供了两个设置来控制数据流:
- PauseWriterThreshold:确定在调用 FlushAsync 暂停之前应缓冲多少数据。
- ResumeWriterThreshold:确定在恢复对
PipeWriter.FlushAsync的调用之前,读取器必须观察多少数据。
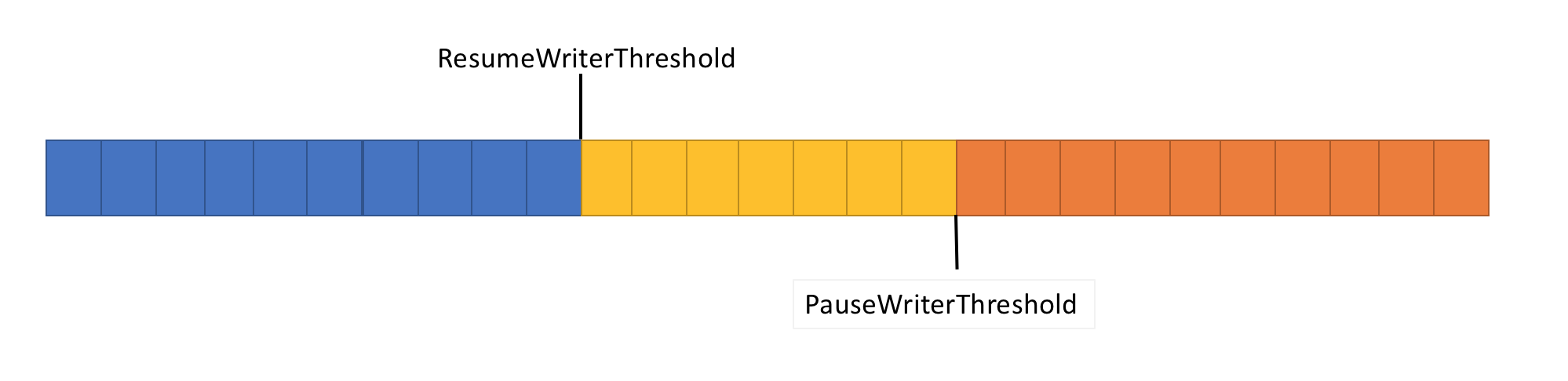
- 当
Pipe中的数据量超过PauseWriterThreshold时,返回不完整的ValueTask<FlushResult>。 - 低于
ResumeWriterThreshold时,返回完整的ValueTask<FlushResult>。
使用两个值可防止快速循环,如果只使用一个值,则可能发生这种循环。
// The Pipe will start returning incomplete tasks from FlushAsync until // the reader examines at least 5 bytes. var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5); var pipe = new Pipe(options);
PipeScheduler
通常在使用 async 和 await 时,异步代码会在 TaskScheduler 或当前 SynchronizationContext 上恢复。
在执行 I/O 时,对执行 I/O 的位置进行细粒度控制非常重要。 此控件允许高效利用 CPU 缓存。 高效的缓存对于 Web 服务器等高性能应用至关重要。 PipeScheduler 提供对异步回调运行位置的控制。 默认情况下:
- 使用当前的 SynchronizationContext。
- 如果没有
SynchronizationContext,它将使用线程池运行回调。
PipeScheduler.ThreadPool 是 PipeScheduler 实现,用于对线程池的回调进行排队。 PipeScheduler.ThreadPool 是默认选项,通常也是最佳选项。 PipeScheduler.Inline 可能会导致意外后果,如死锁。
管道重置
通常重用 Pipe 对象即可重置。 若要重置管道,请在 PipeReader 和 PipeWriter 完成时调用 PipeReader Reset。
取消
FlushAsync 支持传递 CancellationToken。 如果令牌在刷新挂起时被取消,则传递 CancellationToken 将导致 OperationCanceledException。 PipeWriter.FlushAsync 支持通过 PipeReader.CancelPendingRead或 PipeWriter.CancelPendingFlush 取消当前刷新操作而不引发异常的方法。 调用 PipeWriter.CancelPendingFlush 将导致对 PipeWriter.FlushAsync 或 PipeWriter.WriteAsync 的当前或下次调用返回 FlushResult,并将 IsCanceled 设置为 true。 这对于以非破坏性和非异常的方式停止暂停刷新非常有用。
PipeWriter
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default) { byte[] helloBytes = Encoding.ASCII.GetBytes("Hello"); // Write helloBytes to the writer, there's no need to call Advance here // (Write does that). await writer.WriteAsync(helloBytes, cancellationToken); }
PipeReader
两个核心API ReadAsync和AdvanceTo。ReadAsync获取Pipe数据,AdvanceTo告诉PipeReader不再需要这些缓冲区,以便可以丢弃它们
PipeReader 代表调用方管理内存。 在调用 PipeReader.ReadAsync 之后始终调用 PipeReader.AdvanceTo。 这使 PipeReader 知道调用方何时用完内存,以便可以对其进行跟踪。 从 PipeReader.ReadAsync 返回的 ReadOnlySequence<byte> 仅在调用 PipeReader.AdvanceTo 之前有效。 调用 PipeReader.AdvanceTo 后,不能使用 ReadOnlySequence<byte>。
PipeReader.AdvanceTo 采用两个 SequencePosition 参数:
- 第一个参数确定消耗的内存量。
- 第二个参数确定观察到的缓冲区数。
将数据标记为“已使用”意味着管道可以将内存返回到底层缓冲池。 将数据标记为“已观察”可控制对 PipeReader.ReadAsync 的下一个调用的操作。 将所有内容都标记为“已观察”意味着下次对 PipeReader.ReadAsync 的调用将不会返回,直到有更多数据写入管道。 任何其他值都将使对 PipeReader.ReadAsync 的下一次调用立即返回并包含已观察到的和未观察到的数据,但不是已被使用的数据。
ReadOnlySequence<T>
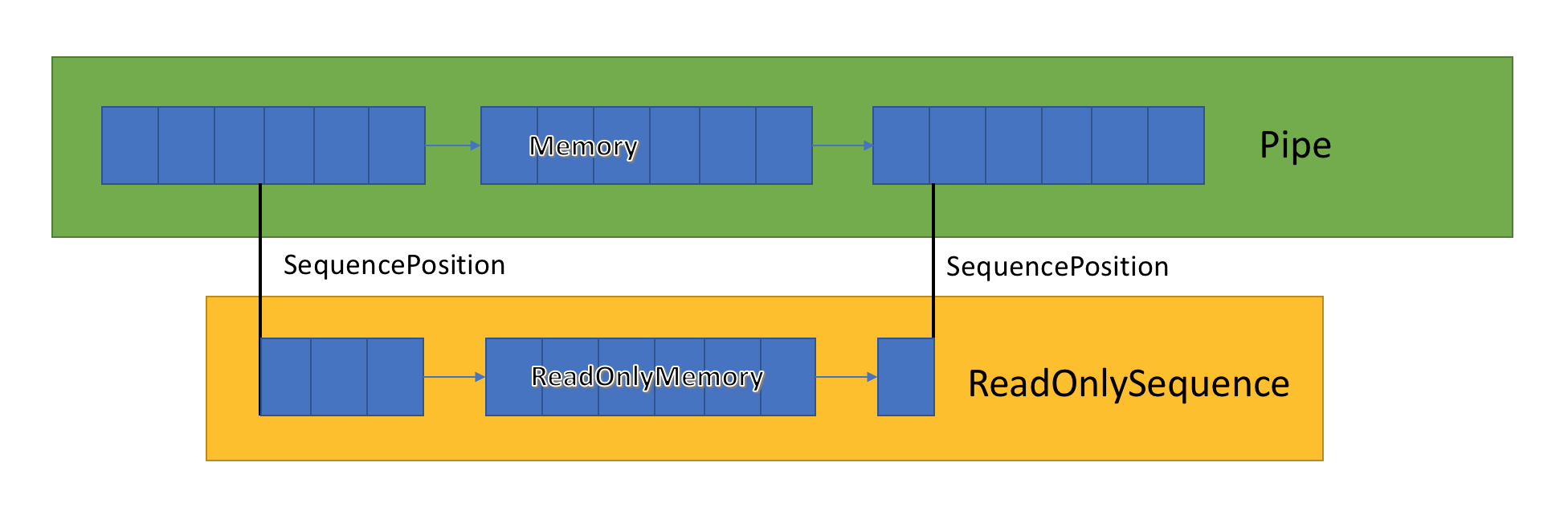
ReadOnlySequence<T> 是一个可以表示 T 的连续或非连续序列的结构。
处理 ReadOnlySequence<T> 可能比较困难,因为数据可能会拆分到序列中的多个段。 为了获得最佳性能,请将代码拆分为两个路径:
- 处理单段情况的快速路径。
- 处理拆分到各个段中的数据的慢速路径。
可以使用多种方法来处理多段序列中的数据:
- 使用
SequenceReader<T>。 - 逐段分析数据,同时跟踪已分析的段内的
SequencePosition和索引。 这样可以避免不必要的分配,但可能效率会很低,尤其是对于小型缓冲区。 - 将
ReadOnlySequence<T>复制到连续数组,并将其视为单个缓冲区:- 如果
ReadOnlySequence<T>的大小较小,则可以使用 stackalloc 运算符将数据复制到堆栈分配的缓冲区。 - 使用 ArrayPool<T>.Shared 将
ReadOnlySequence<T>复制到共用的数组。 - 使用
ReadOnlySequence<T>.ToArray()。 不建议在热路径中使用这种方法,因为它会在堆上分配新的T[]。
- 如果
以下示例演示了处理 ReadOnlySequence<byte> 的一些常见情况:
处理二进制数据
以下示例从 ReadOnlySequence<byte> 的开头分析 4 字节的大端整数长度。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length) { // If there's not enough space, the length can't be obtained. if (buffer.Length < 4) { length = 0; return false; } // Grab the first 4 bytes of the buffer. var lengthSlice = buffer.Slice(buffer.Start, 4); if (lengthSlice.IsSingleSegment) { // Fast path since it's a single segment. length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span); } else { // There are 4 bytes split across multiple segments. Since it's so small, it // can be copied to a stack allocated buffer. This avoids a heap allocation. Span<byte> stackBuffer = stackalloc byte[4]; lengthSlice.CopyTo(stackBuffer); length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer); } // Move the buffer 4 bytes ahead. buffer = buffer.Slice(lengthSlice.End); return true; }
空段
将空段存储在 ReadOnlySequence<T> 中是有效的。 显式枚举段时,可能会出现空段:
static void EmptySegments() { // This logic creates a ReadOnlySequence<byte> with 4 segments, // two of which are empty. var first = new BufferSegment(new byte[0]); var last = first.Append(new byte[] { 97 }) .Append(new byte[0]).Append(new byte[] { 98 }); // Construct the ReadOnlySequence<byte> from the linked list segments. var data = new ReadOnlySequence<byte>(first, 0, last, 1); // Slice using numbers. var sequence1 = data.Slice(0, 2); // Slice using SequencePosition pointing at the empty segment. var sequence2 = data.Slice(data.Start, 2); Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2 Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2 // sequence1.FirstSpan.Length=1 Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}"); // Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly // on the empty segment! // sequence2.FirstSpan.Length=0 Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}"); // The following code prints 0, 1, 0, 1. SequencePosition position = data.Start; while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory)) { Console.WriteLine(memory.Length); } } class BufferSegment : ReadOnlySequenceSegment<byte> { public BufferSegment(Memory<byte> memory) { Memory = memory; } public BufferSegment Append(Memory<byte> memory) { var segment = new BufferSegment(memory) { RunningIndex = RunningIndex + Memory.Length }; Next = segment; return segment; } }
前面的代码将创建一个包含空段的 ReadOnlySequence<byte>,并显示这些空段对各种 API 的影响:
- 包含指向空段的
SequencePosition的ReadOnlySequence<T>.Slice会保留该段。 - 包含 int 的
ReadOnlySequence<T>.Slice会跳过空段。 - 枚举
ReadOnlySequence<T>会枚举空段。
sequence1.FirstSpan是new byte[] { 97 },sequence2.FirstSpan是new byte[0]
ReadOnlySequence<T> 和 SequencePosition 的潜在问题
处理 ReadOnlySequence<T>/SequencePosition 与常规 ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int 时,有几个异常的结果
SequencePosition是特定ReadOnlySequence<T>的位置标记,而不是绝对位置。 由于它是相对于特定ReadOnlySequence<T>的,因此如果在其起源的ReadOnlySequence<T>之外使用,则没有意义。- 不能对没有
ReadOnlySequence<T>的SequencePosition执行算术运算。 这意味着,执行position++等基本操作将以ReadOnlySequence<T>.GetPosition(position, 1)的形式写入。 GetPosition(long)不支持负索引。 这意味着,如果没有遍历所有段,就无法获取倒数第二个字符。- 无法比较两个
SequencePosition,这使得难以:- 了解一个位置是否大于或小于另一个位置。
- 编写一些分析算法。
ReadOnlySequence<T>大于对象引用,并且应尽可能通过 in 或 ref 进行传递。 通过in或ref传递ReadOnlySequence<T>可减少结构的复制。- 空段:
- 在
ReadOnlySequence<T>中有效。 - 可能会在使用
ReadOnlySequence<T>.TryGet方法进行循环访问时出现。 - 可能会在结合使用
ReadOnlySequence<T>.Slice()方法与SequencePosition对象来对序列进行切片时出现。
- 在
SequenceReader<T>
- 是 .NET Core 3.0 中引入的一种新类型,用于简化
ReadOnlySequence<T>的处理。 - 统一了单段
ReadOnlySequence<T>和多段ReadOnlySequence<T>之间的差异。 - 提供用于读取二进制数据和文本数据(
byte和char,不一定拆分到各个段)的帮助程序。
提供用于处理二进制数据和带分隔符的数据的内置方法。
SequenceReader<T> 具有用于直接枚举 ReadOnlySequence<T> 内的数据的方法。
while (reader.TryRead(out byte b)) { Process(b); }
SequenceReader<T> 实现 FindIndexOf 的示例:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) { var reader = new SequenceReader<byte>(buffer); while (!reader.End) { // Search for the byte in the current span. var index = reader.CurrentSpan.IndexOf(data); if (index != -1) { // It was found, so advance to the position. reader.Advance(index); return reader.Position; } // Skip the current segment since there's nothing in it. reader.Advance(reader.CurrentSpan.Length); } return null; }
CurrentSpan 公开了当前段的 Span
处理二进制数据
以下示例从 ReadOnlySequence<byte> 的开头分析 4 字节的大端整数长度。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length) { var reader = new SequenceReader<byte>(buffer); return reader.TryReadBigEndian(out length); }
处理文本数据
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' }; static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line) { var reader = new SequenceReader<byte>(buffer); if (reader.TryReadTo(out line, NewLine)) { buffer = buffer.Slice(reader.Position); return true; } line = default; return false; }
SequenceReader<T> 常见问题
- 由于
SequenceReader<T>是可变结构,因此应始终通过引用进行传递。 SequenceReader<T>是引用结构,因此只能在同步方法中使用,不能存储在字段中。SequenceReader<T>已进行了优化,可用作只进读取器。Rewind适用于无法利用其他Read、Peek和IsNextAPI 来解决的小型备份。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号