数据库复制技术中关于复制滞后的一些思考
使用复制技术除了可以容忍节点故障提高可用性外,还包含可扩展性(采用多节点来处理更多请求)和低延迟(将副本部署在地理上距离用户更近的地方)等优点。
在使用主从复制下,如果试图同步复制所有的从副本,则单个节点故障或网络中断将使整个系统无法写入。而且节点越多,发生故障的机率也更高,所以多从副本一般都是通过异步复制的方式。
使用异步复制将会导致主、从节点的数据产生不一致,这种不一致理论是只是暂时的,如果停止写数据库,经过一段时间之后,从节点最终会赶上主节点,这种效应也称为最终一致性
实际情况下,当系统已接近设计上限,或者网络存在问题(不可避免),则滞后可能就不是理论存在的问题,而是个实实在在的现实问题。下面介绍三个复制滞后可能出现的问题,及相应的解决思路机制
-
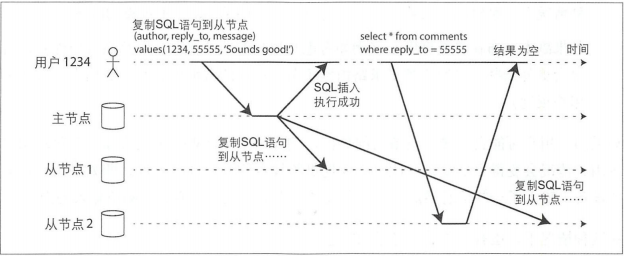
读自己的写
提交新数据须发送到主节目,但是用户读自己的数据时,数据可能来自从节点,导致不一致。
![]()
对于上图的情况,需要“写后读一致性”,也称为读写一致性,该机制保证用户总能看到自己最新提交的更新。 -
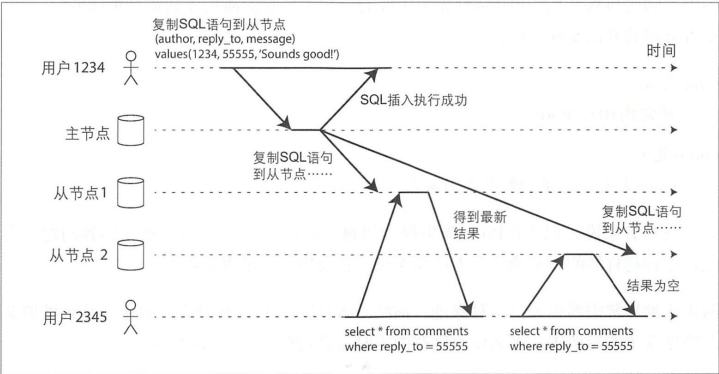
单调读
如下图所示,用户看到最新内容之后又读到了过期的内容,如像时间被回拨,此时需要单调写一致性。
确定某个用户依次进行多次读取,则绝不会看到回滚现象
![]()
-
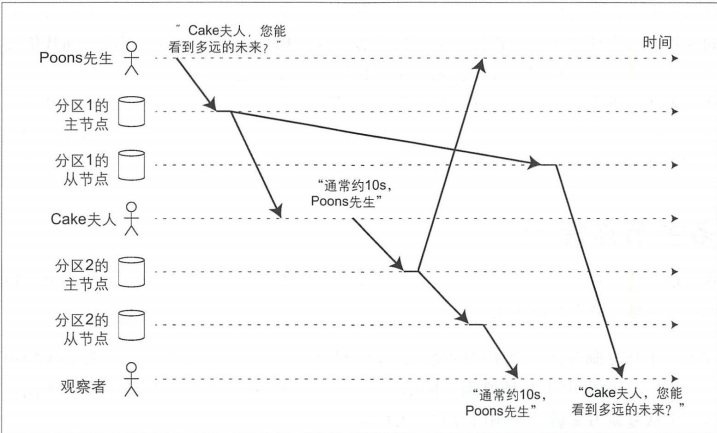
前缀一致读
因果出现了反常,这是分区(分片)数据库中出现的一个特殊问题。需要的机制是对于一系列按照某个顺序发生的写请求,那么读取这些内容时也会按照当时写入的顺序。
![]()
解决方案思考
在应用层层面可以提供比底层数据库更强有力的保证,如保证在主节点上进行特定类型的读取,而代价是,应用层代码会非常复杂且容易出错。所以应该假定数据库能“做正确的事情”,情况就简单的,最好的办法是抽象出一层,提供事务这种更强力的保证

 浙公网安备 33010602011771号
浙公网安备 33010602011771号