
第二次结对编程作业
第二次结对作业:班级成绩表
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
|---|---|
| 作业目标 | 学会利用java爬虫网页数据 |
| 作业源代码 | https://gitee.com/yemingpu/pair |
| 队员1 | 211806358 |
| 队员2 | 211806317 |
| 代码行数 | 124行 |
|---|---|
| 需求分析时间 | 1h |
| 编码时间 | 8h |
各自的感受:
-
叶明浦:书到用时方恨少,到了现在需要编程代码的时候才发现自己不会的还有很多,在实现编程代码的时候
有许多的问题需要解决。自己还需要学习更多的知识才可以。 -
郭炜:自己对java代码的编写本来就不怎么熟悉,现在又要开始自己学习新的代码知识,感觉真的头疼呀。
加上自己有一些拖延症,到后面才发现时间不够了,害!
对对方的评价:
-
叶明浦:已经是第二次组队了,现在也熟悉了,虽然在这个代码这块都不怎么好,但一起加油吧。多找一些
时间学习一下这次不会的爬虫知识。 -
郭炜:叶明浦对代码这块还是蛮厉害的,不够没有学习过爬虫,这次并不理想,不过没关系,我们一起加油
学习这个新的知识吧。
结对的照片:


代码思路分析:
1.进入主网页:
-
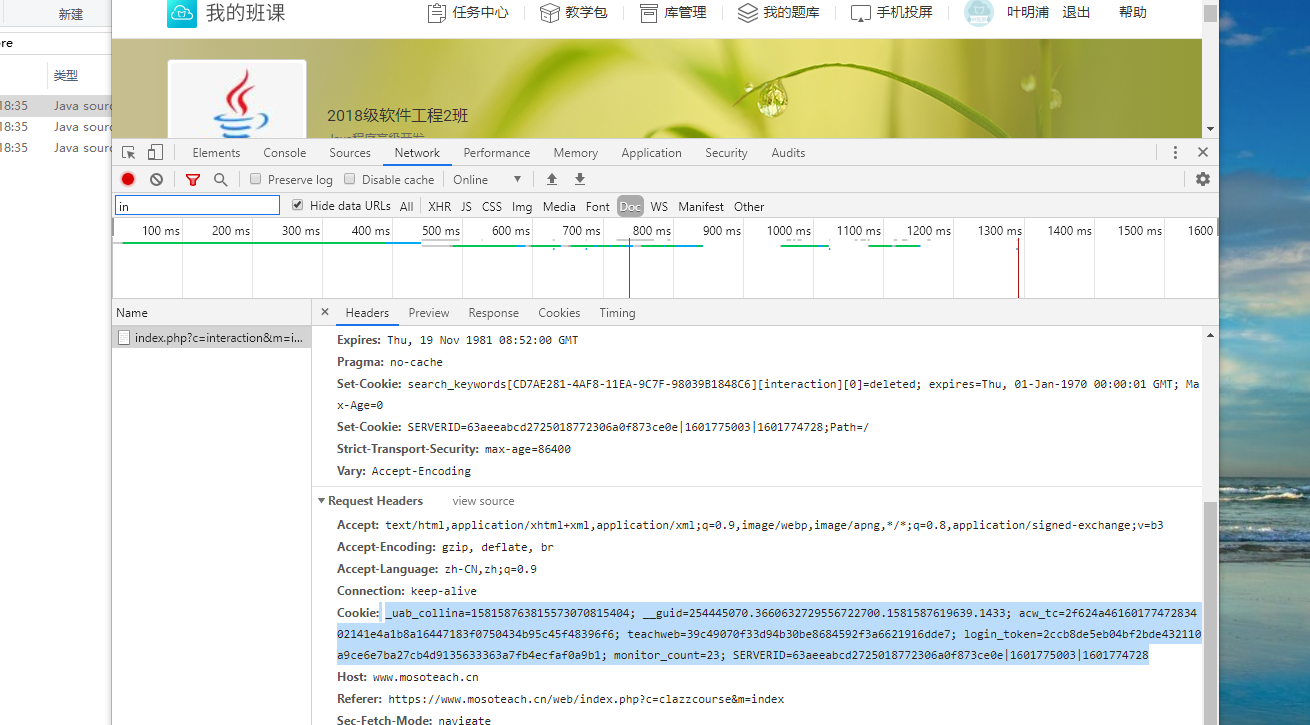
需要先获取网页的地址和进入该地址的cookie。在需要进入的网页登入后按f12,如下图所示找到cookie。
![]()
-
然后放入配置文件,根据
Properties prop = new Properties();
prop.load(new FileInputStream("./resources/config.properties"));
Document doc = Jsoup.connect(prop.getProperty("url")).header("Cookie", prop.getProperty("cookie")).get();
代码便可以进入网页进行解析,由于cookie值是会变的,所以每过一段时间需要重新修改cookie值。
2.进入各个活动的网页:
- 普通的java提取网页数据比较麻烦,因此需要导入Jsoup包进行数据提取会更加的方便。
- 可以通过getElementsByClass("interaction-row")来获取主网页的各个活动的网页代码。
3.数据的提取:
- 通过jsoup的get和select找到数据所在节点和数据旁的便签来爬需要的数据,
不够因为对爬取数据不熟悉,我对张榕城的代码有一定的借鉴。
4.存入文件:
- 用
File txt = new File("score.txt");新建一个文件 - 用
PrintWriter writeit = new PrintWriter(new FileWriter(txt));和writeit.print
可以讲数据存入文件。除了PrintWriter方法外还可以使用BufferedWriter也是可以的 - 存完数据后要将writeit.close.
5.输出结果:

总结:
- 对于文件的解析我并不是很了解,又没有去认真的学习过,参考了其他同学的资料后其实也不是很懂。
只明白了登入页面需要使用的cookie获取和主网页代码的获取,但里面的特定数据爬取其实还是很迷茫。 - 本来想要使用map集合的,因为map集合在数据的处理会更加的方便。但由于map集合的很多规则和方法
已经记得不清楚了,就使用了数组。 - 代码最后其实还是爬取失败了,我想我需要去好好的学习一下java爬虫的知识了。
参考资料:
https://gitee.com/RongC_Zhang/pair
https://www.cnblogs.com/jamaler/p/11645569.html
https://search.bilibili.com/all?keyword=java%E7%88%AC%E8%99%AB&from_source=nav_search_new

 浙公网安备 33010602011771号
浙公网安备 33010602011771号