


数据库索引
- 知识准备
- 顺序文件上的索引
- 非顺序文件上的辅助索引(Secondary Indexes)
- B+树
- 散列表(Hash Tables)
知识准备:
存储器结构:

计算机体系结构
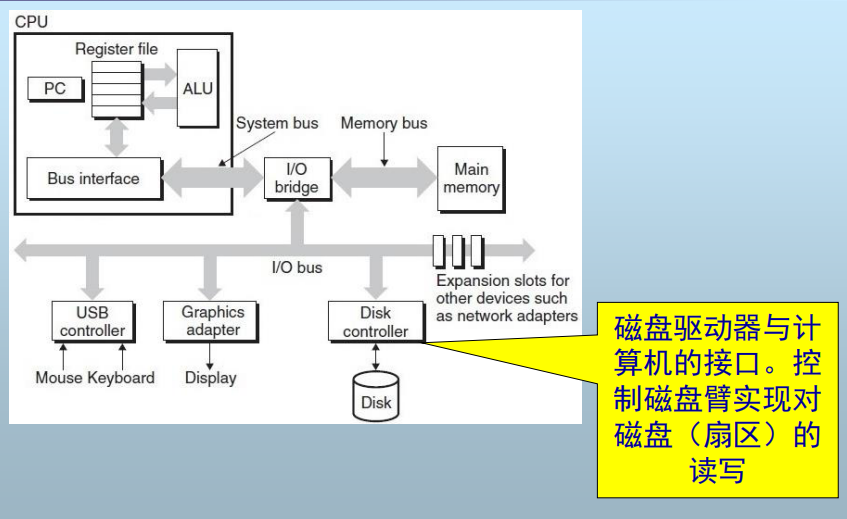
磁盘结构(上图 Disk )
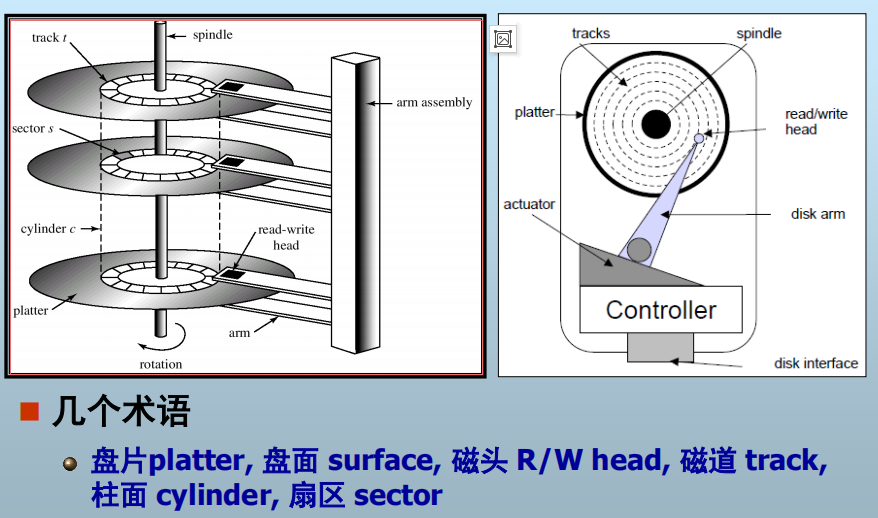
单个盘面:
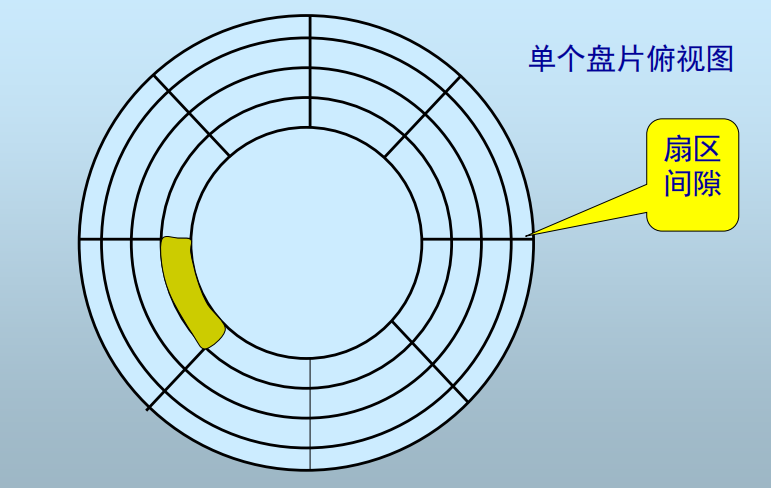
块(Block)的概念:
- OS或DBMS进行磁盘数据存取(I/O)的最小逻辑单元,
- 由若干连续扇区构成
- 块是DBMS中数据存取的最小单元
- 扇区是磁盘中数据存储的最小单元
磁盘块读取时间:
从“发出块存取请求”到“块位于主存”的时间
=寻道时间S+旋转延迟R+传输时间T+其它延迟
记录(一行数据)在块中的组织:
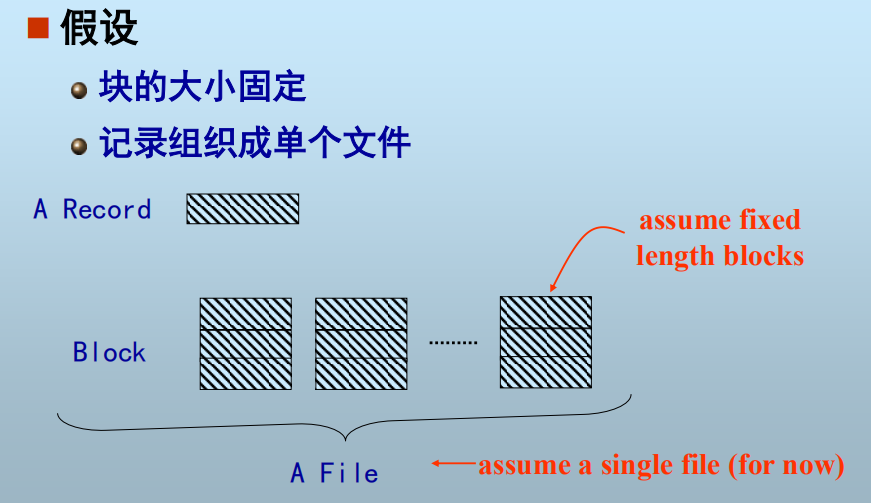
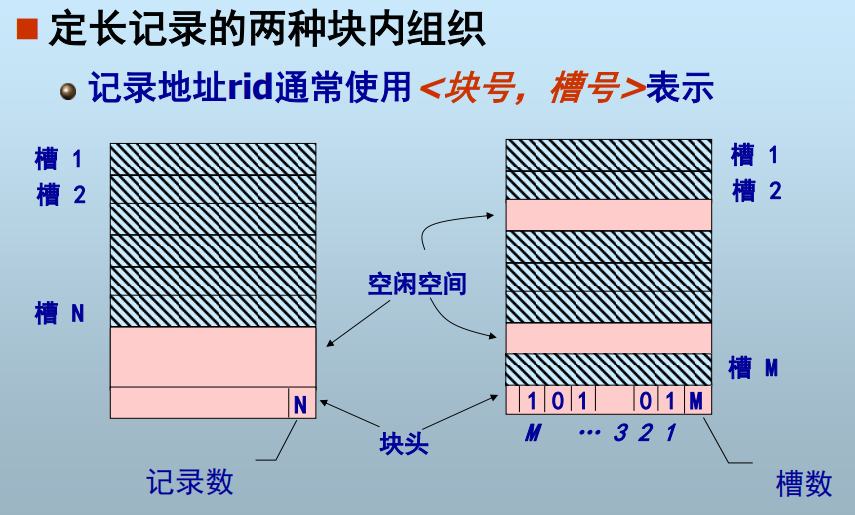

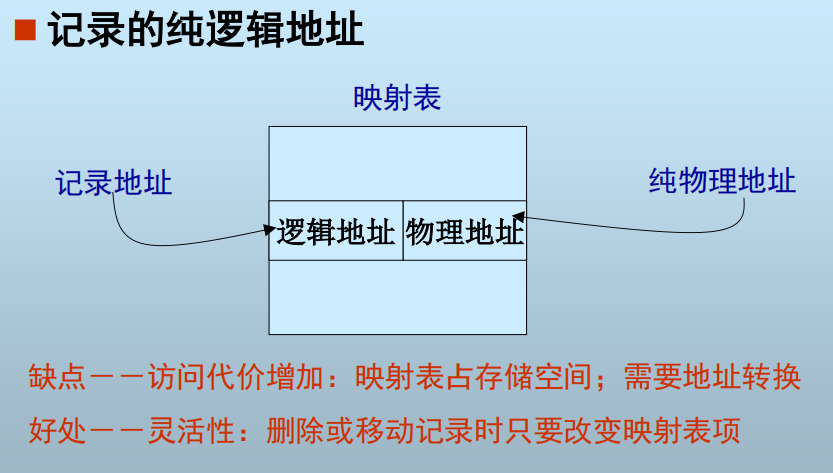
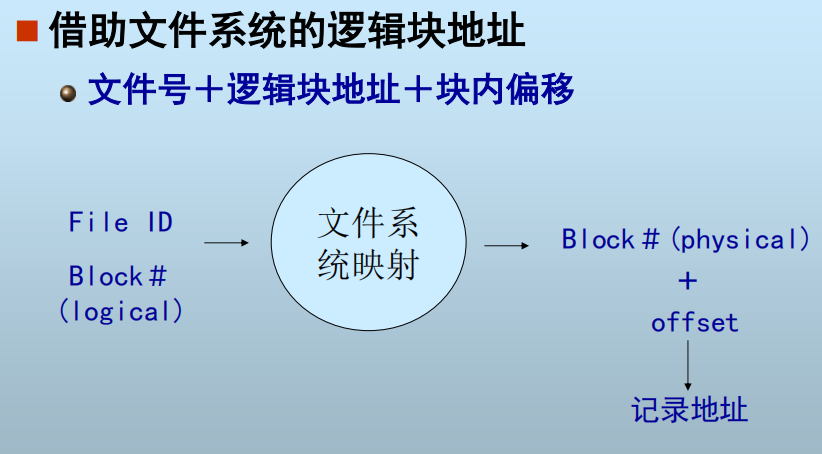
记录地址映射:

顺序文件上的索引
顺序文件: 记录按查找键排序存储
1. 密集索引(Dense Indexes)
每个记录都有一个索引项
索引项按查找键排序
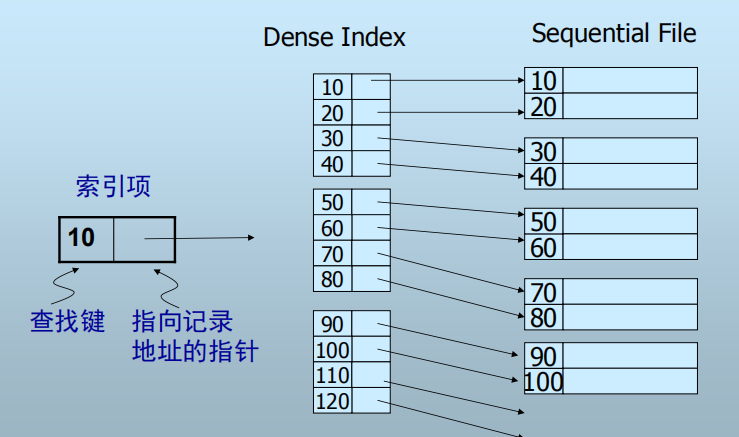
为什么使用密集索引?
- 记录通常比索引项要大
- 索引可以常驻内存
- 要查找键值为K的记录是否存在,不需要访问磁盘数据块
密集索引缺点?
- 索引占用太多空间 --->> 用稀疏索引改进
2. 稀疏索引(Sparse Indexes)
仅部分记录有索引项
一般情况:为每个数据块的第一个记录建立索引
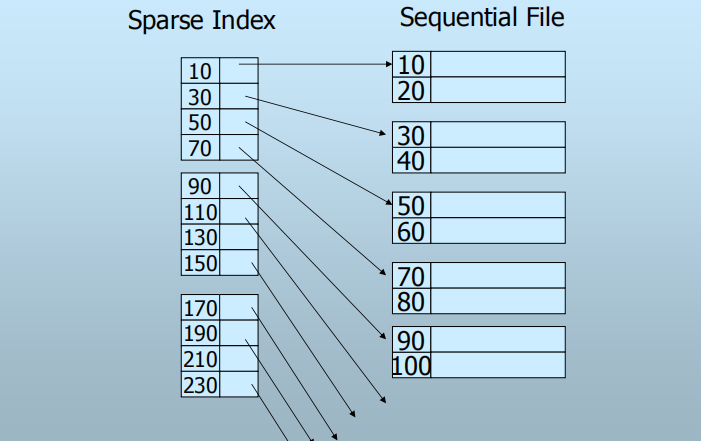
有何优点?
- 节省了索引空间
- 对同样的记录,稀疏索引可以使用更少的索引项
有何缺点?
- 对于“是否存在键值为K的记录?”,需要访问磁盘数据块
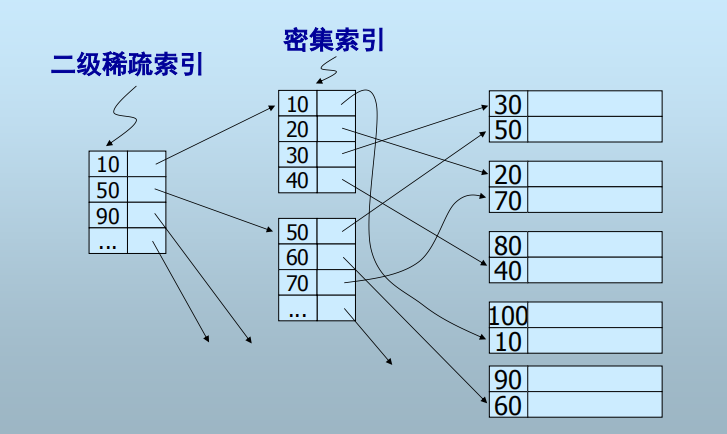
3. 多级索引(Multi-level Index)
索引上再建索引: 二级索引、三级索引……
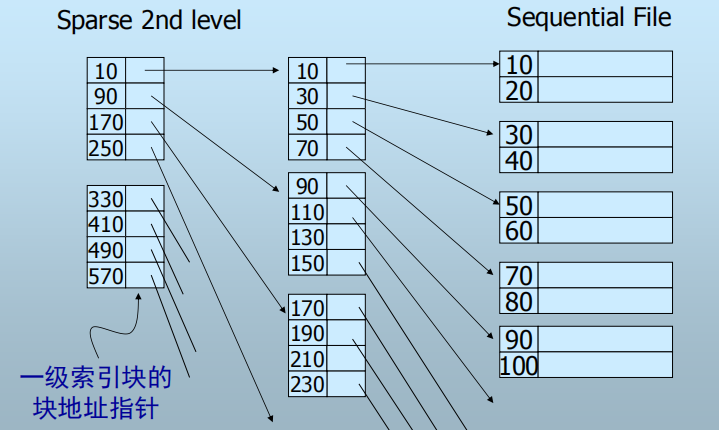
多级索引的好处?(二级索引指向一级索引块的头部)
- 一级索引可能还太大而不能常驻内存
- 二级索引更小,可以常驻内存
- 减少磁盘I/O次数
索引的理解和应用:

辅助索引(Secondary Index)
- 数据文件不需要按查找键有序(数据存储不是按字段的顺序存储)
- 根据索引值不能确定记录在文件中的顺序(位置)
- 辅助索引的一级索引必须是密集索引
当一级索引不是密集索引:无法查找某些值
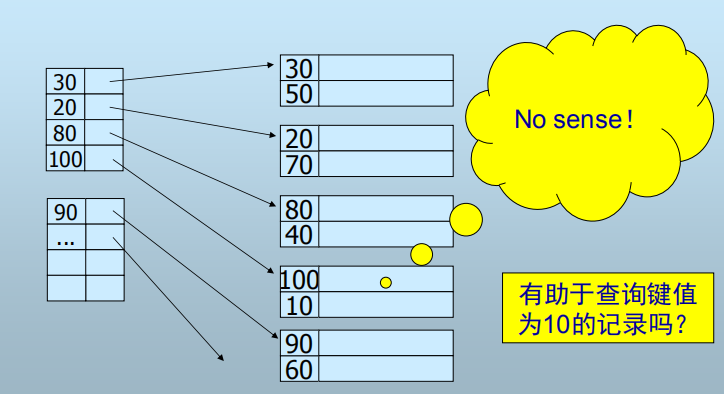
密集索引:
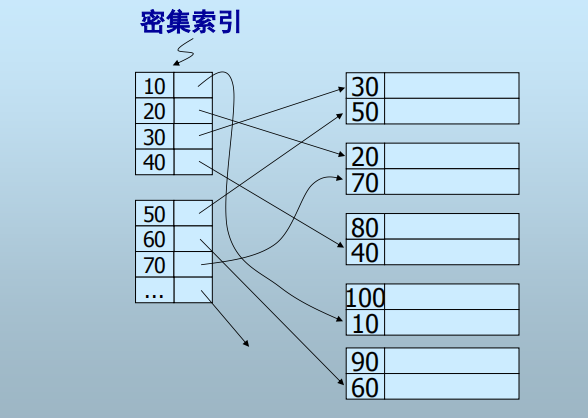
多级索引:
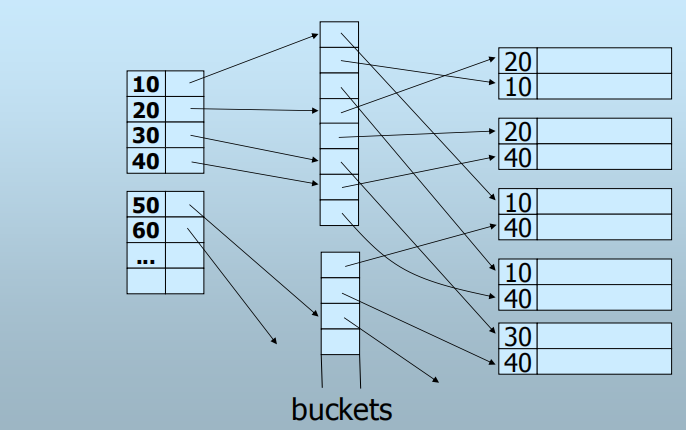
重复键值——间接桶
该索引字段(NOT UNIQUE), 采用密集索引浪费空间
间接桶:介于辅助索引和数据文件之间
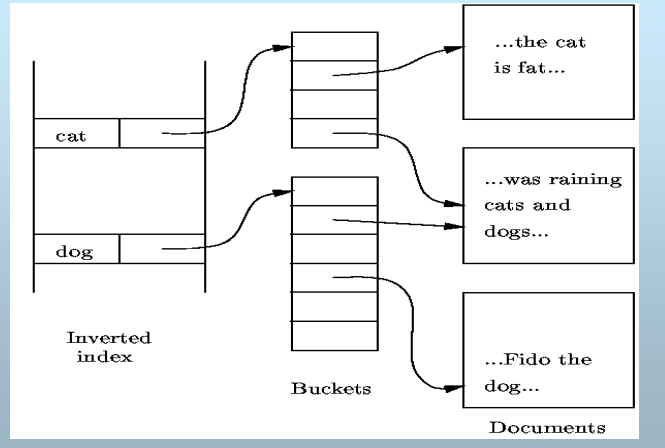
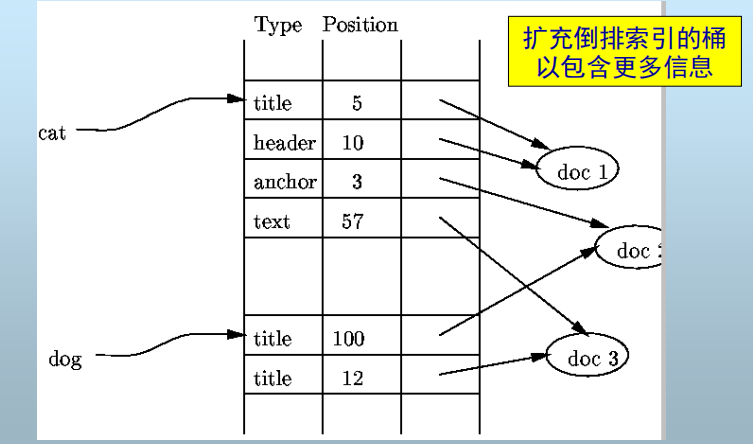
倒排索引(Inverted Index)
应用于文档检索,与辅助索引思想类
不同之处:
- 记录 --> 文档
- 记录查找 --> 文档检索
- 查找键 --> 文档中的词
思想:
- 为每个检索词建立间接桶
- 桶的指针指向检索词所出现的文档
B+树
一种树型的多级索引结构
树的层数与数据大小相关,通常为3层
所有结点格式相同:n个值,n+1个指针
所有叶结点位于同一层
适用于主索引,也可用于辅助索引
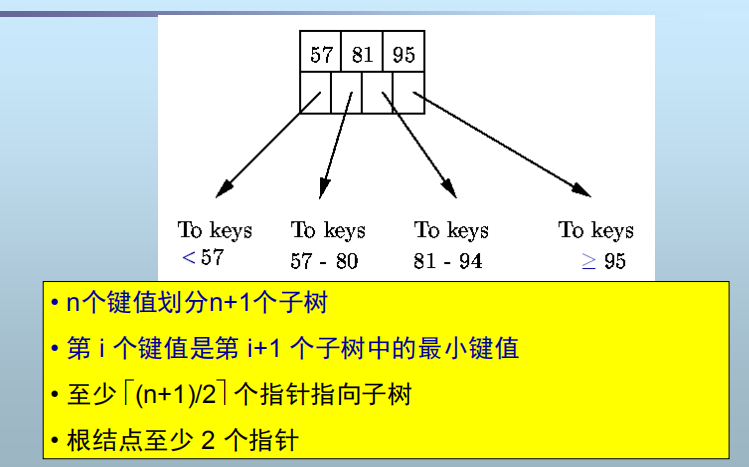
查找:
从根结点开始
沿指针向下,直到到达叶结点
在叶结点中顺序查找
插入:
查找插入叶结点
若叶结点中有空闲位置(键),则插入
若没有空间,则分裂叶结点
- 叶结点的分裂可视作是父结点中插入一个子结点递归向上分裂
- 分裂过程中需要对父结点中的键加以调整
- 例外:若根结点分裂,则需要创建一个新的根结点
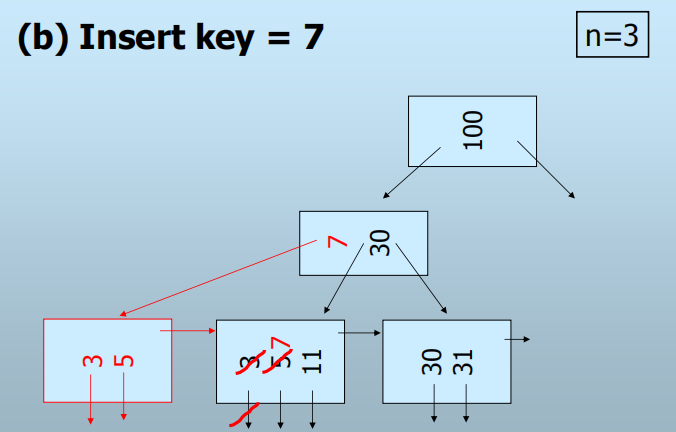
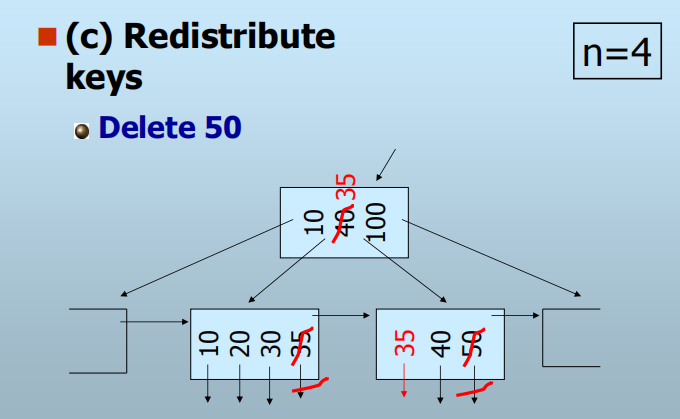
删除:
查找要删除的键值,并删除之
若结点的键值填充低于规定值,则调整
- 若相邻的叶结点中键填充高于规定值,则将其中一个键值移到该结点中
- 否则,合并该结点与相邻结点:合并可视作在父结点中删除一个子结点
- 递归向上删除
若删除的是叶结点中的最小键值,则需对父结点的键值加以调整
效率:
访问索引的I/O代价=树高(B+树不常驻内存)或者0(常驻内存)
树高通常不超过3层,因此索引I/O代价不超过3(总代价不超过4)
通常情况下,根节点常驻内存,因此索引I/O代价不超过2(总代价不超过3)
散列表(Hash Table)
散列函数(Hash Functions)
- h:查找键(散列键) → [0…B – 1]
- 桶(Buckets), numbered 0,1,…, B-1
散列索引方法
- 给定一个查找键K,对应的记录必定位于桶h(K)中
- 若一个桶中仅一块,则 I/O次数=1
- 否则由参数B决定,平均=总块数/B
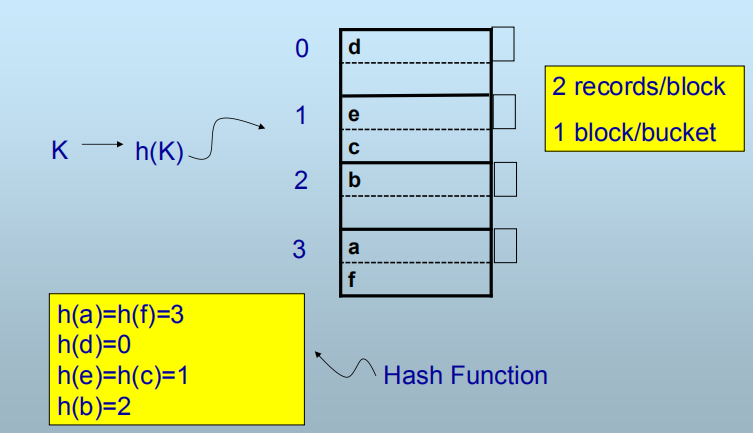
查找:
- 对于给定的散列键值k,计算h(K)
- 根据h(K)定位桶
- 查找桶中的块
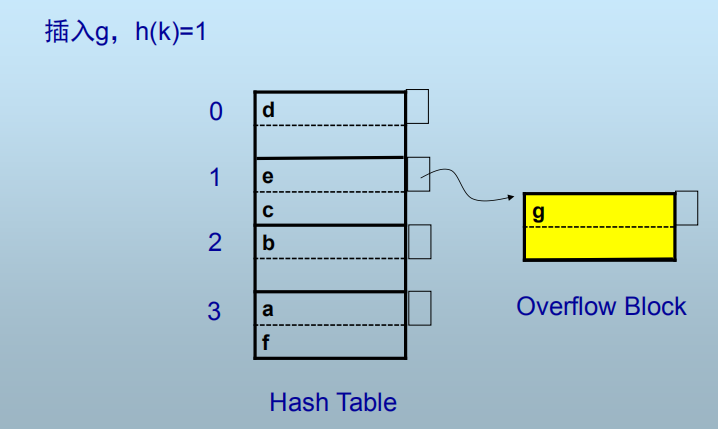
插入:
计算插入记录的h(K),定位桶
若桶中有空间,则插入
否则:创建一个溢出块并将记录置于溢出块中
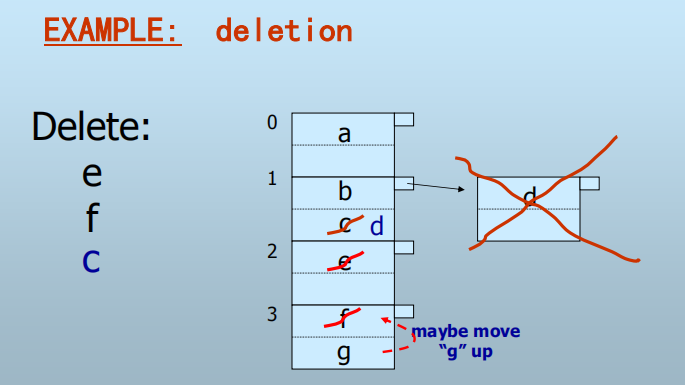
删除:
根据给定键值K计算h(K),定位桶和记录
删除: 回收溢出块
空间利用率:
- 实际键值数 / 所有桶可放置的键值数
- <50%:空间浪费
- >80%:溢出问题
- 50%到80%之间(GOOD!)
文件增长——动态散列
数据文件的增长使桶的溢出块数增多,增加I/O
采用动态散列表解决
- 可扩展散列表(Extensible Hash Tables)
- 成倍增加桶数目
- 线性散列表(Linear Hash Tables)
- 线性增加
1. 可扩展散列表
散列函数h(k)是一个b(足够大)位二进制序列,前i位表示桶的数组(映射)。
i 的值随数据文件的增长而增大
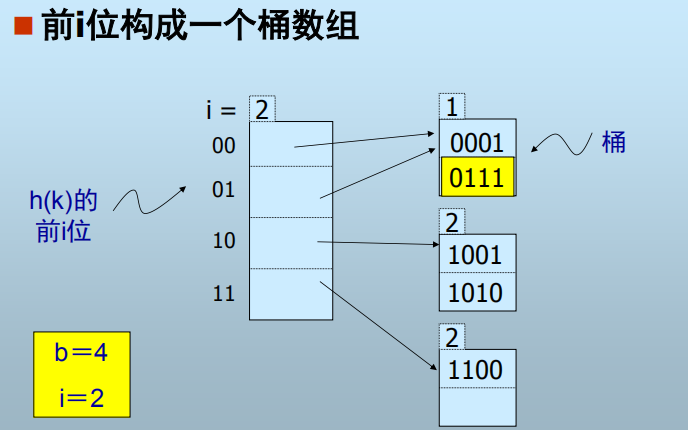
优点:
- 当查找记录时,只需查找一个存储块。
缺点:
- 桶增长速度快,可能会导致内存放不下整个桶数组,影响其他保存在主存中的数据,波动较大。
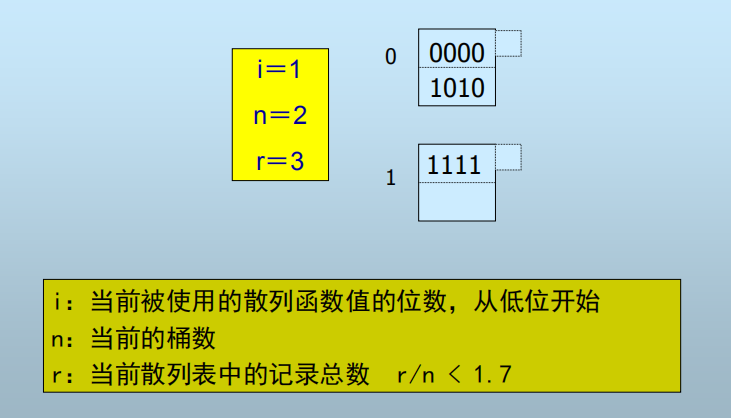
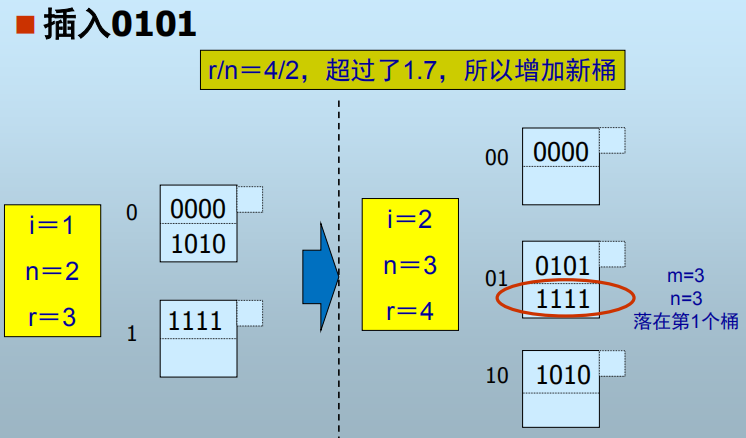
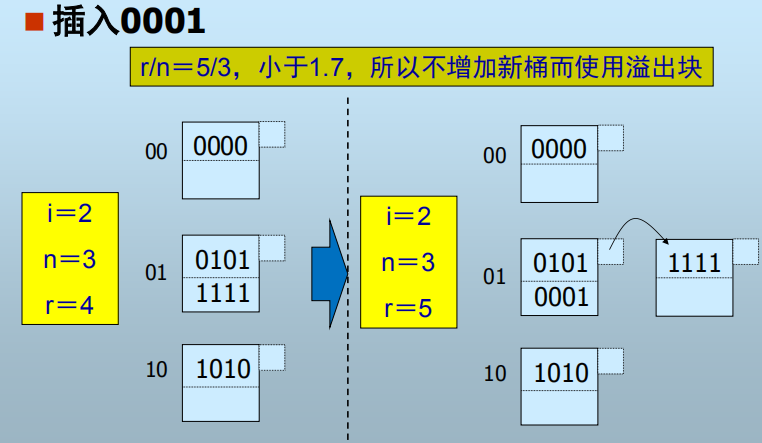
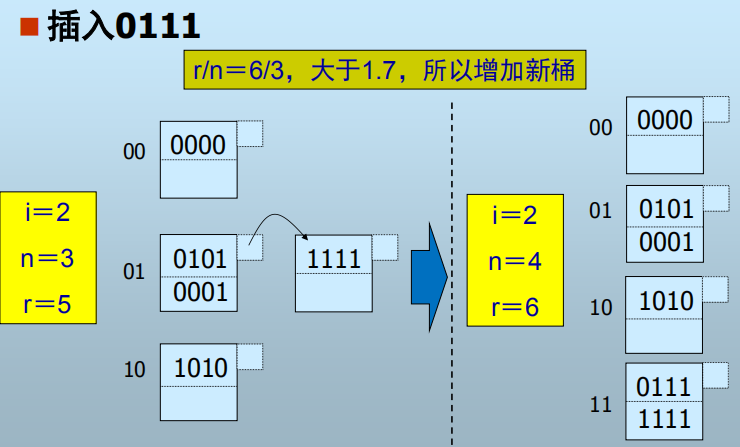
2. 线性散列表
h(k)仍是二进制位序列,但使用右边(低)i位区分桶
- 桶数=n,h(k)的右i位=m
- 若m<n,则记录位于第m个桶
- 若n m < 2i,则记录位于第 m-2i-1 个桶
- n的选择:总是使n与当前记录总数r保持某个固定比例
- 意味着只有当桶的填充度达到超过某个比例后桶数才开始增长
桶增加流程:
本 文 终 ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号