3000+长文带你进入KMP算法思想
1. 基本介绍
1.1 说明
时间复杂度:\(O(N)\);
空间复杂度:\(O(N)\);
KMP 算法是一种字符串匹配算法,是对传统朴素匹配算法的优化,充分利用已经进行过的匹配结果和字符串本身的性质进行优化的高效算法。
我们将会先介绍流程,让大家的在充分的实践 KMP 算法的过程,等待过程已经熟悉了,就会与传统匹配算法进行对比,深切的体会到传统匹配的算法与 KMP 算法的局限性,加深对 KMP 的思想的掌握。
1.2 一些约定
为下面介绍的方便,我们在开始讲述之前,先约定一些符号的含义。
- 假设有一个字符串 T,那么 \(T[0...k]\) 代表下标从 0 到 k 的子串,\(|T|\) 就表示字符串的长度,\(T_A\) 代表 A 字符在 T 内对应的下标;
- 字符串拼接。假设有另一个字符串 S,那么将 S 拼接在 T 后面就表示为 TS;
- 任意字符 A 的前缀串表示为 \(pre_A[0...i]\),后缀串表示为 \(post_A[j...T_A-1]\);
1.3 前缀串和后缀串的最大匹配长度
KMP 算法的核心就是利用了一个 next 的信息数组,使得其能够利用前面匹配失败的部分结果。
next 数组统计的是 s2 字符串中每一个位置 i 的前缀串和后缀串的最大匹配长度。
什么是前缀串和后缀串?
假设有 s2=abcabck,那么 k 位置的前缀就为 s2[0...i],后缀就为 s2[j...(k-1)],其中 i 可以大于 j,但是 i 不能达到最大长度 6,也就是 k 的最大前缀(后缀)串长度。
即 k 的前缀串和后缀串不能是 abcabc,但可以是 abcab。
对于 0 位置的字符和 1 位置的字符,信息分别固定为-1 和 0(人为规定的)。
要把每一个位置的信息求出来(信息数组 next),让我们的匹配过程加速。
若要在 s1 中匹配 s2,那么就在 s2 中求 next 数组。
2. KMP 基本流程
2.1 流程
- 求 next 数组(求 next 数组有一个很高效的流程,我将放在后面特别的说明);
- 若 x,y 位置的字符可以相互匹配,就让 xy 同步后移(s1,s2 之间均没有偏移量 s);若 y 位于 s2 的首位置(
next[y]==-1),就让 s2 再往后移一位(x++);否则,就让y=next[y],即让 s2 右移到前缀串的后一个位置; - 如此循环往复,直到 x 或者 y 有一方越界:
- 若 y 越界,就说明找到了匹配的字符串;
- 若 x 越界将说明没有找到,x 就代表 s1 和 s2 比对的开头,若穷尽了所有的开头都没有扎到匹配,就说明没有找到;
2.2 实例演示
-
假设我们有
s1[i...X]=abcdegabck,s2[0...]=abcdegabk; 显然,此时next[y]=3,所以将 Y 指向 s2 的 3 位置,这样我们就可以省略s1[0...2]的字符比对,很大的提高了效率。
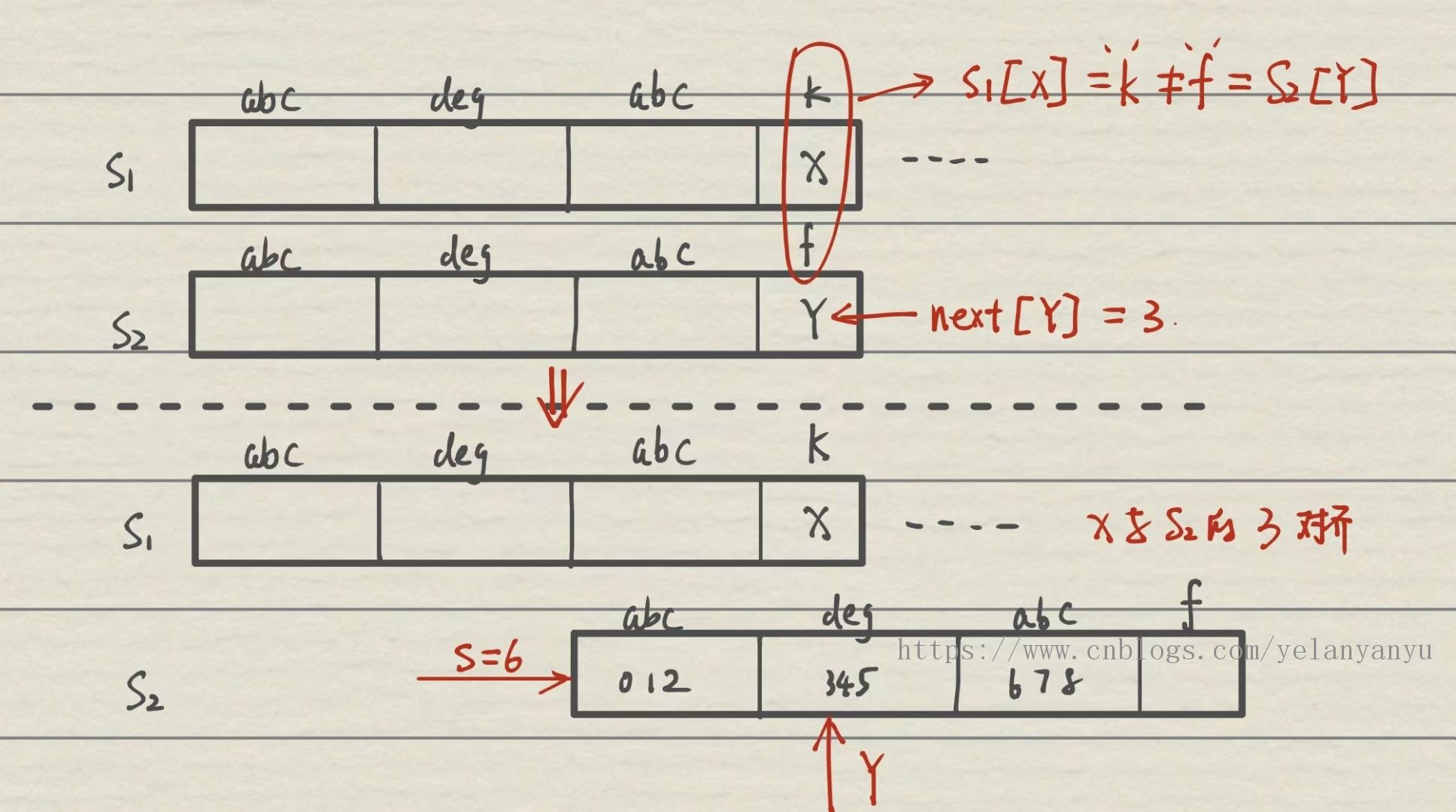
-
但是现在 3 位置的字符‘d’仍不与 s1 中 x 相等,而
next[3]=0,所以将 Y 再次指向 0 位置的 a。
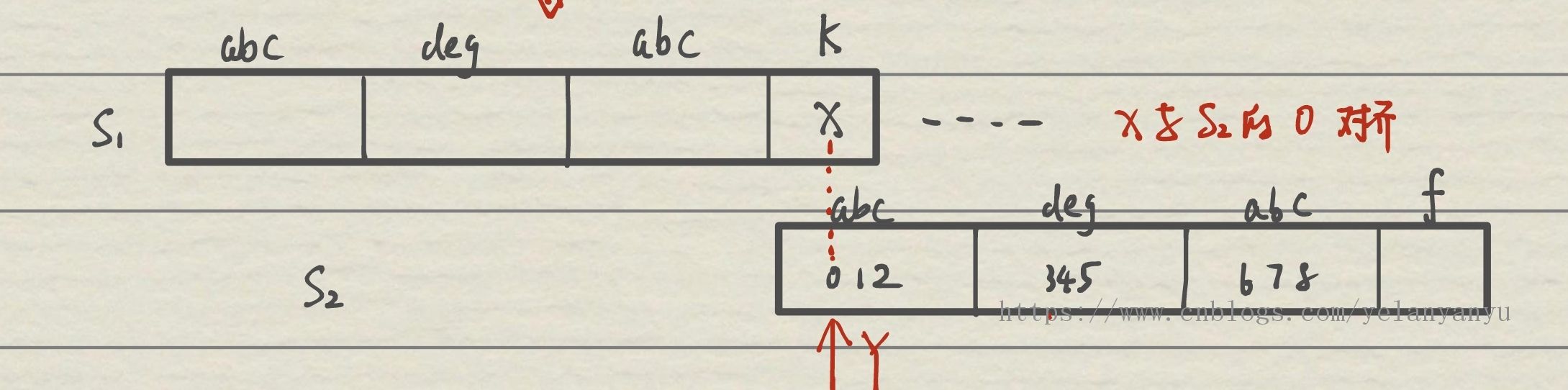
-
此时
next[y]=-1,Y 不能向前走了,于是将 x++(将 x+1 位置的字符与 s2 0 位置的字符进行比对);
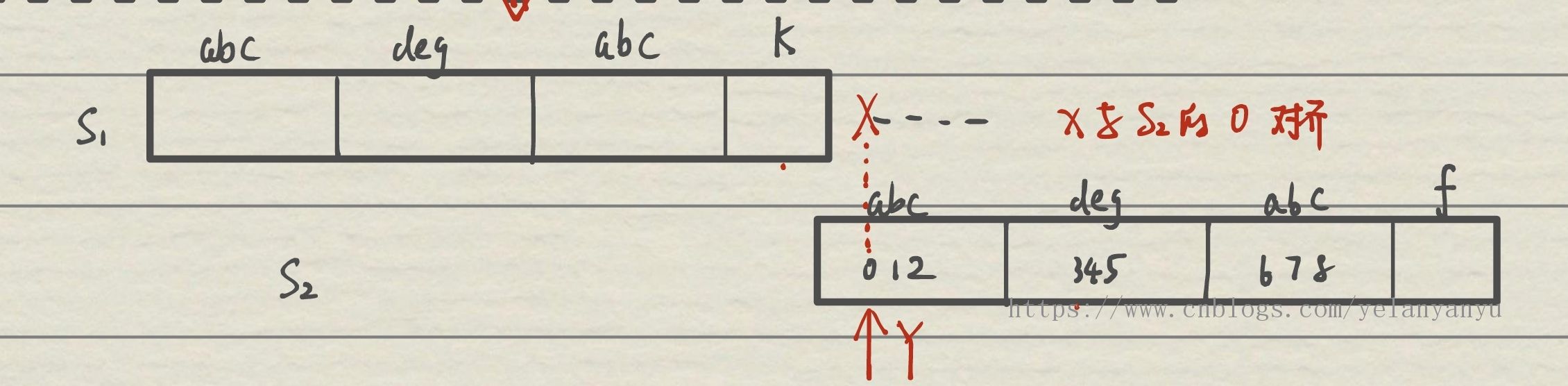
-
之后再开始新一轮相同模式的的匹配;
2.3 代码实现
由于还没有将 next 数组的优化实现,所以我们以黑盒的形式将代码呈现出来。next 数组将在下一节详细说明。
public static int getIndexOf(String s1, String s2) {
//无效条件
if (s1 == null || s2 == null || s2.length() < 1 || s1.length() < s2.length()) {
return -1;
}
char[] str1 = s1.toCharArray();
char[] str2 = s2.toCharArray();
int x = 0;//s1 中第一个不匹配的位置
int y = 0;//s2 中相应第一个不匹配的位置
int[] next = getNextArray (str2);//得到next 数组
//若y越界了,就匹配到了(只有一直相等y才会跳出s2)
//x越界了,说明尝试了所有的开头都没有找到匹配
while (x < str1.length && y < str2.length) {
//相等就往后移,直到找到不匹配的
if (str1[x] == str2[y]) {
x++;
y++;
} else if (next[y] == -1) { // y == 0,只有0位置的next值为-1
//已经不能往左跳了
x++;//相当于s2再次右移,将y与x对齐,此时y==0
} else {//还能往左跳,就将s2“右移”,s1不动
y = next[y];
}
}
//x-y就代表开头的位置,因为y越界了就相当于y=s2的长度
return y == str2.length ? x - y : -1;
}
3. next 数组求法
3.1 思路
3.1.1 朴素求法
当然,几乎所有人第一个想到的思路就是采用遍历的方法一个个找到前缀和后缀。即,定义下标 i 从 0- \(|S_2|-2\),j 从 \(|S_2|-2\) -0,看对应位置的字符是否相等,若相等就让最大匹配长度加 1 。但是这样显然是低效的。
3.1.2 归纳求法
- 首先,毫无疑问,
next[0]==-1,next[1]==0。 - 现在考虑
next[2],很显然,若 0 位置和 1 位置的字符相同 2 位置的数值就为 1,否则就为 0; - 现求
next[3],假如 3 位置的字符与 0 位置的字符相同就意味着next[3]=next[2]+1,其实你应该可以看出我的暗示了。既然 3 位置的值可以由前面几位唯一确定,那么 n 位置的字符呢?没错就是利用归纳法构建 next 数组;
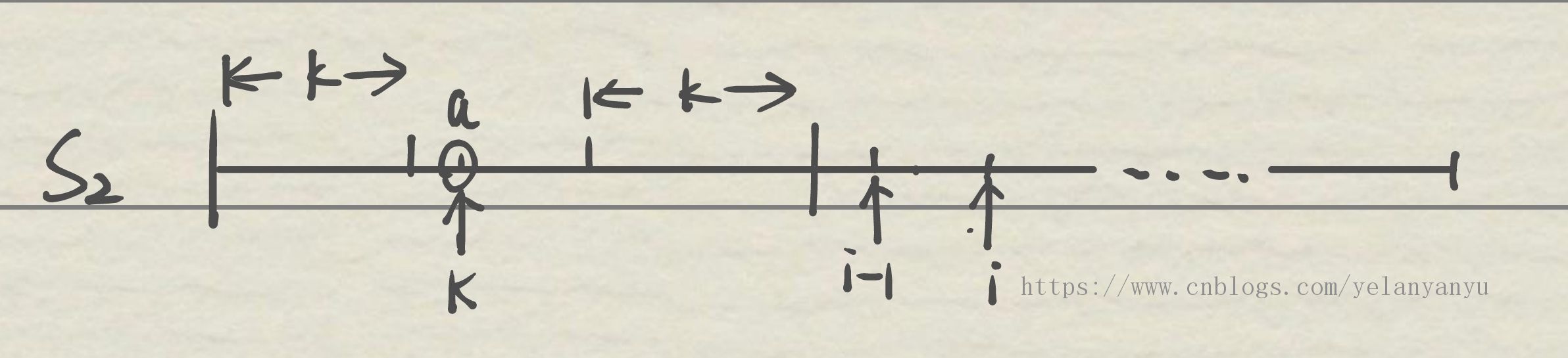
我们现在进行抽象化,假如现在待求next[i]为待求的值,假设 0... i-1 位置的 next 都已经求完了。现在的问题是怎么根据前 i 位的数据确定这 i+1 位的值。
设next[i-1]=k,s2 数组中 i-1 位置的前缀末尾的后一位为任意字符 a,显然 a 字符的下标就应该为 k,现有如下可能: - 假如 i-1 位置的值可以与 k 位置的字符 a 相同,那么
next[i]=next[k]+1; - 假如 i-1 位置的值与 k 位置字符不同。那么就重新更新 k 的值:看看 k 的前缀的后一个字符是不是与 i-1 位置相同,即
k=next[k];
3.2 代码实现
private static int[] getNextArray(char[] str2) {
if (str2.length == 0 || str2 == null) {
return null;
}
if (str2.length == 1) {
return new int[]{-1};
}
int[] next = new int[str2.length];
next[0] = -1;
next[1] = 0;
int pn = 0;//记录前缀的后一个位置的next值
int i = 2;
while (i < str2.length) {
if (str2[i - 1] == str2[pn]) {
/*
若相应字符相同则i位置的next值就为pn位置的next值+1;
同时更新i和pn的值:判断下一个字符
*/
next[i++] = ++pn;
} else if (pn > 0) {
/*
不断更新pn的值,也就是不断寻找能与str[i-1]匹配的pn值,
直到越界
*/
pn = next[pn];
} else {
/*
假如找不到相应的pn,使得pn对应的字符和i-1位置的字符相同,
i位置的next值就为0,同时去判断下一个字符
*/
next[i++] = 0;
}
}
return next;
}
4. next 数组优化原理
我们为什么要费劲心思的去设计这样一个前缀后缀串的最大匹配数呢?
从两个角度去解读,一是前后缀匹配,二是最大。
4.1 前后缀匹配
如果我们熟悉我这里定义的前后缀的流程,我们就会轻易的发现,所谓的前后缀匹配就是在设法找到在对称性。next[i] 的数值就表示,i 位置前面(0-i-1)中,最大有多长的对称串。
为什么要找对称性呢?从直观上来讲,就是为了在我们更新 y 值的时候可以让 X 前面的字符串最大限度与 y 位置的前缀相匹配。这一定很抽象对吧!结合上面的 [[KMP算法#实例演示|实例演示]]再看看?
总的来说,正是因为有这种对称性,所以当我们置 y=next[y] 的时候,才可以造就 s1 和 s2 再新一轮匹配的时候是部分匹配,而不是一盆撒完重新装一盆。
4.2 最大匹配字符数
正如在上一小节所说的,next 数组记录的就是每个位置前面的最长对称串。
那么为什么要最长呢?就是在最大限度的利用前几次匹配的成果(部分匹配)省略了一些比较的过程。
相信大家看到这里一定是一脸懵逼,什么部分匹配,什么前缀后缀,全部搞混了。没关系,这是缺乏亲身经历的现象,只要大家把我上面写到的实例演示用到的例子分别用 KMP 和暴力匹配的流程走个几遍就可以明白我说的话了。
4.3 实质及相关证明
4.3.1 实质
我们在这一节进行相关的数学证明。
有如下问题:
1. 凭什么将 y=next[y] 后就可以得到部分匹配的效果?
2. 你怎么保证这个部分匹配是最大限度的呢?为什么不能再继续加长呢?
解答:
1. 为什么一定要尝试 j 开头的字符呢?i 到 j 内的字符都不能配出 s2(待证明);
2. 将 s1 的 j 位置对准 s2 的开头重新开始匹配,那么我们可以直接从 z 位置开始看,因为 0-z 和 j-x 的字符一定是相等的。相当于 s2 数组向右滑动到最大距离(待证明);
4.3.2 证明
命题:
假设我们有字符串 s1[0...m] 和模式字符串 s2[0...n]。
设 s1 从下标 i 开始就可以和 s2 进行匹配,直到到 h 位置字符才出现不一样,此时 x 处于 x+h,y 处于 h 位置。
设 \(pre_{S_1}[0...z-1]\),\(post_{S_1}[j...h-1]\),此时前缀和后缀串均是 h 位置的最大匹配长度。z 代表前缀串的后一个字符。
如下图:(勘误,s1 字符串中的 h 应该为 x+h)
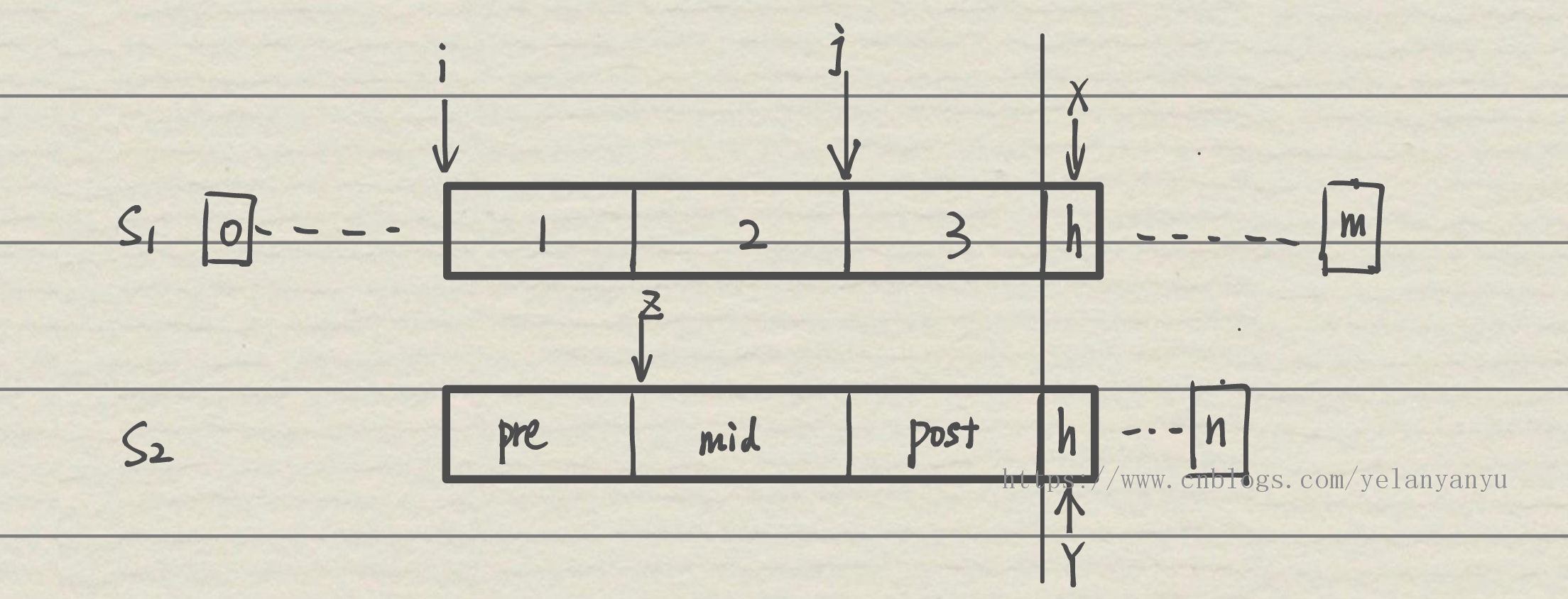
证明 1:i 到 j 内的字符都不能配出 s2(证明):
利用反证法,反设 s1 中 k 位置(i<=k<j)可以配出 s2 。由于字符串是匹配到 x,y 位置才停止的,所以说 s1 i 到 x-1 位置的字符串必定和 s2 0 到 y-1 字符串相同, 即 \(S_1[i...x-1]==S_2[0...y-1]\)。于是 s2 中就必然存在一个后缀 \(post_{S_2}[k^{'}...Y-1]==S_1[k...x-1]\)。然而 k< j,也就意味着 s2 中有了一条更长的后缀,这与原来已经规定的前缀后缀最大长度矛盾了。证毕。
证明 2:由上图,即证明 pre == post。由预设条件,这是显然的。
5. 传统匹配算法的局限性
有了前面的基础,我相信对于传统的匹配算法的局限性就好理解多了。
传统匹配算法也称 BruteForce 暴力匹配算法。别看取了一个英文名,其实就是我们每一个人都能第一时间想出来的简易算法。那么为什么这么算法这么暴力呢?举个例子就明白了。
假设有字符串 s1,s2(如下图所示):
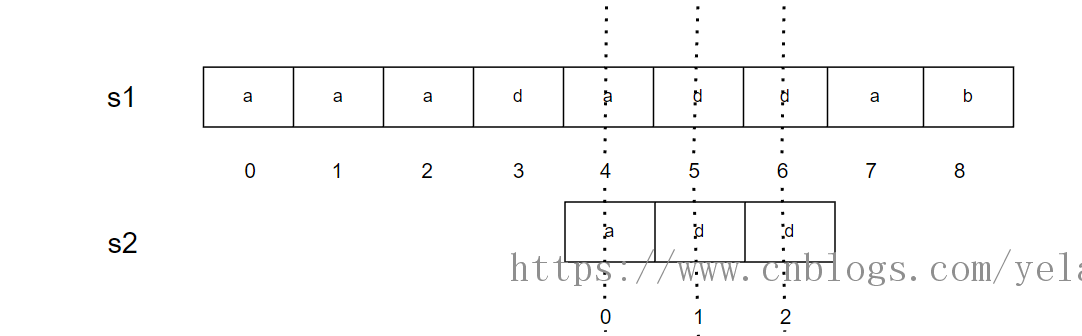
于是暴力匹配的流程就是:
1. 先以第一个元素 i=0 作为起始,然后往后匹配,若 i=0 后面的每个元素都跟 s2 顺序相配就找了 s2;若有一个元素没有找到就直接让 i++,以第二个元素 i=1 作为起始点开始逐个去寻找和 s2 相匹配的子串;
2. 若 \(i=|s1|-|s2|+1\) 时仍没有找到合适匹配,那么 s1 中就无法找到 s2;
3. 总结一下,以上的流程就相当于 s2 是一个窗口,0 位置就相当于是窗口的开头,2 位置就相当于是窗口的末尾,如果窗口在当前位置没有匹配成功,就将窗口向右移动一个位置,直到匹配上或者窗口的末尾超出了 s1 的末尾为止;
时间复杂度 \(O(N*M)\),M 为待匹配字符串长度。
暴力匹配算法的局限性就在于会浪费前几此匹配失败的部分结果。若遍历到了 1 位置,那么 0 开头所作的努力就被浪费了。例如,从 1-4 位置开始匹配,那么之前 0-3 匹配的努力就被浪费了。
而在 KMP 算法中,我们利用 next 数组保存前后缀串的最大匹配长度,充分的利用了字符串本身的对称性,从而才得以利用前面的匹配的结果进行优化。
6. 时间复杂度证明
6.1 while 循环
证明 while 循环的时间复杂度为 \(O(N)\) :
1. x,y 不可能超过 s1 长度 n;
2. x-y 的最大值就为 n(x 取 n,y 取 0);
3. 当进入第一个分支的时候,x-y 不变;第二个分支的时候,x-y 上升;第三个分支减小 y,x-y 减少;
4. 所以极端情况下,这三个分支发生的次数不超过 2N,所以复杂度就为 \(O(N)\);
x-y 在数学上是什么含义?一个量增加一个量减少,x-y 只是用来评价变化幅度的方法。
6.2 next 函数的复杂度证明
next 函数复杂度证明 \(O(N)\) :
证明方法与 while 一样。这里就略去给读者自行练习了。
结语
KMP 算法对于前面的结果的充分利用着实惊为天人。这启示我们不要轻易的放弃前面的内容,这说不定可以为我们下面的过程做出很大的优化。
我是根据自己的理解,写下这篇文章,其中必有许多小错误和不足,还请读者们大胆指出,我会虚心接受的大家的批评和建议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号