天梯赛刷题记录
L1-2 再进去几个人
题目描述
题干太长了不想看,随便输出 B−A 就行。
输入格式
输入在一行中给出 2 个不超过 100 的正整数 A 和 B,其中 A 是进去的人数,B 是出来的人数。题目保证 B 比 A 要大。
输出格式
在一行中输出使得房子变空的、需要再进去的人数。
测试数据
输入样例
4 7
输出样例
3
解题思路
输出 B−A 即可。
#include<bits/stdc++.h>
using namespace std;
#define ios ios::sync_with_stdio(false), cin.tie(0), cout.tie(0)
int main(){
ios;
int a, b; cin >> a >> b;
cout << b - a << "\n";
return 0;
}
L1-024 后天
题目描述
如果今天是星期三,后天就是星期五;如果今天是星期六,后天就是星期一。我们用数字1到7对应星期一到星期日。给定某一天,请你输出那天的“后天”是星期几。
输入格式
输入第一行给出一个正整数D(1 ≤ D ≤ 7),代表星期里的某一天。
输出格式
在一行中输出D天的后天是星期几。
测试数据
输入样例:
3
输出样例:
5
解题思路
cpp
#include <bits/stdc++.h>
using namespace std;
#define ios ios::sync_with_stdio(false),cin.tie(0),cout.tie(0)
int main(){
ios;
int n;
cin >> n;
n = (n+2)%7;
if (n==0) n = 7;
cout << n << "\n";
return 0;
}
python
x = int(input())
x = x + 2
if x>7:
x = x % 7
print(x)
7-3 字母串
题目描述
英语老师要求学生按照如下规则写一串字母:
- 如果写了某个大写字母,下一个就必须写同个字母的小写,或者写字母表中下一个字母的大写;
- 如果写了某个小写字母,下一个就必须写同个字母的大写,或者写字母表中前一个字母的小写;
- 当然也可以什么都不写,就结束这个字母串。
例如 aAaABCDdcbBC 就是一个合法的字母串;而 dEFfeFGhI 就是非法的。注意 a 没有前一个字母, Z 也没有下一个字母。
现在面对全班学生交上来的作业,老师请你写个程序自动批改。
输入格式
输入在第一行给出一个不超过 100 的正整数 N。随后 N 行,每行给出一位学生的作业,即仅由英文字母组成的非空字母串,长度不超过 2×106。
输出格式
对每位学生的作业,如果正确就在一行中输出 Y,否则输出 N。
测试数据
输入样例:
2
aAaABCDdcbBC
dEFfeFGhI
输出样例:
Y
N
解题思路
#include <iostream>
using namespace std;
bool isValid(const string &s) {
int len = s.size();
for(int i = 0; i < len - 1; ++i) {
char curr = s[i];
char next = s[i + 1];
if(islower(curr)) { // 小写字母
if ((toupper(curr) != next) &&
!(curr > 'a' && next == curr - 1)) {
return false;
}
}
else if(isupper(curr)) { // 大写字母
if ((tolower(curr) != next) &&
!(curr < 'Z' && next == curr + 1)) {
return false;
}
}
else {
return false; // 不是英文字母
}
}
return true;
}
int main() {
int N;
cin >> N;
string s;
while(N--) {
cin >> s;
if(isValid(s)) {
cout << "Y" << endl;
} else {
cout << "N" << endl;
}
}
return 0;
}
7-4 找出总分最高的学生
题目描述
给定N个学生的基本信息,包括学号(由5个数字组成的字符串)、姓名(长度小于10的不包含空白字符的非空字符串)和3门课程的成绩([0,100]区间内的整数),要求输出总分最高学生的姓名、学号和总分。
输入格式
输入在一行中给出正整数N(≤10)。随后N行,每行给出一位学生的信息,格式为“学号 姓名 成绩1 成绩2 成绩3”,中间以空格分隔。
输出格式
在一行中输出总分最高学生的姓名、学号和总分,间隔一个空格。题目保证这样的学生是唯一的。
解题思路
输入样例
5
00001 huanglan 78 83 75
00002 wanghai 76 80 77
00003 shenqiang 87 83 76
10001 zhangfeng 92 88 78
21987 zhangmeng 80 82 75
输出样例
zhangfeng 10001 258
解题思路
一开始的代码,没有全部通过测试
#include <bits/stdc++.h>
using namespace std;
struct stu {
int num;
string name;
int c1;
int c2;
int c3;
};
int main(){
stu s1;
vector<stu> stu_vec;
int n;
cin >> n;
int n2 = n;
int ss1;
string ss2;
int ss3;
int ss4;
int ss5;
while(n--){
cin >> ss1 >> ss2 >> ss3 >> ss4 >> ss5;
stu_vec.push_back({ss1,ss2,ss3,ss4,ss5});
}
int max_index = 0;
int maxV=0;
int current_value = 0;
for(int i=0;i<n2;i++){
current_value=stu_vec[i].c1+stu_vec[i].c2+stu_vec[i].c3;
if(current_value>maxV){
maxV = current_value;
max_index = i;
}
}
cout<<stu_vec[max_index].name << " "<<stu_vec[max_index].num << " "<<maxV;
return 0;
}
后面问了ChatGPT才知道,我的学会使用int类型会导致前导0被去掉,正确的是用string类型
#include <bits/stdc++.h>
using namespace std;
struct stu {
string num;
string name;
int c1;
int c2;
int c3;
};
int main(){
vector<stu> stu_vec;
int n;
cin >> n;
string ss1, ss2;
int ss3, ss4, ss5;
for(int i = 0; i < n; ++i){
cin >> ss1 >> ss2 >> ss3 >> ss4 >> ss5;
stu_vec.push_back({ss1, ss2, ss3, ss4, ss5});
}
int max_index = 0;
int maxV = 0;
for(int i = 0; i < n; ++i){
int current_value = stu_vec[i].c1 + stu_vec[i].c2 + stu_vec[i].c3;
if(current_value > maxV){
maxV = current_value;
max_index = i;
}
}
cout << stu_vec[max_index].name << " "
<< stu_vec[max_index].num << " "
<< (stu_vec[max_index].c1 + stu_vec[max_index].c2 + stu_vec[max_index].c3);
return 0;
}
Python版本:
n = int(input()) # 输入学生数
max_total_score = -1 # 初始化最大总分为负数
best_student = None # 初始化最好的学生为 None
for _ in range(n):
line = input().split() # .split() 方法将输入分割成列表
student_id, name = line[0], line[1] # 学号和姓名
scores = list(map(int, line[2:])) # 3门课程成绩转为整数列表
total_score = sum(scores) # 计算总分
if total_score > max_total_score: # 如果当前学生的总分更高
max_total_score = total_score # 更新最大总分
best_student = (name, student_id, total_score) # 更新最好的学生
# 输出最好的学生信息
print(f"{best_student[0]} {best_student[1]} {best_student[2]}")
7-11 天梯赛的善良
题目描述
天梯赛是个善良的比赛。善良的命题组希望将题目难度控制在一个范围内,使得每个参赛的学生都有能做出来的题目,并且最厉害的学生也要非常努力才有可能得到高分。
于是命题组首先将编程能力划分成了 106 个等级(太疯狂了,这是假的),然后调查了每个参赛学生的编程能力。现在请你写个程序找出所有参赛学生的最小和最大能力值,给命题组作为出题的参考。
输入格式
输入在第一行中给出一个正整数 N(≤2×104),即参赛学生的总数。随后一行给出 N 个不超过 106 的正整数,是参赛学生的能力值。
输出格式
第一行输出所有参赛学生的最小能力值,以及具有这个能力值的学生人数。第二行输出所有参赛学生的最大能力值,以及具有这个能力值的学生人数。同行数字间以 1 个空格分隔,行首尾不得有多余空格。
测试数据
输入样例:
10
86 75 233 888 666 75 886 888 75 666
输出样例:
75 3
888 2
解题思路
最初版本:
n = int(input())
stu = []
stu_map = map(int,input().split(" "))
for i in stu_map:
stu.append(i)
v_max = max(stu)
v_min = min(stu)
v_max_size = 0
v_min_size = 0
for i in stu:
if i==v_max:
v_max_size+=1
elif i==v_min:
v_min_size+=1
print(v_min,v_min_size)
print(v_max,v_max_size)
优化版本:
- 直接将map转化为list,不去循环里面添加
- 使用max函数结合数组的统计函数
n = int(input())
stu = list(map(int,input().split()))
if n == 0 or not stu:
print("0 0")
print("0 0")
else:
v_max = max(stu)
v_min = min(stu)
v_max_size = stu.count(v_max)
v_min_size = stu.count(v_min)
# 输出结果
print(f"{v_min} {v_min_size}")
print(f"{v_max} {v_max_size}")
7-12 厘米换算英尺英寸
题目描述
如果已知英制长度的英尺foot和英寸inch的值,那么对应的米是(foot+inch/12)×0.3048。现在,如果用户输入的是厘米数,那么对应英制长度的英尺和英寸是多少呢?别忘了1英尺等于12英寸。
输入格式
输入在一行中给出1个正整数,单位是厘米。
输出格式
在一行中输出这个厘米数对应英制长度的英尺和英寸的整数值,中间用空格分开。英寸的值应小于12。
测试数据
输入样例:
170
输出样例:
5 6
解题思路
题目想复杂了,实际上很简单,就是一个公式转换而已,简单的理解为:1.2m = 1m + 0.2m 这样的理解
cm = int(input())
m = cm / 100
total_feet = m / 0.3048
foot = int(total_feet)
inch = int((total_feet-foot)*12)
print(f"{foot} {inch}")
7-15 通讯录排序
题目描述
输入n个朋友的信息,包括姓名、生日、电话号码,本题要求编写程序,按照年龄从大到小的顺序依次输出通讯录。题目保证所有人的生日均不相同。
输入格式
输入第一行给出正整数n(<10)。随后n行,每行按照“姓名 生日 电话号码”的格式给出一位朋友的信息,其中“姓名”是长度不超过10的英文字母组成的字符串,“生日”是yyyymmdd格式的日期,“电话号码”是不超过17位的数字及+、-组成的字符串。
输出格式
按照年龄从大到小输出朋友的信息,格式同输出。
测试数据
输入样例:
3
zhang 19850403 13912345678
wang 19821020 +86-0571-88018448
qian 19840619 13609876543
输出样例:
wang 19821020 +86-0571-88018448
qian 19840619 13609876543
zhang 19850403 13912345678
解题思路
第一版:
比赛的时候忘记了排序的时候怎么用lambda表达式,于是乎用了一个很麻烦的方法
n = int(input())
arr = []
for ii in range(n):
name,birth,phone = input().split(" ")
arr.append({"name":name,"age":birth,"phone":phone})
new_arr = []
for i in range(len(arr)):
new_arr.append(arr[i]["age"])
new_arr.sort()
arr_index = []
for j in new_arr:
for k in range(len(arr)):
if j==arr[k]["age"]:
arr_index.append(k)
for l in arr_index:
print(arr[l]["name"],arr[l]["age"],arr[l]["phone"])
优化版本:
n = int(input())
arr = []
# 获取输入
for _ in range(n):
name,birth,phone = input().split()
arr.append({"name":name,"birth":birth,"phone":phone})
# 排序
arr.sort(key=lambda x:x["birth"],reverse=False)
for i in arr:
print(i["name"], i["birth"], i["phone"])
7-18 稳赢
题目描述
大家应该都会玩“锤子剪刀布”的游戏:两人同时给出手势,胜负规则如图所示:
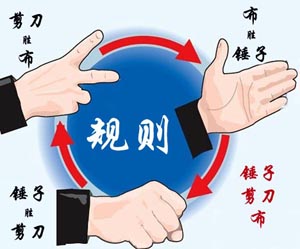
现要求你编写一个稳赢不输的程序,根据对方的出招,给出对应的赢招。但是!为了不让对方输得太惨,你需要每隔K次就让一个平局。
输入格式
输入首先在第一行给出正整数K(≤10),即平局间隔的次数。随后每行给出对方的一次出招:ChuiZi代表“锤子”、JianDao代表“剪刀”、Bu代表“布”。End代表输入结束,这一行不要作为出招处理。
输出格式
对每一个输入的出招,按要求输出稳赢或平局的招式。每招占一行。
测试数据
输入样例
ChuiZi
JianDao
Bu
JianDao
Bu
ChuiZi
ChuiZi
End
输出样例
Bu
ChuiZi
Bu
ChuiZi
JianDao
ChuiZi
Bu
解题思路
k = int(input())
win_count = 0
while True:
opponent_move = input()
if opponent_move == "End":
break
if win_count == k:
print(opponent_move)
win_count = 0
else:
# 稳赢:根据对方出招输出对应的赢招
if opponent_move == "ChuiZi":
print("Bu")
elif opponent_move == "JianDao":
print("ChuiZi")
elif opponent_move == "Bu":
print("JianDao")
# 计数器加 1
win_count += 1
7-20 判断素数
题目描述
本题的目标很简单,就是判断一个给定的正整数是否素数。
输入格式
输入在第一行给出一个正整数N(≤ 10),随后N行,每行给出一个小于231的需要判断的正整数。
输出格式
对每个需要判断的正整数,如果它是素数,则在一行中输出Yes,否则输出No。
测试数据
输入样例:
2
11
111
输出样例:
Yes
No
解题思路
最简单的方法,但是运行时间会超时
def is_prime(value):
if value <= 1:
return False
for i in range(2, value):
if value % i == 0:
return False
return True
n = int(input())
for _ in range(n):
num = int(input())
print("Yes" if is_prime(num) else "No")
优化版本22:
import math
# 实现逻辑,小于等于1的都不是,2是,大于2的偶数都不是,遍历的范围到sqrt(n)即可,步长为2,跳过偶数。
def is_prime(value):
if value <= 1:
return False
if value == 2:
return True
if value % 2 == 0:
return False
for i in range(3, int(math.sqrt(value)+1),2):
if value % i == 0:
return False
return True
n = int(input())
for _ in range(n):
num = int(input())
print("Yes" if is_prime(num) else "No")
L1-005 考试座位号
题目描述
每个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常情况下,考生在入场时先得到试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试时考生需要换到考试座位就座。但有些考生迟到了,试机已经结束,他们只能拿着领到的试机座位号码求助于你,从后台查出他们的考试座位号码。
输入格式:
输入第一行给出一个正整数 N(≤1000),随后 N 行,每行给出一个考生的信息:准考证号 试机座位号 考试座位号。其中准考证号由 16 位数字组成,座位从 1 到 N 编号。输入保证每个人的准考证号都不同,并且任何时候都不会把两个人分配到同一个座位上。
考生信息之后,给出一个正整数 M(≤N),随后一行中给出 M 个待查询的试机座位号码,以空格分隔。
输出格式:
对应每个需要查询的试机座位号码,在一行中输出对应考生的准考证号和考试座位号码,中间用 1 个空格分隔。
测试数据
输入样例:
4
3310120150912233 2 4
3310120150912119 4 1
3310120150912126 1 3
3310120150912002 3 2
2
3 4
输出样例:
3310120150912002 2
3310120150912119 1
解题思路
n = int(input())
stu = []
for _ in range(n):
admission_num,test_num,exam_num = map(int,input().split())
stu.append({"admission_num":admission_num,"test_num":test_num,"exam_num":exam_num})
m = int(input())
search_num = list(map(int,input().split()))
for search in search_num:
for p in stu:
if p["test_num"] == search:
print(f"{p['admission_num']} {p['exam_num']}")
这里需要的注意点是:print(f"{p['admission_num']} {p['exam_num']}")里面的key不能用双引号,虽然在本地编译器可以正常执行,但是在线平台运行的话,就会报错。
下面是使用字典代替数组的优化版本:
n = int(input())
lookup = {}
for _ in range(n):
admission_num,test_num,exam_num = map(int,input().split())
# 将准考证号和考试号打包成元组,放到字典里面
lookup[int(test_num)] = (admission_num,exam_num)
m = int(input())
search_num = list(map(int,input().split()))
for sn in search_num:
adm,exam = lookup[sn]
print(f'{adm} {exam}')
L1-027 出租
题目描述
下面是新浪微博上曾经很火的一张图:

一时间网上一片求救声,急问这个怎么破。其实这段代码很简单,index数组就是arr数组的下标,index[0]=2 对应 arr[2]=1,index[1]=0 对应 arr[0]=8,index[2]=3 对应 arr[3]=0,以此类推…… 很容易得到电话号码是18013820100。
本题要求你编写一个程序,为任何一个电话号码生成这段代码 —— 事实上,只要生成最前面两行就可以了,后面内容是不变的。
输入格式:
输入在一行中给出一个由11位数字组成的手机号码。
输出格式:
为输入的号码生成代码的前两行,其中arr中的数字必须按递减顺序给出。
测试数据
输入样例:
18013820100
输出样例:
int[] arr = new int[]{8,3,2,1,0};
int[] index = new int[]{3,0,4,3,1,0,2,4,3,4,4};
解题思路
numbers = input()
arr = list(numbers)
numbers_set = sorted(list(set(numbers)),reverse=True)
index = []
for i in arr:
index.append(numbers_set.index(i))
arr_str = ",".join(str(i) for i in numbers_set)
index_str = ",".join(str(i) for i in index)
print("int[] arr = new int[]{"+arr_str+"};")
print("int[] index = new int[]{"+index_str+"};")
L1-030 一帮一
题目描述
“一帮一学习小组”是中小学中常见的学习组织方式,老师把学习成绩靠前的学生跟学习成绩靠后的学生排在一组。本题就请你编写程序帮助老师自动完成这个分配工作,即在得到全班学生的排名后,在当前尚未分组的学生中,将名次最靠前的学生与名次最靠后的异性学生分为一组。
输入格式
输入第一行给出正偶数N(≤50),即全班学生的人数。此后N行,按照名次从高到低的顺序给出每个学生的性别(0代表女生,1代表男生)和姓名(不超过8个英文字母的非空字符串),其间以1个空格分隔。这里保证本班男女比例是1:1,并且没有并列名次。
输出格式
每行输出一组两个学生的姓名,其间以1个空格分隔。名次高的学生在前,名次低的学生在后。小组的输出顺序按照前面学生的名次从高到低排列。
测试数据
输入样例
8
0 Amy
1 Tom
1 Bill
0 Cindy
0 Maya
1 John
1 Jack
0 Linda
输出样例
Amy Jack
Tom Linda
Bill Maya
Cindy John
解题思路
贪心算法:局部最优,然后组合称为最后的结果
n = int(input())
arr = []
for _ in range(n):
sex,name = input().split()
arr.append({"sex":sex,"name":name})
for item in arr:
item["used"] = False # 直接修改原字典
for i in range(len(arr)):
arr[i]["used"] = True
for j in range(len(arr)-1, -1, -1): # 逆序遍历数组
if arr[j]["used"]:
continue
else:
if arr[i]["sex"] != arr[j]["sex"]:
print(arr[i]['name'],arr[j]['name'])
arr[j]["used"] = True
break
L1-101 别再来这么多猫娘了!
题目描述
以 GPT 技术为核心的人工智能系统出现后迅速引领了行业的变革,不仅用于大量的语言工作(如邮件编写或文章生成等工作),还被应用在一些较特殊的领域——例如去年就有同学尝试使用 ChatGPT 作弊并被当场逮捕(全校被取消成绩)。相信聪明的你一定不会犯一样的错误!
言归正传,对于 GPT 类的 AI,一个使用方式受到不少年轻用户的欢迎——将 AI 变成猫娘:
部分公司使用 AI 进行网络营销,网友同样乐于使用“变猫娘”的方式进行反击。注意:图中内容与题目无关,如无法看到图片不影响解题。
当然,由于训练数据里并不区分道德或伦理倾向,因此如果不加审查,AI 会生成大量的、不一定符合社会公序良俗的内容。尽管关于这个问题仍有争论,但至少在比赛中,我们还是期望 AI 能用于对人类更有帮助的方向上,少来一点猫娘。
因此你的工作是实现一个审查内容的代码,用于对 AI 生成的内容的初步审定。更具体地说,你会得到一段由大小写字母、数字、空格及 ASCII 码范围内的标点符号的文字,以及若干个违禁词以及警告阈值,你需要首先检查内容里有多少违禁词,如果少于阈值个,则简单地将违禁词替换为<censored>;如果大于等于阈值个,则直接输出一段警告并输出有几个违禁词。
输入格式:
输入第一行是一个正整数 N (1≤N≤100),表示违禁词的数量。接下来的 N 行,每行一个长度不超过 10 的、只包含大小写字母、数字及 ASCII 码范围内的标点符号的单词,表示应当屏蔽的违禁词。
然后的一行是一个非负整数 k (0≤k≤100),表示违禁词的阈值。
最后是一行不超过 5000 个字符的字符串,表示需要检查的文字。
从左到右处理文本,违禁词则按照输入顺序依次处理;对于有重叠的情况,无论计数还是替换,查找完成后从违禁词末尾继续处理。
输出格式:
如果违禁词数量小于阈值,则输出替换后的文本;否则先输出一行一个数字,表示违禁词的数量,然后输出He Xie Ni Quan Jia!。
测试数据
输入样例1:
5
MaoNiang
SeQing
BaoLi
WeiGui
BuHeShi
4
BianCheng MaoNiang ba! WeiGui De Hua Ye Keyi Shuo! BuYao BaoLi NeiRong.
输出样例1:
BianCheng <censored> ba! <censored> De Hua Ye Keyi Shuo! BuYao <censored> NeiRong.
输入样例2:
5
MaoNiang
SeQing
BaoLi
WeiGui
BuHeShi
3
BianCheng MaoNiang ba! WeiGui De Hua Ye Keyi Shuo! BuYao BaoLi NeiRong.
输出样例2:
3
He Xie Ni Quan Jia!
输入样例3:
2
AA
BB
3
AAABBB
输出样例3:
<censored>A<censored>B
输入样例4:
2
AB
BB
3
AAABBB
输出样例4:
AA<censored><censored>
输入样例5:
2
BB
AB
3
AAABBB
输出样例5:
AAA<censored>B
解题思路
14分的答案,没有全部通过,不知道为什么
思路,就是从text的每一个字符串开始,使用startswith函数去看看有没有违禁词
# 输入违禁词数量
n = int(input())
# 读取违禁词列表
forbidden_words = [input() for _ in range(n)]
# 输入阈值
threshold = int(input())
# 输入需要检查的文本
text = input()
# 初始化变量
count = 0
result = [] #用于存储替换后的文本
i = 0 #当前扫描的位置
while i < len(text):
found = False #标记是否找到违禁词
for word in forbidden_words:
if text.startswith(word,i):
count += 1
i += len(word) # 跳过整个违禁词长度
result.append("<censored>")
found = True
break
if not found:
result.append(text[i])
i += 1 #移动到下一个字符
if count < threshold:
print("".join(result)) #输出替换后的文本,list转字符串
else:
print(count) #输出实际的违禁词数量
print("He Xie Ni Quan Jia!")
L1-103 整数的持续性
题目描述
从任一给定的正整数 n 出发,将其每一位数字相乘,记得到的乘积为 n₁。以此类推,令 nᵢ₊₁ 为 nᵢ 的各位数字的乘积,直到最后得到一个个位数 nₘ,则 m 就称为 n 的持续性。
例如,679 的持续性是 5,计算过程如下:
679 → 6×7×9 = 378
378 → 3×7×8 = 168
168 → 1×6×8 = 48
48 → 4×8 = 32
32 → 3×2 = 6
共进行了 5 步,最终得到个位数 6。
本题要求你编写程序,找出任一给定区间内持续性最长的整数。
输入格式
输入在一行中给出两个正整数 a 和 b(满足 1 ≤ a ≤ b ≤ 10⁹ 且 b - a < 10³),为给定区间的两个端点。
输出格式
- 第一行输出区间
[a, b]内整数的最大持续性。 - 第二行输出所有具有该持续性的整数,按递增顺序排列,数字之间用 1 个空格分隔,行首尾不得有多余空格。
测试数据
输入样例
500 700
输出样例
5
679 688 697
解题思路
本题关键是实现一个计算持续性的函数。可以用递归方式求一个数的持续性,判断是否为个位数,否则把它拆成每位相乘后继续计算。
- 使用递归函数计算持续性。
- 遍历区间
[a, b],记录每个数字的持续性。 - 找出最大持续性,并输出对应的所有数字。
参考代码
# 编写递归程序的要点
# 1、结束条件必须明确(这里是 n < 10)。
# 2、每次调用要让问题变小(这里是让 n 变成各位数字的乘积)。
# 3、记得 return 结果,否则你无法得到递归的最终结果。
def fn(n,count=0):
# print("当前数字:", n)
if n<10:
# print("结束",n)
return count
temp = 1
for digit in str(n):
temp *= int(digit)
return fn(temp,count + 1)
start,end = map(int,input().split())
arr = {}
for i in range(start,end+1):
steps = fn(i)
key = str(steps)
# print("总共拆解次数:", steps)
# 使用 not in结合字典进行操作
# 字典的keys()方法,会将所有的键进行返回
if key not in arr:
arr[key] = f"{i}"
else:
arr[key]+=f",{i}"
max_key = max(arr.keys(),key=lambda x:int(x))
print(max_key)
print(arr[max_key].replace(","," "))
L2-049 鱼与熊掌
题目描述
《孟子 · 告子上》有名言:“鱼,我所欲也,熊掌,亦我所欲也;二者不可得兼,舍鱼而取熊掌者也。”但这世界上还是有一些人可以做到鱼与熊掌兼得的。
给定 n 个人对 m 种物品的拥有关系。对其中任意一对物品种类(例如“鱼与熊掌”),请你统计有多少人能够兼得?
输入格式
输入首先在第一行给出 2 个正整数,分别是:
n(≤ 10⁵):为总人数(所有人从 1 到 n 编号);m(2 ≤ m ≤ 10⁵):为物品种类的总数(所有物品种类从 1 到 m 编号)。
随后 n 行,第 i 行(1 ≤ i ≤ n)给出编号为 i 的人所拥有的物品种类清单,格式为:
K M[1] M[2] ... M[K]
其中:
K(≤ 10³):表示该人拥有的物品种类数量;- 后面的
M[*]是物品种类的编号。
题目保证每个人的物品种类清单中都没有重复的种类。
最后是查询信息:
- 首先在一行中给出查询总量
Q(≤ 100); - 随后
Q行,每行给出一对物品种类编号,其间以空格分隔。
题目保证所有物品种类编号都是合法存在的。
输出格式
对每一次查询,在一行中输出能够兼得这两种物品的人数。
测试数据
输入样例
4 8
3 4 1 8
4 7 1 8 4
5 6 5 1 2 3
4 3 2 4 8
3
2 3
7 6
8 4
输出样例
2
0
3
解题思路
- 建立一个哈希表,记录每个物品种类被哪些人拥有;
- 对于每次查询,将两个物品种类对应的人员列表转换为集合,求交集大小即可;
- 注意去重与加速,可使用
unordered_map与unordered_set。
参考代码
#include <bits/stdc++.h>
#define ios ios::sync_with_stdio(false),cin.tie(0),cout.tie(0) //关闭流,加快输入输出的速度
using namespace std;
int main(){
ios;
int n,m;
cin >> n >>m;
unordered_map<int,vector<int>> item_persons;
// 输入,注意从i需要1开始
for(int i=1;i<=n;i++){
int k;
cin >> k;
for(int j=0;j<k;j++){
int item;
cin >> item;
item_persons[item].push_back(i); //给物品加上拥有人的id
}
}
// 查询Q
int Q;
cin >> Q;
while(Q--){
int A,B;
cin >> A >> B;
const auto& lista = item_persons[A];
const auto& listb = item_persons[B];
unordered_set<int> set_a(lista.begin(),lista.end());
unordered_set<int> set_b(listb.begin(),listb.end());
int count = 0;
for(int person : set_a){
if(set_b.find(person)!=set_b.end()){
count++;
}
}
// 输出结果
cout << count << "\n";
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号