

04 数据分析与挖掘 xgboost&git
数据分析与挖掘 xgboost&git
git地址
git
第一次将文件上传到GitHub
-
进入管理的文件夹
-
打开git bash
-
初始化命令
git init -
查看目录下文件状态
git status # 新增文件或者修改过的文件是红色的 -
管理指定文件(红变绿)
git add 文件名 git add . # 所有文件 -
个人信息配置:用户名,邮箱(只要一次)
git config --global user.email "you@example.com" git config --global user.name "your name" -
生成版本
git commit -m '描述信息' -
查看版本记录
git log -
连接GitHub
# 现在需要token和ssh进行验证 # 给远程仓库起别名 git remote add origin 远程仓库地址 # 向远程仓库推送代码(默认是main分支) git push -u origin 分支
第一个版本我已经上传上去了,你们只要将我的这个版本给克隆下来,得到一个文件夹,在这个文件夹里面创建新的文件夹,完成自己任务,避免发生冲突
在自己电脑上下载代码
# 克隆远程仓库代码
git clone 远程仓库地址(这个时候不用进行初始化)
# 使用镜像
git clone https://github.com.cnpmjs.org/name/project.git
# 在将自己完成的任务放到文件夹中
# 完成任务后
# 我的代码已经有了两个分支,克隆下来默认在主分支,我们需要切换分支,进入第二分支,我的第二分支是dev分支
git checkout dev
git status
git add .
git commit -m "描述信息"
# 完成任务后,将代码推送到远端
# 注意只需要推送dev分支,看清楚自己是在哪个分支
git push origin dev # 协同合作后才可以上传到别人的GitHub
预测用户流失设计
应用场景
"""
应用场景: 业务部门希望数据部门能对流失用户做数据分析
例如: 到底流失客户的哪些特征最显著,当用户在哪些特征的什么条件下比较容易发生流失行为,并且交给业务部门
针对这些用户进行业务优化及其挽回动作。
基于上述要求:数据分析工作特点:
这是一个特征提取的分析工作,目标交付物是特征的重要性和特征规则
可通过决策树分类算法,决策树是最好的解释规则的算法
业务部门需要了解规则的关系,提供规则图
数据大概率会出现样布不均衡,原因是流失的用户一定是少量的
"""
"""
Pandas python 做数据读取和基本处理
sklearn的trian_test_split 实现切分数据集为训练集和测试集
XGBoost 分类算法用于模型训练和规则处理
sklearn.metrics中 多个评估指标苹果XGBoost模型的效果
imblearn.over_sampling 中的SMOTE库做样本均衡处理
matplotlib 图形的输出,配合使用
prettytable 表格格式化输出展示
GraphViz 矢量图输出的第三方程序,为python提供接口,需要下载并且配置环境变量
pydot XGBoost展示树图形时会用到
"""
安装必要的库
xgboost
'''
集成学习算法
bagging(随机森林)
boosting(gbdt(xgboost))
gbdt梯度提升算法,xgboost属于gdbt算法
xgboost:加法模型和向前优化算法,(是一个回归树,分类树集成学习算法) (多个弱学习器集成在一起)
'''
# 到网址里下载对应的python版本的安装包(我的是3.7版本,安装包已经放入文件夹中)
# 将下载好的安装包放入对应python解释器Scripts中,比如:G:\python_learn\venv\Scripts
# cmd 进入Scripts中: pip install xgboost-1.2.1-cp37-cp37m-win_amd64.whl(安装包名)
# 安装成功
GraphViz
-
安装包已经放入文件案件
-
需要配置环境变量才可以使用
-
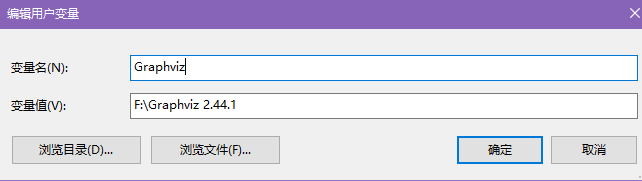
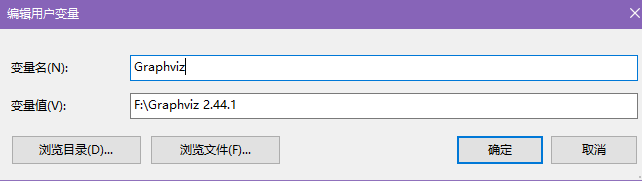
用户环境变量如下
![用户环境变量]()
-
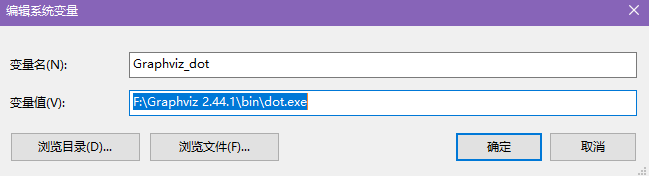
系统环境变量如下
![系统环境变量]()
-
系统环境变量中的path下添加Graphviz的bin目录
![path]()

prettytable
pip install prettytable
pydot
pip install pydot
pyecharts
pip install 库名
注意的问题
预处理
- xgboost算法具有容忍性,不处理空值,也会有效的应对
- xgboost本身就能有效的选择特征并处理,我们无须降维
- 虽然说xgboost可以不处理空值,但是我们研究的是用户流失,流失客户一定是少量的,会出现数据不均匀的情况,所以我们需要对数据进行均衡处理。均衡处理强制要求不可以有空值,所以我们需要对空值进行处理
- 均值处理后返回的是一个numpy矩阵,已经丢失特征,我们需要重新为数据填上标签
训练模型
- random_state这个参数很重要,对于随机森林这个模型,它本质上是随机的,设置不同的随机状态(或者不设置random_state参数)可以彻底改变构建的模型
混淆矩阵
- 混淆矩阵输出是一个矩阵,没有任何标签。我们需要对它进行表格格式化输出展示
- 混淆矩阵绘图
可视化
- xgboost训练出来的模型,自带了一些可视化方法。xgb.plot_importance输出了特征的重要性,xgb.to_graphviz输出了一个树形规则图,这两个方法直接通过给训练出来的模型和一些参数就可以直接绘图,都没有给分析出来的数据。
- pyechart绘图需要数据,通过观察源码,xgboost模型可以通过以下方法获取分析后得到得数据
# importance_type = weight是特征在树中出现的次数(分裂的次数),gain是使用特征分裂的平均值增益,cover是作为分裂节点的覆盖的样本比例
importance =model_xgb.get_booster().get_score(
importance_type='weight', fmap='')
- 得到分析后数据之后,将数据处理成某种格式,就可以绘制pyecharts图
对树形规则图解释
- 分析树形规则图可以了解到:我们会发现从上层到下层,随着条件的增加,流失用户的概率就越大(精准确定用户),规则越多,覆盖得总样本量和流失的用户数量就越少
- leaf(类似与一个弱分类器,或者说就是一个预测值,通过leaf进行转化可以得到一个预测值)
github显示图片问题
github文件夹中显示图片
- 打开文件hosts:(C:\Windows\System32\drivers\etc)下的hosts
- 用记事本编辑,加入以下代码
# GitHub Start
#192.30.253.112 github.com
#192.30.253.119 gist.github.com
151.101.184.133 assets-cdn.github.com
151.101.184.133 raw.githubusercontent.com
151.101.184.133 gist.githubusercontent.com
151.101.184.133 cloud.githubusercontent.com
151.101.184.133 camo.githubusercontent.com
151.101.184.133 avatars0.githubusercontent.com
151.101.184.133 avatars1.githubusercontent.com
151.101.184.133 avatars2.githubusercontent.com
151.101.184.133 avatars3.githubusercontent.com
151.101.184.133 avatars4.githubusercontent.com
151.101.184.133 avatars5.githubusercontent.com
151.101.184.133 avatars6.githubusercontent.com
151.101.184.133 avatars7.githubusercontent.com
151.101.184.133 avatars8.githubusercontent.com
# GitHub End
- 刷新github即可
github readme文件中显示图片(markdown编写)
- 要在项目文件夹中建立一个专门存储图片的文件夹。
- 在GitHub中打开图片,复制网址
- 在markdown中编写插入图片的时候用这个网址。GitHub readme文件就可以显示图片
- 但是本地的readme文件就显示不了图片,因为找不到路径
- 需要将网址中的blob改成raw即可,两者都可以显示图片了
![]()
![]()

再坚持一下下,会越来越优秀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号