《OD面试》Java面试题整理
1.1.1 List
以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组。因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。
按数组下标访问元素-get(i)、set(i,e) 的性能很高,这是数组的基本优势。
如果按下标插入元素、删除元素-add(i,e)、 remove(i)、remove(e),则要用System.arraycopy()来复制移动部分受影响的元素,性能就变差了。
越是前面的元素,修改时要移动的元素越多。直接在数组末尾加入元素-常用的add(e),删除最后一个元素则无影响。
1.1.1.2 LinkedList
1)概述
以双向链表实现。链表无容量限制,但双向链表本身使用了更多空间,每插入一个元素都要构造一个额外的Node对象,也需要额外的链表指针操作。
按下标访问元素-get(i)、set(i,e) 要悲剧的部分遍历链表将指针移动到位 (如果i>数组大小的一半,会从末尾移起)。
插入、删除元素时修改前后节点的指针即可,不再需要复制移动。但还是要部分遍历链表的指针才能移动到下标所指的位置。
只有在链表两头的操作-add()、addFirst()、removeLast()或用iterator()上的remove()倒能省掉指针的移动。
Apache Commons 有个TreeNodeList,里面是棵二叉树,可以快速移动指针到位。
1.1.1.3 CopyOnWriteArrayList
1)CopyOnWriteArrayList概述
并发优化的ArrayList。基于不可变对象策略,在修改时先复制出一个数组快照来修改,改好了,再让内部指针指向新数组。
因为对快照的修改对读操作来说不可见,所以读读之间不互斥,读写之间也不互斥,只有写写之间要加锁互斥。但复制快照的成本昂贵,典型的适合读多写少的场景。
虽然增加了addIfAbsent(e)方法,会遍历数组来检查元素是否已存在,性能可想像的不会太好。
2)CopyOnWriteArrayList可以用于什么应用场景?
答:CopyOnWriteArrayList(免锁容器)的好处之一是当多个迭代器同时遍历和修改这个列表时,不会抛出ConcurrentModificationException。在CopyOnWriteArrayList中,写入将导致创建整个底层数组的副本,而源数组将保留在原地,使得复制的数组在被修改时,读取操作可以安全地执行。
1.1.1.4 List的总结
无论哪种实现,按值返回下标contains(e), indexOf(e), remove(e) 都需遍历所有元素进行比较,性能可想像的不会太好。
没有按元素值排序的SortedList。除了CopyOnWriteArrayList,再没有其他线程安全又并发优化的实现如ConcurrentLinkedList。
凑合着用Set与Queue中的等价类时,会缺少一些List特有的方法如get(i)。如果更新频率较高,或数组较大时,还是得用Collections.synchronizedList(list),对所有操作用同一把锁来保证线程安全。
1.1.2 Map
Java HashMap中在resize()时候的rehash,即再哈希法的理解
Java的HashMap工作原理
哈希表是由数组+链表组成的,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组”。
HashMap有一个叫做Entry的内部类,它用来存储key-value对。
上面的Entry对象是存储在一个叫做table的Entry数组中。table的索引在逻辑上叫做“桶”(bucket),它存储了链表的第一个元素。
key的hashcode()方法用来找到Entry对象所在的桶。如果两个key有相同的hash值,他们会被放在table数组的同一个桶里面。
key的equals()方法用来确保key的唯一性。
value对象的equals()和hashcode()方法根本一点用也没有。
3)两个重要的参数
resize的实现)
当put时,如果发现目前的bucket占用程度已经超过了Load Factor所希望的比例,那么就会发生resize。在resize的过程,简单的说就是把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中。
当超过限制的时候会resize,然而又因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
6)你知道hash的实现吗?为什么要这样实现?
在Java 1.8的实现中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在bucket的n比较小的时候,也能保证考虑到高低bit都参与到hash的计算中,同时不会有太大的开销。
7)如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
如果超过了负载因子(默认0.75),则会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法。
8)关于HashMap的总结
以Entry[]数组实现的哈希桶数组,用Key的哈希值取模桶数组的大小可得到数组下标。
插入元素时,如果两条Key落在同一个桶(比如哈希值1和17取模16后都属于第一个哈希桶),Entry用一个next属性实现多个Entry以单向链表存放,后入桶的Entry将next指向桶当前的Entry。
查找哈希值为17的key时,先定位到第一个哈希桶,然后以链表遍历桶里所有元素,逐个比较其key值。
当Entry数量达到桶数量的75%时(很多文章说使用的桶数量达到了75%,但看代码不是),会成倍扩容桶数组,并重新分配所有原来的Entry,所以这里也最好有个预估值。
取模用位运算(hash & (arrayLength-1))会比较快,所以数组的大小永远是2的N次方, 你随便给一个初始值比如17会转为32。默认第一次放入元素时的初始值是16。
iterator()时顺着哈希桶数组来遍历,看起来是个乱序。
在JDK8里,新增默认为8的閥值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。
9)怎样让HashMap同步
Map m = Collections.synchronizeMap(hashMap);
10)HashMap怎么实现,自己实现HashMap会注意哪些问题,怎么实现一个hashMap一分钟以后key过期
1.1.2.2 Hashtable
1)HashMap和HashTable 区别,HashTable线程安全吗?
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差别。
1.1.2.3 LinkedHashMap
扩展HashMap,每个Entry增加双向链表,号称是最占内存的数据结构。
支持iterator()时按Entry的插入顺序来排序(如果设置accessOrder属性为true,则所有读写访问都排序)。
插入时,Entry把自己加到Header Entry的前面去。如果所有读写访问都要排序,还要把前后Entry的before/after拼接起来以在链表中删除掉自己,所以此时读操作也是线程不安全的了。
1.1.2.4 TreeMap
以红黑树实现,红黑树又叫自平衡二叉树:
对于任一节点而言,其到叶节点的每一条路径都包含相同数目的黑结点。
上面的规定,使得树的层数不会差的太远,使得所有操作的复杂度不超过 O(lgn),但也使得插入,修改时要复杂的左旋右旋来保持树的平衡。
支持iterator()时按Key值排序,可按实现了Comparable接口的Key的升序排序,或由传入的Comparator控制。可想象的,在树上插入/删除元素的代价一定比HashMap的大。
支持SortedMap接口,如firstKey(),lastKey()取得最大最小的key,或sub(fromKey, toKey), tailMap(fromKey)剪取Map的某一段。
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
1.1.2.5 EnumMap
EnumMap的原理是,在构造函数里要传入枚举类,那它就构建一个与枚举的所有值等大的数组,按Enum. ordinal()下标来访问数组。性能与内存占用俱佳。
美中不足的是,因为要实现Map接口,而 V get(Object key)中key是Object而不是泛型K,所以安全起见,EnumMap每次访问都要先对Key进行类型判断,在JMC里录得不低的采样命中频率。
1.1.2.6 ConcurrentHashMap
参考:
1)聊聊并发(四)——深入分析ConcurrentHashMap
2)探索 ConcurrentHashMap 高并发性的实现机制
4)并发优化的HashMap。
在JDK5里的经典设计,默认16把写锁(可以设置更多),有效分散了阻塞的概率。数据结构为Segment[],每个Segment一把锁。Segment里面才是哈希桶数组。Key先算出它在哪个Segment里,再去算它在哪个哈希桶里。
也没有读锁,因为put/remove动作是个原子动作(比如put的整个过程是一个对数组元素/Entry 指针的赋值操作),读操作不会看到一个更新动作的中间状态。
但在JDK8里,Segment[]的设计被抛弃了,改为精心设计的,只在需要锁的时候加锁。
支持ConcurrentMap接口,如putIfAbsent(key,value)与相反的replace(key,value)与以及实现CAS的replace(key, oldValue, newValue)。
5)分段加锁
从ConcurrentHashMap代码中可以看出,它引入了一个“分段锁”的概念,具体可以理解为把一个大的Map拆分成N个小的HashTable,根据key.hashCode()来决定把key放到哪个HashTable中。
在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中。
6)synchronizedMap和ConcurrentHashMap有什么区别?
答:java5中新增了ConcurrentMap接口和它的一个实现类ConcurrentHashMap。ConcurrentHashMap提供了和Hashtable以及SynchronizedMap中所不同的锁机制。比起synchronizedMap来,它提供了好得多的并发性。多个读操作几乎总可以并发地执行,同时进行的读和写操作通常也能并发地执行,而同时进行的写操作仍然可以不时地并发进行(相关的类也提供了类似的多个读线程的并发性,但是,只允许有一个活动的写线程)。Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。ConcurrentHashMap默认将hash表分为16个桶,诸如get,put,remove等常用操作只锁当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。前面说到的16个线程指的是写线程,而读操作大部分时候都不需要用到锁。只有在size等操作时才需要锁住整个hash表。
在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据 ,iterator完成后再将头指针替换为新的数据 ,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。
1.1.2.7 ConcurrentSkipListMap
JDK6新增的并发优化的SortedMap,以SkipList结构实现。Concurrent包选用它是因为它支持基于CAS的无锁算法,而红黑树则没有好的无锁算法。
原理上,可以想象为多个链表组成的N层楼,其中的元素从稀疏到密集,每个元素有往右与往下的指针。从第一层楼开始遍历,如果右端的值比期望的大,那就往下走一层,继续往前走。

典型的空间换时间。每次插入,都要决定在哪几层插入,同时,要决定要不要多盖一层楼。
它的size()同样不能随便调,会遍历来统计。
1.1.3 Set
所有Set几乎都是内部用一个Map来实现, 因为Map里的KeySet就是一个Set,而value是假值,全部使用同一个Object即可。
Set的特征也继承了那些内部的Map实现的特征。
HashSet:内部是HashMap。
LinkedHashSet:内部是LinkedHashMap。
TreeSet:内部是TreeMap的SortedSet。
ConcurrentSkipListSet:内部是ConcurrentSkipListMap的并发优化的SortedSet。
CopyOnWriteArraySet:内部是CopyOnWriteArrayList的并发优化的Set,利用其addIfAbsent()方法实现元素去重,如前所述该方法的性能很一般。
好像少了个ConcurrentHashSet,本来也该有一个内部用ConcurrentHashMap的简单实现,但JDK偏偏没提供。Jetty就自己简单封了一个,Guava则直接用java.util.Collections.newSetFromMap(new ConcurrentHashMap()) 实现。
1.1.4 Queue
Queue是在两端出入的List,所以也可以用数组或链表来实现。
普通队列
1.1.4.1 LinkedList
是的,以双向链表实现的LinkedList既是List,也是Queue。
1.1.4.2 ArrayDeque
以循环数组实现的双向Queue。大小是2的倍数,默认是16。
为了支持FIFO,即从数组尾压入元素(快),从数组头取出元素(超慢),就不能再使用普通ArrayList的实现了,改为使用循环数组。
有队头队尾两个下标:弹出元素时,队头下标递增;加入元素时,队尾下标递增。如果加入元素时已到数组空间的末尾,则将元素赋值到数组[0],同时队尾下标指向0,再插入下一个元素则赋值到数组[1],队尾下标指向1。如果队尾的下标追上队头,说明数组所有空间已用完,进行双倍的数组扩容。
1.1.4.3 PriorityQueue
用平衡二叉最小堆实现的优先级队列,不再是FIFO,而是按元素实现的Comparable接口或传入Comparator的比较结果来出队,数值越小,优先级越高,越先出队。但是注意其iterator()的返回不会排序。
平衡最小二叉堆,用一个简单的数组即可表达,可以快速寻址,没有指针什么的。最小的在queue[0] ,比如queue[4]的两个孩子,会在queue[2*4+1] 和 queue[2*(4+1)],即queue[9]和queue[10]。
入队时,插入queue[size],然后二叉地往上比较调整堆。
出队时,弹出queue[0],然后把queque[size]拿出来二叉地往下比较调整堆。
初始大小为11,空间不够时自动50%扩容。
线程安全的队列
1.1.4.4 ConcurrentLinkedQueue/Deque
无界的并发优化的Queue,基于链表,实现了依赖于CAS的无锁算法。
ConcurrentLinkedQueue的结构是单向链表和head/tail两个指针,因为入队时需要修改队尾元素的next指针,以及修改tail指向新入队的元素两个CAS动作无法原子,所以需要的特殊的算法。
线程安全的阻塞队列
BlockingQueue,一来如果队列已空不用重复的查看是否有新数据而会阻塞在那里,二来队列的长度受限,用以保证生产者与消费者的速度不会相差太远。当入队时队列已满,或出队时队列已空,不同函数的效果见下表:
| 立刻报异常 | 立刻返回布尔 | 阻塞等待 | 可设定等待时间 | |
| 入队 | add(e) | offer(e) | put(e) | offer(e, timeout, unit) |
| 出队 | remove() | poll() | take() | poll(timeout, unit) |
| 查看 | element() | peek() | 无 | 无 |
1.1.4.5 ArrayBlockingQueue
定长的并发优化的BlockingQueue,也是基于循环数组实现。有一把公共的锁与notFull、notEmpty两个Condition管理队列满或空时的阻塞状态。
1.1.4.6 LinkedBlockingQueue/Deque
可选定长的并发优化的BlockingQueue,基于链表实现,所以可以把长度设为Integer.MAX_VALUE成为无界无等待的。
利用链表的特征,分离了takeLock与putLock两把锁,继续用notEmpty、notFull管理队列满或空时的阻塞状态。
1.1.4.7 PriorityBlockingQueue
无界的PriorityQueue,也是基于数组存储的二叉堆(见前)。一把公共的锁实现线程安全。因为无界,空间不够时会自动扩容,所以入列时不会锁,出列为空时才会锁。
1.1.4.8 DelayQueue
内部包含一个PriorityQueue,同样是无界的,同样是出列时才会锁。一把公共的锁实现线程安全。元素需实现Delayed接口,每次调用时需返回当前离触发时间还有多久,小于0表示该触发了。
pull()时会用peek()查看队头的元素,检查是否到达触发时间。ScheduledThreadPoolExecutor用了类似的结构。
同步队列
SynchronousQueue同步队列本身无容量,放入元素时,比如等待元素被另一条线程的消费者取走再返回。JDK线程池里用它。
JDK7还有个LinkedTransferQueue,在普通线程安全的BlockingQueue的基础上,增加一个transfer(e) 函数,效果与SynchronousQueue一样。
参考:
1.2.1 线程安全、并发、线程安全的容器
1.2.1.1 线程安全
当多个线程访问一个对象时,如果不用考虑这些线程在运行时的环境下的调度和交替执行,
也不需要进行额外的同步,或者调用其他协作,这个情况下,线程就是安全的。
1.2.1.2 并发
并发和并行从宏观上来讲都是同时处理多路请求的概念。但并发和并行又有区别,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。
在操作系统中,并发是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
①程序与计算不再一一对应,一个程序副本可以有多个计算
②并发程序之间有相互制约关系,直接制约体现为一个程序需要另一个程序的计算结果,间接制约体现为多个程序竞争某一资源,如处理机、缓冲区等。
③并发程序在执行中是走走停停,断续推进的。
1.2.1.3 线程安全的容器
多线程环境正确发布共享数据的方法之一就是线程安全容器。
线程安全的容器是由锁保护的域,将数据放入线程安全的容器中,可以保障其被安全地发布给所有从这个容器访问它的线程。
1)同步容器类
JDK1.0开始有两个很老的同步容器类:Vector和HashTable。
JDK1.2之后Collections工具类中添加了一些工厂方法返回类似的同步封装器类:
public static <T> Collection<T>synchronizedCollection(Collection<T> c)
static<T> List<T> synchronizedList(List<T> list) //包装ArrayList、LinkedList
static<T> Set<T> synchronizedSet(Set<T> s) //包装HashSet
static<K,V> Map<K,V> synchronizedMap(Map<K,V> m) //包装HashMap
static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T>s) //包装TreeSet
static <K,V> SortedMap<K,V>synchronizedSortedMap(SortedMap<K,V> m) //包装TreeMap
实现方式:
将它们的状态封装起来,并对每一个公有方法进行同步。
其中Vector就是Object[]+synchronized方法,Hashtable是HashtableEntry[]+synchronized方法。而synchronizedXXX()方法返回的同步封装器类更是简单地将传进来的Collection的所有方法封装为synchronized方法而已。
缺点:
1、 通过同步方法将访问操作串行化,导致并发环境下效率低下
2、 复合操作(迭代、条件运算如没有则添加等)非线程安全,需要客户端代码来实现加锁。
2)并发容器类
并发容器出现的最大的需求就是提升同步容器类的性能!
可以对比(非并发容器类)看看,将单线程版本和并发版本做一个比较。
1、HashMap和HashSet的并发版本
1.1 ConcurrentHashMap<K, V>(HashMap的并发版本)
版本:JDK5
目标:代替Hashtable、synchronizedMap,支持复合操作
原理:采用一种更加细粒度的加锁机制“分段锁”,任意数量读取线程可以并发读取,任意数量的读取线程和一个写线程可以并发访问,一定数量的写入线程可以并发访问。并发环境下ConcurrentHashMap带来了更高的吞吐量,而在单线程环境下只损失了很小的性能。
1.2 CopyOnWriteArraySet<E>(HashSet的并发版本)
版本:JDK5
目标:代替synchronizedSet
原理:CopyOnWriteArraySet基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有则放入Object数组的尾部,并返回。
2、TreeMap和TreeSet的并发版本
ConcurrentSkipListMap<K, V>(TreeMap的并发版本)
版本:JDK6
目标:代替synchronizedSortedMap(TreeMap)
原理:Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。Skip list让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过"空间来换取时间"的一个算法。ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够在O(log(n))时间内完成查找、插入、删除操作。
ConcurrentSkipListSet<E>(TreeSet的并发版本)
版本:JDK6
目标:代替synchronizedSortedSet
原理:内部基于ConcurrentSkipListMap实现!
3、ArrayList和LinkedList的并发版本
CopyOnWriteArrayList<E>(ArrayList的并发版本)
目标:代替Vector、synchronizedList
原理:CopyOnWriteArrayList的核心思想是利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
ConcurrentLinkedQueue<E>(LinkedList的并发版本)
目标:代替Vector、synchronizedList
特点:基于链表实现的FIFO队列,特别注意单线程环境中LinkedList除了可以用作链表,也可用作队列,并发版本也一样
阻塞队列:BlockingQueue
版本:JDK1.5
特点:拓展了Queue,增加了可阻塞的插入和获取等操作
实现类
LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列
ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列
PriorityBlockingQueue:按优先级排序的队列
原理:通过ReentrantLock实现线程安全,通过Condition实现阻塞和唤醒。
1.2.2 核心理论
1)共享性
数据共享性是线程安全的主要原因之一。如果所有的数据只是在线程内有效,那就不存在线程安全性问题,这也是我们在编程的时候经常不需要考虑线程安全的主要原因之一。但是,在多线程编程中,数据共享是不可避免的。最典型的场景是数据库中的数据,为了保证数据的一致性,我们通常需要共享同一个数据库中数据,即使是在主从的情况下,访问的也同一份数据,主从只是为了访问的效率和数据安全,而对同一份数据做的副本。
2)互斥性
资源互斥是指同时只允许一个访问者对其进行访问,具有唯一性和排它性。我们通常允许多个线程同时对数据进行读操作,但同一时间内只允许一个线程对数据进行写操作。所以我们通常将锁分为共享锁和排它锁,也叫做读锁和写锁。如果资源不具有互斥性,即使是共享资源,我们也不需要担心线程安全。例如,对于不可变的数据共享,所有线程都只能对其进行读操作,所以不用考虑线程安全问题。但是对共享数据的写操作,一般就需要保证互斥性,上述例子中就是因为没有保证互斥性才导致数据的修改产生问题。Java 中提供多种机制来保证互斥性,最简单的方式是使用Synchronized。
3)原子性
原子性就是指对数据的操作是一个独立的、不可分割的整体。换句话说,就是一次操作,是一个连续不可中断的过程,数据不会执行的一半的时候被其他线程所修改。保证原子性的最简单方式是操作系统指令,就是说如果一次操作对应一条操作系统指令,这样肯定可以能保证原子性。但是很多操作不能通过一条指令就完成。例如,对long类型的运算,很多系统就需要分成多条指令分别对高位和低位进行操作才能完成。还比如,我们经常使用的整数 i++ 的操作,其实需要分成三个步骤:(1)读取整数 i 的值;(2)对 i 进行加一操作;(3)将结果写回内存。
这个过程在多线程下就可能出现如下现象:

这也是代码段一执行的结果为什么不正确的原因。对于这种组合操作,要保证原子性,最常见的方式是加锁,如Java中的Synchronized或Lock都可以实现,代码段二就是通过Synchronized实现的。除了锁以外,还有一种方式就是CAS(Compare And Swap),即修改数据之前先比较与之前读取到的值是否一致,如果一致,则进行修改,如果不一致则重新执行,这也是乐观锁的实现原理。不过CAS在某些场景下不一定有效,比如另一线程先修改了某个值,然后再改回原来值,这种情况下,CAS是无法判断的(ABA问题)。
4)可见性
要理解可见性,需要先对JVM的内存模型有一定的了解,JVM的内存模型与操作系统类似,如图所示:

从这个图中我们可以看出,每个线程都有一个自己的工作内存(相当于CPU高级缓冲区,这么做的目的还是在于进一步缩小存储系统与CPU之间速度的差异,提高性能),对于共享变量,线程每次读取的是工作内存中共享变量的副本,写入的时候也直接修改工作内存中副本的值,然后在某个时间点上再将工作内存与主内存中的值进行同步。这样导致的问题是,如果线程1对某个变量进行了修改,线程2却有可能看不到线程1对共享变量所做的修改。
5)有序性
为了提高性能,编译器和处理器可能会对指令做重排序。重排序可以分为三种:
(1)编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
(2)指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
(3)内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
1.2.3 java中线程安全的5个级别
(1)不可改变 final
从内部类中访问本地变量,需要被声明为最终类型。
(2)绝对安全
绝对安全其实很难描述,比如Vector是安全的。但是在多线程的情况下,它也是不安全的。
(3)相对安全
相对安全其实就是我们一般意义上的线程安全。
它需要保证对这个对象的单独操作是安全的。但是对于特定的顺序,需要一些方法保证线程安全。
(4)线程兼容
这就是我们常见的情况,需要使用synchronized等手段来保证线程安全。
(5)线程对立
比较极端的情况,就是无论怎么加锁,代码无法并发运行。一种情况就是死锁。
1.2.4 如何实现线程安全
(1)互斥同步
保持共享数据在同一时刻只被一个线程使用。
互斥是手段,同步是目的。
在java中最常见的就是synchronized方法。
synchronized标记的代码,会生成monitorenter & monitorexit 2段代码。
这是java编译器自动生成的,不会有遗漏。使用其他锁,lock & unlock成对出现,但是
开发者有时候会容易疏忽这个操作,尤其在catch代码里面忘记调用unlock,将是一个隐患。
java.util.concurrent 下面有不少同步的方法。ReentrantLock也是一个可以的方法,在1.5以前,性能
远由于synchronized。但是在1.6, java还是把synchronized做了很大的提升。原因就是synchronized使用的
代码已经远远大于ReentrantLock,并且引入ReentrantLock,可能会令需要开发者混淆。所以ReentrantLock可以认为是
一道开胃小菜而已。
(2)非阻塞同步
互斥同步是一种阻塞同步,但是有些情况下,我们不需要互斥,只要能够同步就可以。
java.util.concurrent.atomic.AtomicInteger
1.2.5 synchronized、lock、volatile
1.2.5.1 synchronized
1)synchronized的主要作用
(1)确保线程互斥的访问同步代码
(2)保证共享变量的修改能够及时可见
(3)有效解决重排序问题。
2)语法上的主要用法
(1)修饰普通方法
(2)修饰静态方法
(3)修饰代码块
3)实现原理
(1)synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
monitorenter :
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
(2)方法的同步并没有通过指令monitorenter和monitorexit来完成(理论上其实也可以通过这两条指令来实现),不过相对于普通方法,其常量池中多了ACC_SYNCHRONIZED标示符。JVM就是根据该标示符来实现方法的同步的:当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
4)当一个线程进入某个对象的一个synchronized的实例方法后,其它线程是否可进入此对象的其它方法?
答:A、一个线程在访问一个对象的同步方法时,另一个线程可以同时访问这个对象的非同步方法
B、 一个线程在访问一个对象的同步方法时,另一个线程不能同时访问这个同步方法。
1.2.5.2 volatile
volatile关键字就是Java中提供的另一种解决可见性和有序性问题的方案。对于原子性,需要强调一点,也是大家容易误解的一点:对volatile变量的单次读/写操作可以保证原子性的,如long和double类型变量,但是并不能保证i++这种操作的原子性,因为本质上i++是读、写两次操作。
volatile的使用
1)防止重排序
先要了解对象的构造过程,实例化一个对象其实可以分为三个步骤:
(1)分配内存空间。
(2)初始化对象。
(3)将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
(1)分配内存空间。
(2)将内存空间的地址赋值给对应的引用。
(3)初始化对象
如果是这个流程,多线程环境下就可能将一个未初始化的对象引用暴露出来,从而导致不可预料的结果。因此,为了防止这个过程的重排序,我们需要将变量设置为volatile类型的变量。
有序性实现原理:
happen-before规则:
- 同一个线程中的,前面的操作 happen-before 后续的操作。(即单线程内按代码顺序执行。但是,在不影响在单线程环境执行结果的前提下,编译器和处理器可以进行重排序,这是合法的。换句话说,这一是规则无法保证编译重排和指令重排)。
- 监视器上的解锁操作 happen-before 其后续的加锁操作。(Synchronized 规则)
- 对volatile变量的写操作 happen-before 后续的读操作。(volatile 规则)
- 线程的start() 方法 happen-before 该线程所有的后续操作。(线程启动规则)
- 线程所有的操作 happen-before 其他线程在该线程上调用 join 返回成功后的操作。
- 如果 a happen-before b,b happen-before c,则a happen-before c(传递性)。
2)实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile关键字能有效的解决这个问题。
可见性实现原理:
在前文中已经提及过,线程本身并不直接与主内存进行数据的交互,而是通过线程的工作内存来完成相应的操作。这也是导致线程间数据不可见的本质原因。因此要实现volatile变量的可见性,直接从这方面入手即可。对volatile变量的写操作与普通变量的主要区别有两点:
(1)修改volatile变量时会强制将修改后的值刷新的主内存中。
(2)修改volatile变量后会导致其他线程工作内存中对应的变量值失效。因此,再读取该变量值的时候就需要重新从读取主内存中的值。
通过这两个操作,就可以解决volatile变量的可见性问题。
3)保证原子性
volatile只能保证对单次读/写的原子性。
因为long和double两种数据类型的操作可分为高32位和低32位两部分,因此普通的long或double类型读/写可能不是原子的。因此,鼓励大家将共享的long和double变量设置为volatile类型,这样能保证任何情况下对long和double的单次读/写操作都具有原子性。
i++其实是一个复合操作,包括三步骤:
(1)读取i的值。
(2)对i加1。
(3)将i的值写回内存。
volatile是无法保证这三个操作是具有原子性的,我们可以通过AtomicInteger或者Synchronized来保证+1操作的原子性。
1.2.5.3 lock
1)什么是可重入锁(ReentrantLock)?
答: java.util.concurrent.lock 中的 Lock 框架是锁定的一个抽象,它允许把锁定的实现作为 Java 类,而不是作为语言的特性来实现。这就为 Lock 的多种实现留下了空间,各种实现可能有不同的调度算法、性能特性或者锁定语义。 ReentrantLock 类实现了 Lock ,它拥有与 synchronized 相同的并发性和内存语义,但是添加了类似锁投票、定时锁等候和可中断锁等候的一些特性。此外,它还提供了在激烈争用情况下更佳的性能。(换句话说,当许多线程都想访问共享资源时,JVM 可以花更少的时候来调度线程,把更多时间用在执行线程上。)
reentrant 锁意味着什么呢?简单来说,它有一个与锁相关的获取计数器,如果拥有锁的某个线程再次得到锁,那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放。这模仿了 synchronized 的语义;如果线程进入由线程已经拥有的监控器保护的 synchronized 块,就允许线程继续进行,当线程退出第二个(或者后续)synchronized 块的时候,不释放锁,只有线程退出它进入的监控器保护的第一个 synchronized 块时,才释放锁。
2)synchronized和java.util.concurrent.locks.Lock的异同?
答:Lock 和 synchronized 有一点明显的区别 —— lock 必须在 finally 块中释放。否则,如果受保护的代码将抛出异常,锁就有可能永远得不到释放!这一点区别看起来可能没什么,但是实际上,它极为重要。忘记在 finally 块中释放锁,可能会在程序中留下一个定时炸弹,当有一天炸弹爆炸时,您要花费很大力气才有找到源头在哪。而使用同步,JVM 将确保锁会获得自动释放。
1.2.5.4 内存屏障
为了实现volatile可见性和happen-befor的语义。JVM底层是通过一个叫做“内存屏障”的东西来完成。内存屏障,也叫做内存栅栏,是一组处理器指令,用于实现对内存操作的顺序限制。下面是完成上述规则所要求的内存屏障:
| Required barriers | 2nd operation | |||
| 1st operation | Normal Load | Normal Store | Volatile Load | Volatile Store |
| Normal Load | LoadStore | |||
| Normal Store | StoreStore | |||
| Volatile Load | LoadLoad | LoadStore | LoadLoad | LoadStore |
| Volatile Store | StoreLoad | StoreStore | ||
(1)LoadLoad 屏障
执行顺序:Load1—>Loadload—>Load2
确保Load2及后续Load指令加载数据之前能访问到Load1加载的数据。
(2)StoreStore 屏障
执行顺序:Store1—>StoreStore—>Store2
确保Store2以及后续Store指令执行前,Store1操作的数据对其它处理器可见。
(3)LoadStore 屏障
执行顺序: Load1—>LoadStore—>Store2
确保Store2和后续Store指令执行前,可以访问到Load1加载的数据。
(4)StoreLoad 屏障
执行顺序: Store1—> StoreLoad—>Load2
确保Load2和后续的Load指令读取之前,Store1的数据对其他处理器是可见的。
1.2.6 java锁类型,各自的特性
锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过-XX:-UseBiasedLocking来禁用偏向锁。锁的状态保存在对象的头文件中,以32位的JDK为例:
|
锁状态 |
25 bit |
4bit |
1bit |
2bit |
||
|
23bit |
2bit |
是否是偏向锁 |
锁标志位 |
|||
|
轻量级锁 |
指向栈中锁记录的指针 |
00 |
||||
|
重量级锁 |
指向互斥量(重量级锁)的指针 |
10 |
||||
|
GC标记 |
空 |
11 |
||||
|
偏向锁 |
线程ID |
Epoch |
对象分代年龄 |
1 |
01 |
|
|
无锁 |
对象的hashCode |
对象分代年龄 |
0 |
01 |
||
“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的。但是,首先需要强调一点的是,轻量级锁并不是用来代替重量级锁的,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用产生的性能消耗。在解释轻量级锁的执行过程之前,先明白一点,轻量级锁所适应的场景是线程交替执行同步块的情况,如果存在同一时间访问同一锁的情况,就会导致轻量级锁膨胀为重量级锁。
1)自旋锁
自旋锁有时候会白白的耗用处理器的资源,但是没有任何实际效果。
适应性自旋(Adaptive Spinning):从轻量级锁获取的流程中我们知道,当线程在获取轻量级锁的过程中执行CAS操作失败时,是要通过自旋来获取重量级锁的。问题在于,自旋是需要消耗CPU的,如果一直获取不到锁的话,那该线程就一直处在自旋状态,白白浪费CPU资源。解决这个问题最简单的办法就是指定自旋的次数,例如让其循环10次,如果还没获取到锁就进入阻塞状态。但是JDK采用了更聪明的方式——适应性自旋,简单来说就是线程如果自旋成功了,则下次自旋的次数会更多,如果自旋失败了,则自旋的次数就会减少。
2)锁消除(Lock Elimination)
锁消除即删除不必要的加锁操作。根据代码逃逸技术,如果判断到一段代码中,堆上的数据不会逃逸出当前线程,那么可以认为这段代码是线程安全的,不必要加锁。
如果代码不可能存在共享数据需要同步,编译器就会把锁拿掉。
3)锁粗化(Lock Coarsening)
锁粗化的概念应该比较好理解,就是将多次连接在一起的加锁、解锁操作合并为一次,将多个连续的锁扩展成一个范围更大的锁。
原则上锁的互斥模块尽可能的小,但是如果对于同一对象,反复的lock & unlock 尤其是循环体中。会带来很大的性能损失。
|
锁 |
优点 |
缺点 |
适用场景 |
|
偏向锁 |
加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。 |
如果线程间存在锁竞争,会带来额外的锁撤销的消耗。 |
适用于只有一个线程访问同步块场景。 |
|
轻量级锁 |
竞争的线程不会阻塞,提高了程序的响应速度。 |
如果始终得不到锁竞争的线程使用自旋会消耗CPU。 |
追求响应时间。 同步块执行速度非常快。 |
|
重量级锁 |
线程竞争不使用自旋,不会消耗CPU。 |
线程阻塞,响应时间缓慢。 |
追求吞吐量。 同步块执行速度较长。 |
1.2.8 线程的状态
Java中线程中状态可分为五种:New(新建状态),Runnable(就绪状态),Running(运行状态),Blocked(阻塞状态),Dead(死亡状态)。
New:新建状态,当线程创建完成时为新建状态,即new Thread(...),还没有调用start方法时,线程处于新建状态。
Runnable:就绪状态,当调用线程的的start方法后,线程进入就绪状态,等待CPU资源。处于就绪状态的线程由Java运行时系统的线程调度程序(thread scheduler)来调度。
Running:运行状态,就绪状态的线程获取到CPU执行权以后进入运行状态,开始执行run方法。
Blocked:阻塞状态,线程没有执行完,由于某种原因(如,I/O操作等)让出CPU执行权,自身进入阻塞状态。
Dead:死亡状态,线程执行完成或者执行过程中出现异常,线程就会进入死亡状态。
这五种状态之间的转换关系如下图所示:

1.2.9 线程间的协作
参考:
1)wait方法
(1)wait()方法的作用是将当前运行的线程挂起(即让其进入阻塞状态),直到notify或notifyAll方法来唤醒线程.
(2)wait(long timeout),该方法与wait()方法类似,唯一的区别就是在指定时间内,如果没有notify或notifAll方法的唤醒,也会自动唤醒。
(3)至于wait(long timeout,long nanos),本意在于更精确的控制调度时间,不过从目前版本来看,该方法貌似没有完整的实现该功能
wait方法的使用必须在同步的范围内,否则就会抛出IllegalMonitorStateException异常,wait方法的作用就是阻塞当前线程等待notify/notifyAll方法的唤醒,或等待超时后自动唤醒。
| void notify() | Wakes up a single thread that is waiting on this object's monitor. |
| void notifyAll() | Wakes up all threads that are waiting on this object's monitor. |
有了对wait方法原理的理解,notify方法和notifyAll方法就很容易理解了。既然wait方式是通过对象的monitor对象来实现的,所以只要在同一对象上去调用notify/notifyAll方法,就可以唤醒对应对象monitor上等待的线程了。notify和notifyAll的区别在于前者只能唤醒monitor上的一个线程,对其他线程没有影响,而notifyAll则唤醒所有的线程。
最后,有两点点需要注意:
(1)调用wait方法后,线程是会释放对monitor对象的所有权的。
(2)一个通过wait方法阻塞的线程,必须同时满足以下两个条件才能被真正执行:
- 线程需要被唤醒(超时唤醒或调用notify/notifyll)。
- 线程唤醒后需要竞争到锁(monitor)。
notify()是唤醒一个线程。只唤醒一个。
notifyAll()是唤醒全部线程,但是注意是一个个唤醒,唤醒一个再唤下一个。
随机唤醒和唤醒全部。
3)sleep方法
这组方法跟上面方法的最明显区别是:这几个方法都位于Thread类中,而上面三个方法都位于Object类中。
sleep方法的作用是让当前线程暂停指定的时间(毫秒),sleep方法是最简单的方法,在上述的例子中也用到过,比较容易理解。唯一需要注意的是其与wait方法的区别。最简单的区别是,wait方法依赖于同步,而sleep方法可以直接调用。而更深层次的区别在于sleep方法只是暂时让出CPU的执行权,并不释放锁。而wait方法则需要释放锁。
通过sleep方法实现的暂停,程序是顺序进入同步块的,只有当上一个线程执行完成的时候,下一个线程才能进入同步方法,sleep暂停期间一直持有monitor对象锁,其他线程是不能进入的。而wait方法则不同,当调用wait方法后,当前线程会释放持有的monitor对象锁,因此,其他线程还可以进入到同步方法,线程被唤醒后,需要竞争锁,获取到锁之后再继续执行。
这个结果的区别很明显,通过sleep方法实现的暂停,程序是顺序进入同步块的,只有当上一个线程执行完成的时候,下一个线程才能进入同步方法,sleep暂停期间一直持有monitor对象锁,其他线程是不能进入的。而wait方法则不同,当调用wait方法后,当前线程会释放持有的monitor对象锁,因此,其他线程还可以进入到同步方法,线程被唤醒后,需要竞争锁,获取到锁之后再继续执行。
sleep()和 wait()有什么区别?
定时等待和在监视器上等待,不同范畴。
4)yield方法
yield方法的作用是暂停当前线程,以便其他线程有机会执行,不过不能指定暂停的时间,并且也不能保证当前线程马上停止。yield方法只是将Running状态转变为Runnable状态。
通过yield方法来实现两个线程的交替执行。不过请注意:这种交替并不一定能得到保证。
/** * A hint to the scheduler that the current thread is willing to yield * its current use of a processor. The scheduler is free to ignore this * hint. * * <p> Yield is a heuristic attempt to improve relative progression * between threads that would otherwise over-utilise a CPU. Its use * should be combined with detailed profiling and benchmarking to * ensure that it actually has the desired effect. * * <p> It is rarely appropriate to use this method. It may be useful * for debugging or testing purposes, where it may help to reproduce * bugs due to race conditions. It may also be useful when designing * concurrency control constructs such as the ones in the * {@link java.util.concurrent.locks} package. */
这段话主要说明了三个问题:
- 调度器可能会忽略该方法。
- 使用的时候要仔细分析和测试,确保能达到预期的效果。
- 很少有场景要用到该方法,主要使用的地方是调试和测试。
5)join方法
| void join() | Waits for this thread to die. |
| void join(long millis) | Waits at most millis milliseconds for this thread to die. |
| void join(long millis, int nanos) | Waits at most millis milliseconds plus nanos nanoseconds for this thread to die. |
join方法的作用是父线程等待子线程执行完成后再执行,换句话说就是将异步执行的线程合并为同步的线程。JDK中提供三个版本的join方法,其实现与wait方法类似,join()方法实际上执行的join(0),而join(long millis, int nanos)也与wait(long millis, int nanos)的实现方式一致,暂时对纳秒的支持也是不完整的。
6)问题:wait/notify/notifyAll方法的作用是实现线程间的协作,那为什么这三个方法不是位于Thread类中,而是位于Object类中?
位于Object中,也就相当于所有类都包含这三个方法(因为Java中所有的类都继承自Object类)。
要回答这个问题,还是得回过来看wait方法的实现原理,大家需要明白的是,wait等待的到底是什么东西?如果对上面内容理解的比较好的话,我相信大家应该很容易知道wait等待其实是对象monitor,由于Java中的每一个对象都有一个内置的monitor对象,自然所有的类都理应有wait/notify方法。
1)什么是ThreadLocal
早在JDK 1.2的版本中就提供java.lang.ThreadLocal,ThreadLocal为解决多线程程序的并发问题提供了一种新的思路。使用这个工具类可以很简洁地编写出优美的多线程程序。
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
从线程的角度看,目标变量就象是线程的本地变量,这也是类名中“Local”所要表达的意思。
2)Thread同步机制的比较
对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
3)java.lang.ThreadLocal<T>的具体实现
(1)set
getMap和createMap
(2)get方法
(3)setInitialValue方法
4)jvm怎么让多线程new 对象时候 内存不用加锁
预先分配一定量的内存给线程。
1.2.10 java多线程api及jdk1.5以后new api
1)concurrent包下面,都用过什么?
Executor :具体Runnable任务的执行者。线程池
ExecutorService :一个线程池管理者,其实现类有多种,我会介绍一部分。我们能把Runnable,Callable提交到池中让其调度。
Semaphore :一个计数信号量
ReentrantLock :一个可重入的互斥锁定 Lock,功能类似synchronized,但要强大的多。
Future :是与Runnable,Callable进行交互的接口,比如一个线程执行结束后取返回的结果等等,还提供了cancel终止线程。
BlockingQueue :阻塞队列。
CompletionService : ExecutorService的扩展,可以获得线程执行结果的
CountDownLatch :一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
CyclicBarrier :一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点
Future :Future 表示异步计算的结果。
ScheduledExecutorService :一个 ExecutorService,可安排在给定的延迟后运行或定期执行的命令
2)线程池用过吗?
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。
如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。
如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程的数目永远不会超过最大值。
超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。
3)java中有几种方法可以创建一个线程?
4)如何停止一个正在运行的线程?
- 如果该线程正阻塞于Object类的wait()、wait(long)、wait(long, int)方法,或者Thread类的join()、join(long)、join(long, int)、sleep(long)、sleep(long, int)方法,则该线程的中断状态将被清除,并收到一个java.lang.InterruptedException。
- 如果该线程正阻塞于interruptible channel上的I/O操作,则该通道将被关闭,同时该线程的中断状态被设置,并收到一个java.nio.channels.ClosedByInterruptException。
- 如果该线程正阻塞于一个java.nio.channels.Selector操作,则该线程的中断状态被设置,它将立即从选择操作返回,并可能带有一个非零值,就好像调用java.nio.channels.Selector.wakeup()方法一样。
- 如果上述条件都不成立,则该线程的中断状态将被设置。
3)jdk1.8的JVM内存模型
4)jdk不同版本之间的特性
5)JVM分为哪些区,每一个区干吗的?
多数 JVM 将内存区域划分为方法区 , Heap(堆) , Program Counter Register(程序计数器) , VM Stack(Java虚拟机栈),Native Method Stack ( 本地方法栈 )
方法区:线程共享区域,Object Class Data(加载类的类定义数据) 是存储在方法区的。除此之外, 常量 、 静态变量 、JIT(即时编译器)编译后的代码也都在方法区。
程序计数器是一块较小的内存区域,作用可以看做是当前线程执行的字节码的位置指示器。分支、循环、跳转、异常处理和线程恢复等基础功能都需要依赖这个计算器来完成,不多说。
Java虚拟机栈:Java虚拟机栈是线程私有,生命周期与线程相同,描述Java方法执行的内存模型,(每个方法执行的同时创建帧栈(Strack Frame)用于存储局部变量表,操作数栈,动态链接、方法出口等信息)
Heap(堆)在:虚拟机管理的内存中最大的一块,线程共享的内存区域,JVM启动时候创建,专门用来保存对象的实例。
本地方法栈:与VM Strack相似,VM Strack为JVM提供执行JAVA方法的服务,Native Method Stack则为JVM提供使用native 方法的服务。
3)内存映射的原理
3)集中垃圾回收算法
4)JVM如何GC,新生代,老年代大对象,永久代,都存储哪些东西?
采用分代收集算法,新生代采用复制算法,老年代采用标记整理算法。
新生代– 新创建的对象,
旧生代 – 经过多次垃圾回收没有被回收的对象或者大对象
持久代– JVM使用的内存,包含类信息等
5)GC用的引用可达性分析算法中,哪些对象可作为GC Roots对象?
younggc来说,gcroot的对象包括:
(1)所有老年代对象
(2)所有全局对象
(3)所有jni句柄
(4)所有上锁对象
(5)jvmti持有的对象
(6)代码段code_cache
(7)所有classloader,及其加载的class
(8)所有字典
(9)flat_profiler和management
(10)最重要的,所有运行中线程栈上的引用类型变量。
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载七个阶段。
其中类加载的过程包括了加载、验证、准备、解析、初始化五个阶段。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持 Java 语言的运行时绑定(也成为动态绑定或晚期绑定)。
另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
8)双亲委派模型中有哪些方法?
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。这些类加载器的父子关系不是以继承的关系实现,而都是使用组合关系来复用父加载器的代码。
双亲委派模型的工作过程:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每个层次的类加载器都是如此。因此所有的加载请求最终都应该传达到顶层的启动类加载器中,只有当父加载器反馈无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
findLoadedClass(name); loadClass(name, false); findClass(name); resolveClass(c);
9)JVM类加载替换jdk的jar包
http://zoeminghong.github.io/2016/05/31/jvm20160531/
10)线程上下文类加载器(ContextClassLoader)
Java类加载器之线程上下文类加载器(ContextClassLoader)
1.3.4 JVM调优
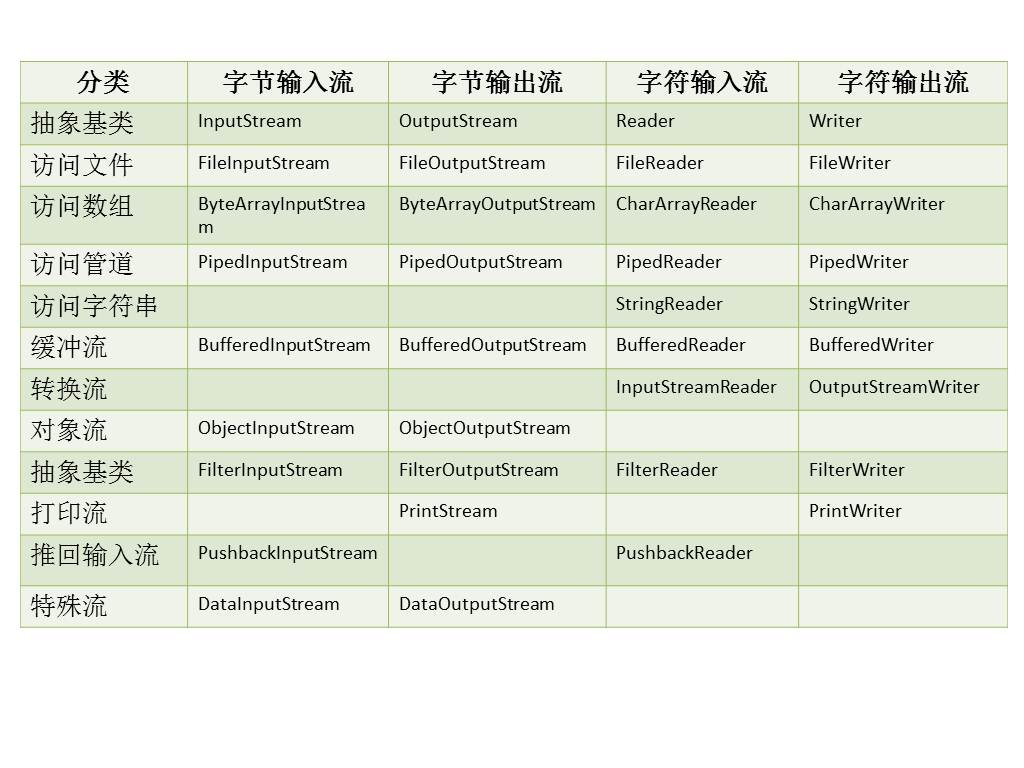
1.4.0 文件IO流
字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件,如图12-6所示。

同步、异步、阻塞、非阻塞
1)同步异步与阻塞非阻塞
IO的两个重要步骤:发起IO请求,和实际的IO操作。
(1)同步和异步的区别
在unix网络编程的定义里异步和非异步概念的区别就是实际的IO操作是否阻塞。如果不是就是异步,如果是就是同步。
同步就是指一个线程要等待上一个线程执行完之后才开始执行当前的线程。
异步是指一个线程去执行,它的下一个线程不必等待它执行完就开始执行。
同步和异步是针对应用程序和内核的交互而言的,同步指的是用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪,而异步是指用户进程触发IO操作以后便开始做自己的事情,而当IO操作已经完成的时候会得到IO完成的通知。
(2)阻塞和非阻塞的区别
而阻塞和非阻塞的区别在于发起IO请求的时候是否会阻塞,如果会就是阻塞,不会就是非阻塞。
阻塞和非阻塞是针对于进程在访问数据的时候,根据IO操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作函数的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入函数会立即返回一个状态值。
同步和异步是目的,阻塞和非阻塞是实现方式。
| 编号 | 名词 | 解释 | 举例 |
| 1 | 同步 | 指的是用户进程触发IO操作并等待或者轮询的去查看IO操作是否就绪 | 自己上街买衣服,自己亲自干这件事,别的事干不了。 |
| 2 | 异步 | 异步是指用户进程触发IO操作以后便开始做自己的事情,而当IO操作已经完成的时候会得到IO完成的通知(异步的特点就是通知) | 告诉朋友自己合适衣服的尺寸,大小,颜色,让朋友委托去卖,然后自己可以去干别的事。(使用异步IO时,Java将IO读写委托给OS处理,需要将数据缓冲区地址和大小传给OS) |
| 3 | 阻塞 | 所谓阻塞方式的意思是指, 当试图对该文件描述符进行读写时, 如果当时没有东西可读,或者暂时不可写, 程序就进入等待 状态, 直到有东西可读或者可写为止 | 去公交站充值,发现这个时候,充值员不在(可能上厕所去了),然后我们就在这里等待,一直等到充值员回来为止。(当然现实社会,可不是这样,但是在计算机里确实如此。) |
| 4 | 非阻塞 | 非阻塞状态下, 如果没有东西可读, 或者不可写, 读写函数马上返回, 而不会等待, | 银行里取款办业务时,领取一张小票,领取完后我们自己可以玩玩手机,或者与别人聊聊天,当轮我们时,银行的喇叭会通知,这时候我们就可以去了。 |
2)组合方式的IO类型
(1)同步阻塞IO(JAVA BIO):
同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
(2)同步非阻塞IO(Java NIO) : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。用户进程也需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问。
(3)异步阻塞IO(Java NIO):
此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄(如果从UNP的角度看,select属于同步操作。因为select之后,进程还需要读写数据),从而提高系统的并发性!
(4)异步非阻塞IO(Java AIO(NIO.2)):
在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。
3)BIO、NIO、AIO适用场景分析
(1)BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
(2)NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
(3)AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
1.4.4 读取大文件
(1)在内存中读取
文件的所有行都被存放在内存中,当文件足够大时很快就会导致程序抛出OutOfMemoryError 异常。
(2)使用文件流读取
使用java.util.Scanner类扫描文件的内容,一行一行连续地读取。
(3)使用Apache Common IO流
使用Commons IO库实现,利用该库提供的自定义LineIterator。
(4)RandomAccessFile 操作动态文件
分析日志系统,多线程操作同一文件更高效,方便。
(5)分段读取文件
2)Linux读写超过2G的文件
linux默认环境下打开、读、写超过2G的文件会返回错误。
看到了linux的ext2文件大小的限制。根据ext2的结构一共是三级索引,文件最大可达12KB+256KB+64MB+16GB。呵呵,linux操作系统是32位操作系统文件大小只能是4G。呵呵
好像以前的版本均有2G限制。
如何解决linux下文件大小的限制:
在linux下,用fwrite等C API函数来写文件时,会有一个文件大小的限制,一般是2G。
在linux下fopen对要打开的文件大小是有限制的,限制来源于off_t这个类型大小的限制:
“lseek(2) uses the type off_t. This is a 32-bit signed type on 32-bit architectures, unless one compiles with
#define _FILE_OFFSET_BITS 64
in which case it is a 64-bit signed type”摘自man
对于32位程序,fopen无法打开大于2G的文件,但可用下面的方法突破限制:
(1)编译成64位程序
(2)使用fopen64,fseek64
(3)文件开头加上#define _FILE_OFFSET_BITS 64
3)jdk5,6的build in的zip都不支持4G以上的zip文件,jdk7支持
5000多万的文件,txt文件超过4G,zip大约为600多MB。
http://blogs.oracle.com/xuemingshen/entry/zip64_support_for_4g_zipfile
jdk 5, 6 的build in 的zip 都不支持 4G 以上的 zip文件,不过 jdk 7 支持。
如果不用最新的jdk 7的话,你可以用第三方的zip库的,
你可以看看这个符不符合你的要求 http://commons.apache.org/compress/index.html
1.5 序列化
1.5.1 transient关键字
参考:
1)当对象被序列化时(写入字节序列到目标文件)时,transient阻止实例中那些用此关键字声明的变量持久化;当对象被反序列化时(从源文件读取字节序列进行重构),这样的实例变量值不会被持久化和恢复。
1.5.2 序列化的原理
参考:
1)Java 的序列化做什么用的,序列化id会出现哪些问题?
(1)序列化就是将一个对象的状态(各个属性量)保存起来,然后在适当的时候再获得。
(2)虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。
1.6 异常
1)java中有哪些异常?这些异常怎么避免呢?假如是空指针,怎么避免它呢?
2. 玩好JDK
参考:http://www.zuoxiaolong.com/html/article_232.html
2.1 Java运行时环境,即JVM
2.2 Java的基础类库
1)JDK6的包列表
java.applet
java.awt
java.awt.color
java.awt.datatransfer
java.awt.dnd
java.awt.event
java.awt.font
java.awt.geom
java.awt.im
java.awt.im.spi
java.awt.image
java.awt.image.renderable
java.awt.print
java.beans
java.beans.beancontext
java.io
java.lang
java.lang.annotation
java.lang.instrument
java.lang.management
java.lang.ref
java.lang.reflect
java.math
java.net
java.nio
java.nio.channels
java.nio.channels.spi
java.nio.charset
java.nio.charset.spi
java.rmi
java.rmi.activation
java.rmi.dgc
java.rmi.registry
java.rmi.server
java.security
java.security.acl
java.security.cert
java.security.interfaces
java.security.spec
java.sql
java.text
java.text.spi
java.util
java.util.concurrent
java.util.concurrent.atomic
java.util.concurrent.locks
java.util.jar
java.util.logging
java.util.prefs
java.util.regex
java.util.spi
java.util.zip
javax.accessibility
javax.activation
javax.activity
javax.annotation
javax.annotation.processing
javax.crypto
javax.crypto.interfaces
javax.crypto.spec
javax.imageio
javax.imageio.event
javax.imageio.metadata
javax.imageio.plugins.bmp
javax.imageio.plugins.jpeg
javax.imageio.spi
javax.imageio.stream
javax.jws
javax.jws.soap
javax.lang.model
javax.lang.model.element
javax.lang.model.type
javax.lang.model.util
javax.management
javax.management.loading
javax.management.modelmbean
javax.management.monitor
javax.management.openmbean
javax.management.relation
javax.management.remote
javax.management.remote.rmi
javax.management.timer
javax.naming
javax.naming.directory
javax.naming.event
javax.naming.ldap
javax.naming.spi
javax.net
javax.net.ssl
javax.print
javax.print.attribute
javax.print.attribute.standard
javax.print.event
javax.rmi
javax.rmi.CORBA
javax.rmi.ssl
javax.script
javax.security.auth
javax.security.auth.callback
javax.security.auth.kerberos
javax.security.auth.login
javax.security.auth.spi
javax.security.auth.x500
javax.security.cert
javax.security.sasl
javax.sound.midi
javax.sound.midi.spi
javax.sound.sampled
javax.sound.sampled.spi
javax.sql
javax.sql.rowset
javax.sql.rowset.serial
javax.sql.rowset.spi
javax.swing
javax.swing.border
javax.swing.colorchooser
javax.swing.event
javax.swing.filechooser
javax.swing.plaf
javax.swing.plaf.basic
javax.swing.plaf.metal
javax.swing.plaf.multi
javax.swing.plaf.synth
javax.swing.table
javax.swing.text
javax.swing.text.html
javax.swing.text.html.parser
javax.swing.text.rtf
javax.swing.tree
javax.swing.undo
javax.tools
javax.transaction
javax.transaction.xa
javax.xml
javax.xml.bind
javax.xml.bind.annotation
javax.xml.bind.annotation.adapters
javax.xml.bind.attachment
javax.xml.bind.helpers
javax.xml.bind.util
javax.xml.crypto
javax.xml.crypto.dom
javax.xml.crypto.dsig
javax.xml.crypto.dsig.dom
javax.xml.crypto.dsig.keyinfo
javax.xml.crypto.dsig.spec
javax.xml.datatype
javax.xml.namespace
javax.xml.parsers
javax.xml.soap
javax.xml.stream
javax.xml.stream.events
javax.xml.stream.util
javax.xml.transform
javax.xml.transform.dom
javax.xml.transform.sax
javax.xml.transform.stax
javax.xml.transform.stream
javax.xml.validation
javax.xml.ws
javax.xml.ws.handler
javax.xml.ws.handler.soap
javax.xml.ws.http
javax.xml.ws.soap
javax.xml.ws.spi
javax.xml.ws.wsaddressing
javax.xml.xpath
org.ietf.jgss
org.omg.CORBA
org.omg.CORBA_2_3
org.omg.CORBA_2_3.portable
org.omg.CORBA.DynAnyPackage
org.omg.CORBA.ORBPackage
org.omg.CORBA.portable
org.omg.CORBA.TypeCodePackage
org.omg.CosNaming
org.omg.CosNaming.NamingContextExtPackage
org.omg.CosNaming.NamingContextPackage
org.omg.Dynamic
org.omg.DynamicAny
org.omg.DynamicAny.DynAnyFactoryPackage
org.omg.DynamicAny.DynAnyPackage
org.omg.IOP
org.omg.IOP.CodecFactoryPackage
org.omg.IOP.CodecPackage
org.omg.Messaging
org.omg.PortableInterceptor
org.omg.PortableInterceptor.ORBInitInfoPackage
org.omg.PortableServer
org.omg.PortableServer.CurrentPackage
org.omg.PortableServer.POAManagerPackage
org.omg.PortableServer.POAPackage
org.omg.PortableServer.portable
org.omg.PortableServer.ServantLocatorPackage
org.omg.SendingContext
org.omg.stub.java.rmi
org.w3c.dom
org.w3c.dom.bootstrap
org.w3c.dom.events
org.w3c.dom.ls
org.xml.sax
org.xml.sax.ext
org.xml.sax.helpers
2)精读源码
java.io
java.lang
java.util
精读源码,这是要求最高的级别。这三个包都是你最常用。lang包、io包读写文件,util包数据结构。
3)深刻理解
java.lang.reflect java.net javax.net.* java.nio.* java.util.concurrent.*
reflect代表反射,net代表网络IO,nio代表非阻塞IO,concurrent代表并发。
反射你要了解清楚的话,你是不是要搞明白JVM的类加载机制?
网络IO要搞清楚的话,你是不是要清楚TCP/IP和HTTP、HTTPS?
包括并发包,如果你要搞清楚的话,是不是要了解并发的相关知识?
4)会用即可
java.lang.annotation javax.annotation.* java.lang.ref java.math java.rmi.* javax.rmi.* java.security.* javax.security.* java.sql javax.sql.* javax.transaction.* java.text javax.xml.* org.w3c.dom.* org.xml.sax.* javax.crypto.* javax.imageio.* javax.jws.* java.util.jar java.util.logging java.util.prefs java.util.regex java.util.zip
5)请无视它
swing、awt
2.3 Java开发工具,即JDK
2.3.1 JDK内置工具
http://blog.csdn.net/fenglibing/article/details/6411953
(1)javah
http://www.hollischuang.com/archives/1107
(2)jps
http://www.hollischuang.com/archives/105
(3)jstack
http://www.cnblogs.com/nexiyi/p/java_thread_jstack.html
http://www.hollischuang.com/archives/110
(4)jstat
http://www.cnblogs.com/ListenWind/p/5230118.html
http://www.hollischuang.com/archives/481
(5)jmap
http://www.hollischuang.com/archives/303
(6)jinfo
http://www.hollischuang.com/archives/1094
(7)jconsole
(8)jvisualvm
(9)jhat
http://www.hollischuang.com/archives/1047
(10)jdb
2.3.2 JVM故障分析
2)三个实例演示 Java Thread Dump 日志分析
4)jvm内存调优用过哪些工具,jstat做什么用的?如何dump出当前线程状态?
2.4 看源码
1)看过哪些源码
2.5 String
1)java中String类为什么要设计成final,StringBuffer 、StringBuilder的区别
2)String里面hashcode的实现方式
《程序员编程艺术:面试和算法心得》
3.29 算法牛人
1)9个offer,12家公司,35场面试,从微软到谷歌,应届计算机毕业生的2012求职之路
3)程序员必读书单
3.30 手写代码
1)写代码,实现一个线程池 写一个并发只支持qps200的接口
对一个IP排序 对一堆IP排序去重复
2)用并发的方式去做
(1)找出交易额最多的10个省份
(2)还有一个是有0到100的数字,找出相加为100的数字对
(3)求两个数组交集
3)链表笔试题
如何判断一个单链表是否有环?
如果有两个头结点指针,一个走的快,一个走的慢,那么若干步以后,快的指针总会超过慢的指针一圈。
5)二叉树
6)时间复杂度和空间复杂度
| 隔离等级 | 脏读 | 不可重复读 | 幻读 |
| 读未提交RU | Yes | Yes | Yes |
| 读已提交RC | No | Yes | Yes |
| 可重复读RR | No | No | Yes |
| 串行化 | No | No | No |
mysql 索引类型
3)数据库中的索引的结构?什么情况下适合建索引?
4)聚集索引和非聚集索引的区别
4.4 主键
1)数据库设计中主键id设计的原则
4.5 SQL
1)PreparedStatement 优点
2)SQL 批处理的优点
3)where having区别
4)join 查询的几种方式
5)sql优化,具体场景、优化过程
6)mysql.oralce 优化策略
(1)索引
(2)用具体的字段列表代替“*"
(3)exists 代替 in
(4)尽量避免在where子句中对字段使用函数
(5)能用 between 就不要用 in 了
(6)避免在 where 子句中使用 or 来连接条件
(7)尽量避免在 where 子句中对字段进行 null 值判断
(8)尽量避免在 where 子句中使用!=或<>操作符
(9)尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
物化视图:
create materialized view mv_name refresh force on demand start with sysdate next
to_date(concat(to_char( sysdate+1,'dd-mm-yyyy'),'10:25:00'),'dd-mm-yyyy hh24:mi:ss') as select * from table_name --这个物化视图在每天10:25进行刷新
4.6 数据库高可用
1)mysql 主从分离,分库分表
4.7 数据库设计
1)数据库中的范式有哪些?
第一范式:确保每列的原子性.
如果每列(或者每个属性)都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式.
例如:顾客表(姓名、编号、地址、……)其中"地址"列还可以细分为国家、省、市、区等。
第二范式:在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关.
如果一个关系满足第一范式,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式.
例如:订单表(订单编号、产品编号、定购日期、价格、……),"订单编号"为主键,"产品编号"和主键列没有直接的关系,即"产品编号"列不依赖于主键列,应删除该列。
第三范式:在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关.
如果一个关系满足第二范式,并且除了主键以外的其它列都不依赖于主键列,则满足第三范式.
为了理解第三范式,需要根据Armstrong公里之一定义传递依赖。假设A、B和C是关系R的三个属性,如果A-〉B且B-〉C,则从这些函数依赖中,可以得出A-〉C,如上所述,依赖A-〉C是传递依赖。
例如:订单表(订单编号,定购日期,顾客编号,顾客姓名,……),初看该表没有问题,满足第二范式,每列都和主键列"订单编号"相关,再细看你会发现"顾客姓名"和"顾客编号"相关,"顾客编号"和"订单编号"又相关,最后经过传递依赖,"顾客姓名"也和"订单编号"相关。为了满足第三范式,应去掉"顾客姓名"列,放入客户表中。
2)单例模式的线程安全问题
如何创建单例模式?说了双重检查,他说不是线程安全的。如何高效的创建的一个高效的单例?
单例设计模式的延迟加载模式必须加入同步,因此降低了系统性能,为了解决该问题,可以作如下改进:
public class StaticSingleton{ private StaticSingleton(){ System.out.println("StaticSingleton is create"); } private static class SingletonHolder{ private static StaticSingleton instance = new StaticSingleton(); } public static StaticSingleton getInstance(){ return SingletonHolder.instance; } }
在该实现中,单例模式使用内部类来维护单例的实例,当StaticSingleton被加载时,其内部类并不会被初始化,故可以确保当StaticSingleton类被载入JVM时,不会初始化单例类,而当调用getInstance()方法时,才会加载StaticSingleton,从而初始化instance,同时,由于实例的建立是在类加载时完成,故天生对线程友好,getInstance()方法也不需要使用同步关键字。因此,该实现方式同时兼备延迟加载和非延迟加载的优点。
注意:序列化和反序列化可能会破坏单例,一般来说,对单例进行序列化和反序列化的场景并不多见,但如果存在,就要多加注意。
六大原则:
开闭原则、里氏代换原则、依赖倒转原则、接口隔离原则、最少知道原则、合成复用原则。
6.1 Spring
1)Bean的加载过程
2)Spring IOC概念和原理
(1)【第三章】 DI 之 3.3 更多DI的知识 ——跟我学spring3 地址:http://si shuo k.com/forum/blogPost/list/2453.html
(2)spring如何不需要配置文件加载bean定义
使用自动注入。可按bean名称或者bean类型自动注入。
3)AOP
(1)spring aop 用了什么设计原则,自动注入配置是做什么用的。
面向切面编程,代理模式。
(2)Spring AOP嵌套调用的问题
Spring AOP嵌套调用的问题 (同一类方法内调用切面切不到)
Spring事务处理时自我调用的解决方案及一些实现方式的风险
4)Spring 事务
参考:
(1)Spring事务的实现原理
Spring事务的本质其实就是数据库对事务的支持,没有数据库的事务支持,spring是无法提供事务功能的。
(2)Spring 几种事务传播特性
(3)注解式事务和编程式事务的区别
参考:
通过 Spring 提供的事务管理 API,我们可以在代码中灵活控制事务的执行。在底层,Spring 仍然将事务操作委托给底层的持久化框架来执行。
Spring 的声明式事务管理在底层是建立在 AOP 的基础之上的。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
声明式事务最大的优点就是不需要通过编程的方式管理事务,这样就不需要在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过等价的基于标注的方式),便可以将事务规则应用到业务逻辑中。因为事务管理本身就是一个典型的横切逻辑,正是 AOP 的用武之地。Spring 开发团队也意识到了这一点,为声明式事务提供了简单而强大的支持。
基于 <tx> 命名空间和基于 @Transactional 的事务声明方式各有优缺点。基于 <tx> 的方式,其优点是与切点表达式结合,功能强大。利用切点表达式,一个配置可以匹配多个方法,而基于 @Transactional 的方式必须在每一个需要使用事务的方法或者类上用 @Transactional 标注,尽管可能大多数事务的规则是一致的,但是对 @Transactional 而言,也无法重用,必须逐个指定。另一方面,基于 @Transactional 的方式使用起来非常简单明了,没有学习成本。开发人员可以根据需要,任选其中一种使用,甚至也可以根据需要混合使用这两种方式。
声明式的事务的做法是在a方法外围添加注解或者直接在配置文件中定义,a方法需要事务处理,在spring中会通过配置文件在a方法前后拦截,并添加事务.
二者区别.编程式事务侵入性比较强,但处理粒度更细.
6.2 MyBatis
1)ibatis in操作以及一个属性的作用
6.3 Servlet/Filter/SpringMVC
1)servlet/filter作用原理配置
2)servlet生命周期
Servlet的生命周期是由Servlet的容器来控制的,它可以分为3个阶段;初始化,运行,销毁。
初始化阶段:
(1)Servlet容器加载servlet类,把servlet类的.class文件中的数据读到内存中。
(2)然后Servlet容器创建一个ServletConfig对象。ServletConfig对象包含了Servlet的初始化配置信息。
(3)Servlet容器创建一个servlet对象。
(4)Servlet容器调用servlet对象的init方法进行初始化。
运行阶段:
当servlet容器接收到一个请求时,servlet容器会针对这个请求创建servletRequest和servletResponse对象。
然后调用service方法。并把这两个参数传递给service方法。Service方法通过servletRequest对象获得请求的信息。并处理该请求。再通过servletResponse对象生成这个请求的响应结果。然后销毁servletRequest和servletResponse对象。我们不管这个请求是post提交的还是get提交的,最终这个请求都会由service方法来处理。
销毁阶段:
当Web应用被终止时,servlet容器会先调用servlet对象的destrory方法,然后再销毁servlet对象,同时也会销毁与servlet对象相关联的servletConfig对象。我们可以在destroy方法的实现中,释放servlet所占用的资源,如关闭数据库连接,关闭文件输入输出流等。
在这里该注意的地方:
在servlet生命周期中,servlet的初始化和和销毁阶段只会发生一次,而service方法执行的次数则取决于servlet被客户端访问的次数。
3)springmvc 源码了解
6.4 Session
1)session共享机制
2)session 原理
3)分布式集群怎么做session
6.5 HTTP协议
1)http协议,返回码,301与302区别
2)http 1.0 1.1版本的区别
3)怎么解决跨域访问
出于安全考虑,HTML的同源策略不允许JavaScript进行跨域操作, 直接发送跨域 AJAX 会得到如下错误。
解决跨域访问的方法:
(1)一类是Hack,比如通过title, navigation等对象传递信息,JSONP可以说是一个最优秀的Hack。
(2)另一类是HTML5支持,一个是Access-Control-Allow-Origin响应头,一个是window.postMessage
(3)跨域资源共享(CORS)
- 原理:服务器设置
Access-Control-Allow-OriginHTTP响应头之后,浏览器将会允许跨域请求 - 限制:浏览器需要支持HTML5,可以支持POST,PUT等方法
6.6 TCP/IP协议
1)TCP如何保证可靠传输?三次握手过程?
TCP用三次握手和滑动窗口机制来保证传输的可靠性和进行流量控制。
第一次握手:
客户端发送一个TCP的SYN标志位置1的包指明客户打算连接的服务器的端口,以及初始序号X,保存在包头的序列号(Sequence Number)字段里。
第二次握手:
服务器发回确认包(ACK)应答。即SYN标志位和ACK标志位均为1同时,将确认序号(Acknowledgement Number)设置为客户的I S N加1以.即X+1。
第三次握手.
客户端再次发送确认包(ACK) SYN标志位为0,ACK标志位为1.并且把服务器发来ACK的序号字段+1,放在确定字段中发送给对方.并且在数据段放写ISN的+1
2)TCP和UDP区别?
TCP---传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP---用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快
3)滑动窗口算法?
我们可以大概看一下上图的模型:
1. 首先是AB之间三次握手建立TCP连接。在报文的交互过程中,A将自己的缓冲区大小(窗口大小)3发送给B,B同理,这样双方就知道了对端的窗口大小。
2. A开始发送数据,A连续发送3个单位的数据,因为他知道B的缓冲区大小。在这一波数据发送完后,A就不能再发了,需等待B的确认。
3. A发送过来的数据逐渐将缓冲区填满。
4. 这时候缓冲区中的一个报文被进程读取,缓冲区有了一个空位,于是B向A发送一个ACK,这个报文中指示窗口大小为1。
A收到B发过来的ACK消息,并且知道B将窗口大小调整为1,因此他只发送了一个单位的数据并且等待B的下一个确认报文。
5. 如此反复。
6.7 应用服务器
1)谈谈你最熟悉的应用服务器
2)Tomcat的配置
6.8 操作系统
1)进程间通信有哪几种方式?
# 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
# 有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
# 信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
# 消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
# 信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
# 共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
# 套接字( socket ) : 套接字也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
7. 测试
1)做过应用相关性能测试的,举个例子,实际项目中怎么使用的。
Dubbo是一个分布式服务框架,提供高性能和透明化的RPC远程服务调用方案
节点角色说明:
Provider: 暴露服务的服务提供方。
Consumer: 调用远程服务的服务消费方。
Registry: 服务注册与发现的注册中心。
Monitor: 统计服务的调用次调和调用时间的监控中心。
Container: 服务运行容器。
提供回滚接口、本地消息表、MQ(非事务消息)、MQ(事务消息)
8.6 分布式锁
参考:
8.8 负载均衡
1)nginx作用和在项目中的使用场景
2)负载均衡算法
8.9 大数据开发
1)了解hadoop吗?说说hadoop的组件有哪些?hdfs,hive,hbase,zookeeper。说下mapreduce编程模型。
9.3 多机房多站点
2)Linux系统是什么版本、内核,线上问题怎么排查
3)Linux下如何进行进程调度的?
在Linux中,进程的运行时间不可能超过分配给他们的时间片,他们采用的是抢占式多任务处理,所以进程之间的挂起和继续运行无需彼此之间的协作。
4种,临界区、互斥量、信号量、
 |
作者:沙漏哟 出处:计算机的未来在于连接 本文版权归作者和博客园共有,欢迎转载,请留下原文链接 微信随缘扩列,聊创业聊产品,偶尔搞搞技术 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号