2 安装Spark与Python练习
一、安装Spark
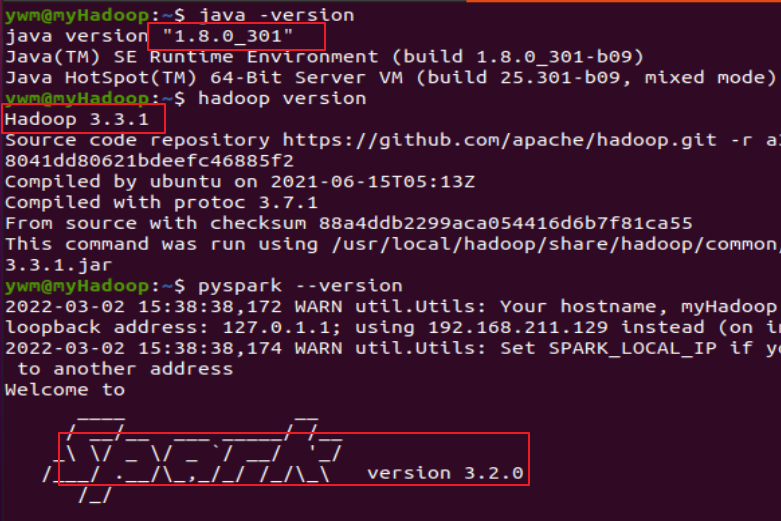
检查基础环境hadoop,jdk
下载spark
解压,文件夹重命名、权限
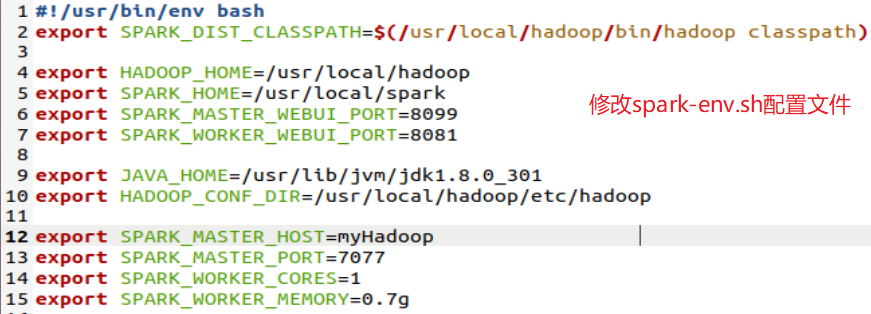
配置文件
环境变量
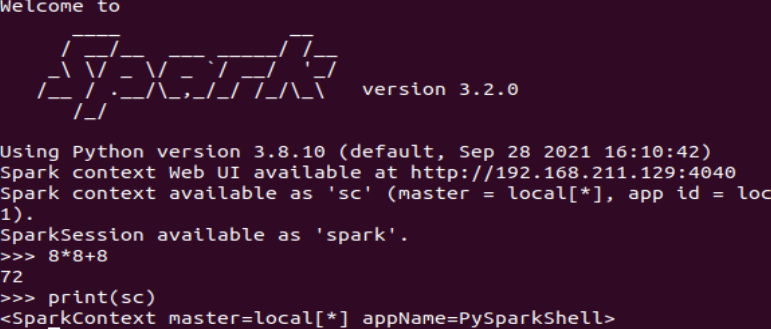
试运行Python代码
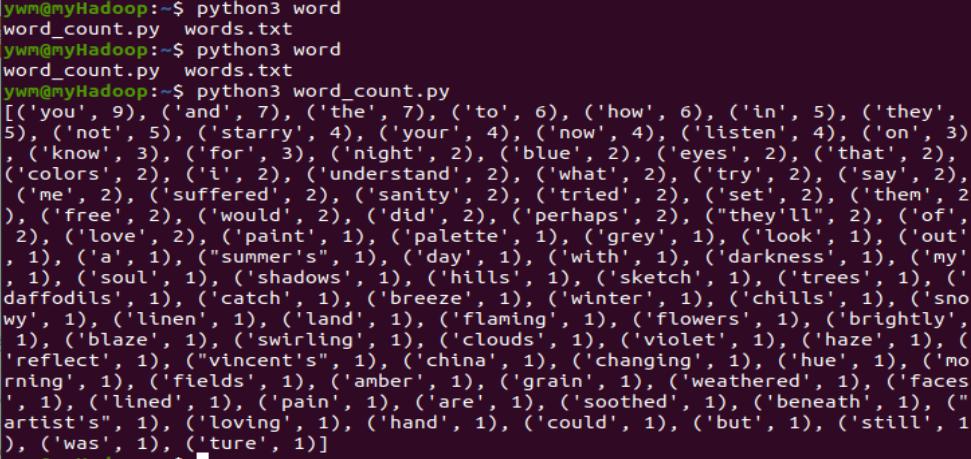
二、Python编程练习:英文文本的词频统计
准备文本文件
读文件
预处理:大小写,标点符号,停用词
分词
统计每个单词出现的次数
按词频大小排序
结果写文件
点击查看英文文本的词频统计代码
# 准备文本文件
path = 'C:/Users/Desktop/words.txt'
# 读文件
with open(path) as f:
text = f.read()
# 预处理:大小写,标点符号,分词 停用词
my_list = []
new_word = ''
no_use = [',', '.', '\n', '!', ' '] # 符号列表未列完.....
stop_word = [] # 自定义停用词
for ch in text.lower():
if ch in no_use:
if len(new_word) == 0 or new_word in stop_word:
continue
my_list.append(new_word)
new_word = ''
continue
new_word += ch
# 统计每个单词出现的次数
wc = {}
for word in my_list:
wc[word] = wc.get(word, 0) + 1
wc_list = list(wc.items())
# 按词频大小排序
wc_list.sort(key=lambda x: x[1], reverse=True)
# 简单打印一下
print(wc_list)
本文来自博客园,作者:是你,转载无需注明原文链接:https://www.cnblogs.com/ye092711/p/15956719.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号