
作业4
第四次作业
一、作业内容
作业①:
要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
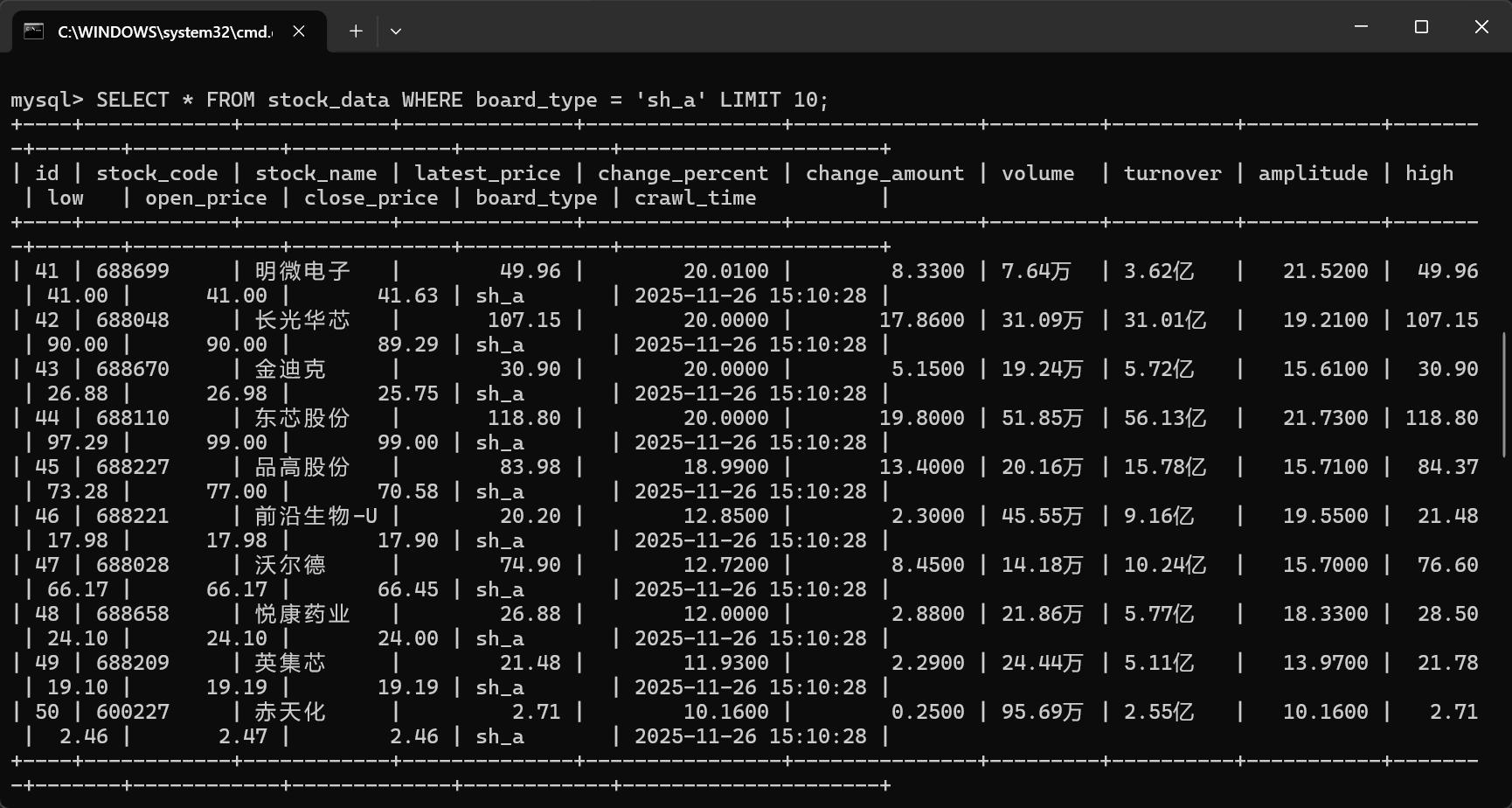
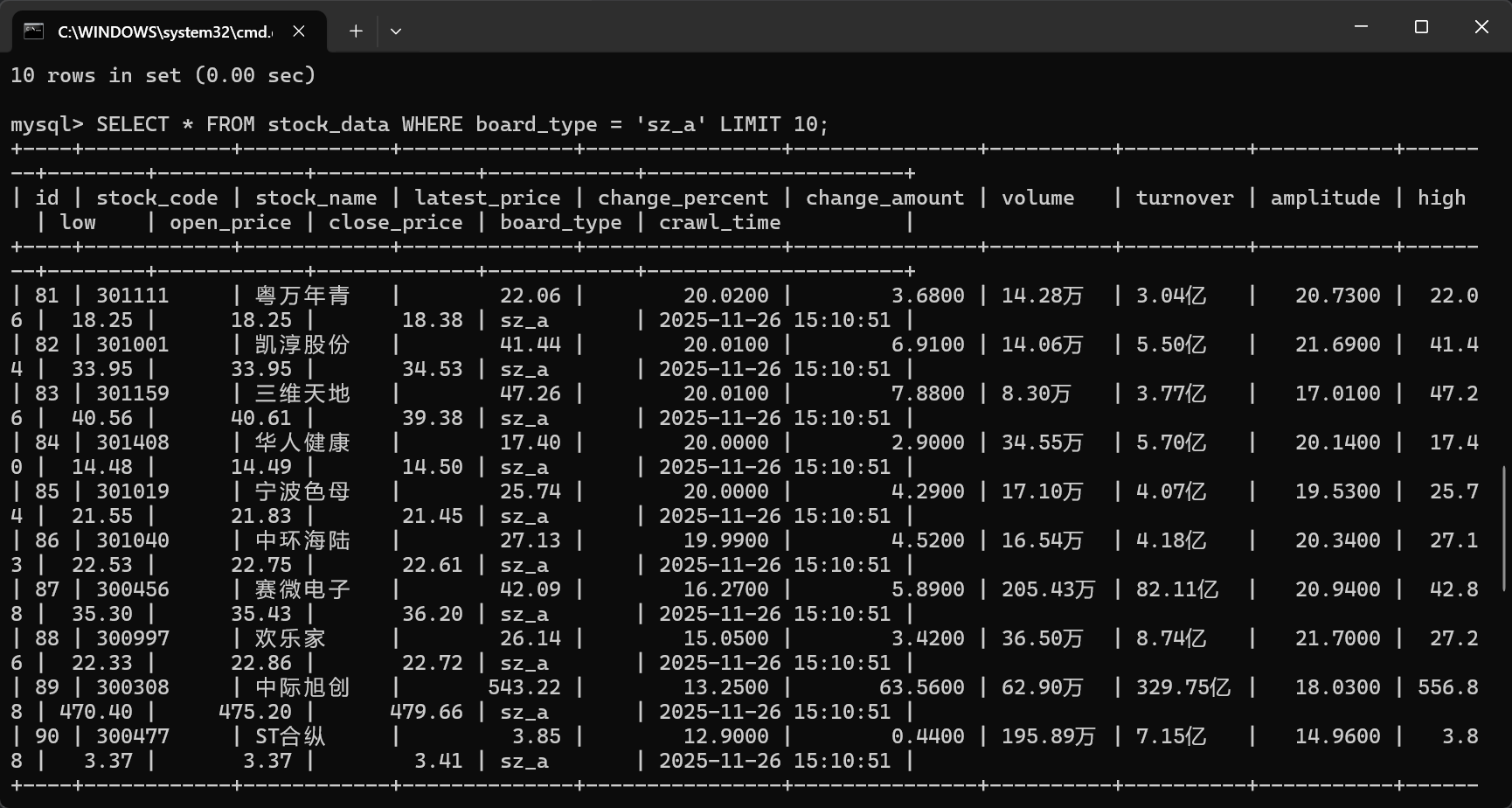
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
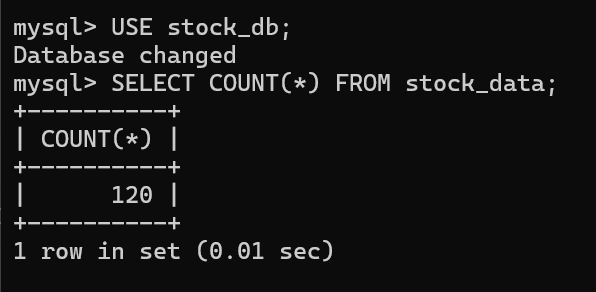
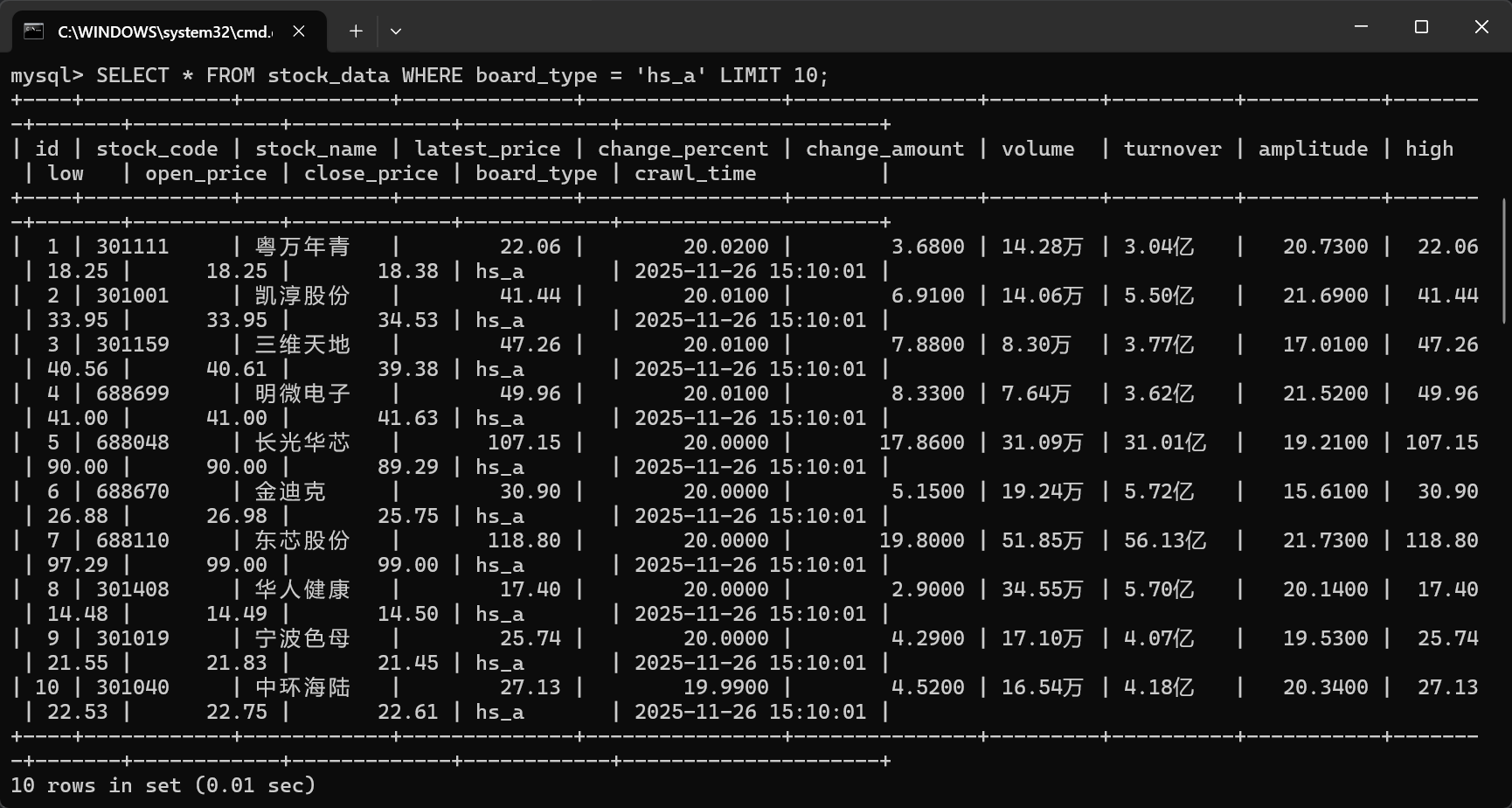
输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee 文件夹链接
查看作业4代码:作业4代码文件夹
核心代码
1、该网站的每个板块都是一个ajax网页,点击别的板块后url会改变
boards = {
'hs_a': 'https://quote.eastmoney.com/center/gridlist.html#hs_a_board',
'sh_a': 'https://quote.eastmoney.com/center/gridlist.html#sh_a_board',
'sz_a': 'https://quote.eastmoney.com/center/gridlist.html#sz_a_board'
}
2、观察网页信息
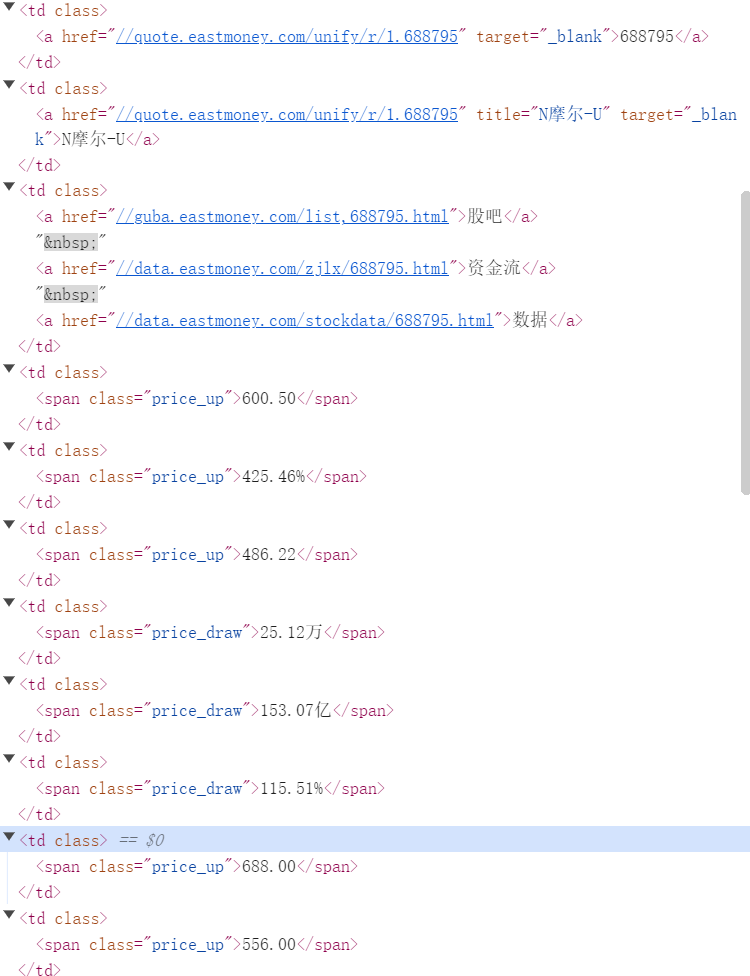
3、针对单个板块的ajax网站翻页爬取
stock_info = {
'stock_code': stock_code,
'stock_name': stock_name,
'latest_price': self.parse_price(cells[4].text if len(cells) > 4 else '0'),
'change_percent': self.parse_percent(cells[5].text if len(cells) > 5 else '0'),
'change_amount': self.parse_price(cells[6].text if len(cells) > 6 else '0'),
'volume': cells[7].text.strip() if len(cells) > 7 else '',
'turnover': cells[8].text.strip() if len(cells) > 8 else '',
'amplitude': self.parse_percent(cells[9].text if len(cells) > 9 else '0'),
'high': self.parse_price(cells[10].text if len(cells) > 10 else '0'),
'low': self.parse_price(cells[11].text if len(cells) > 11 else '0'),
'open_price': self.parse_price(cells[12].text if len(cells) > 12 else '0'),
'close_price': self.parse_price(cells[13].text if len(cells) > 13 else '0'),
'board_type': board_type
}
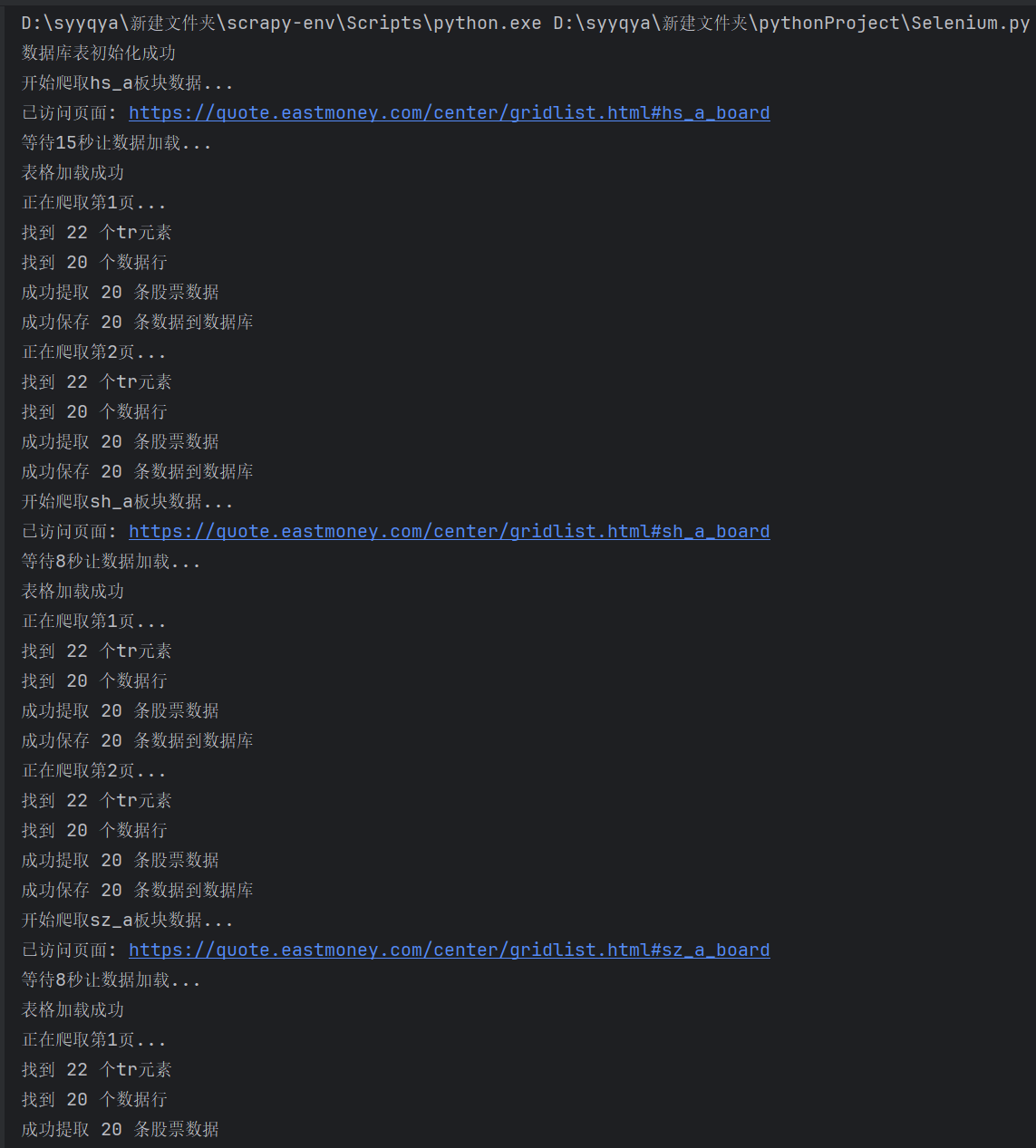
运行结果:

心得体会
一开始爬取的时候,会遇到页面还没加载完就开始爬取,导致没有爬取到数据。后面增加等待的时间,就解决了这个问题。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接
查看作业4代码:作业4代码文件夹
核心代码
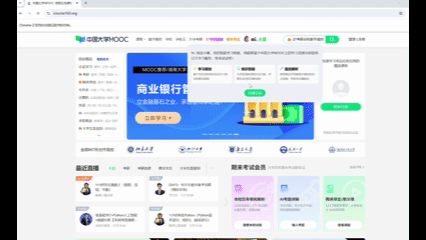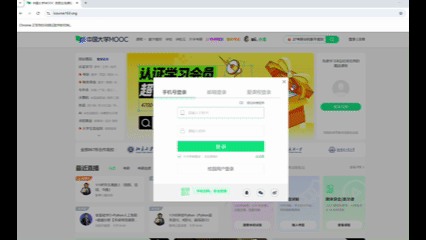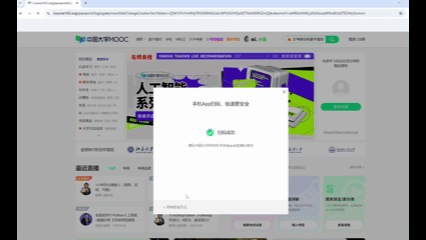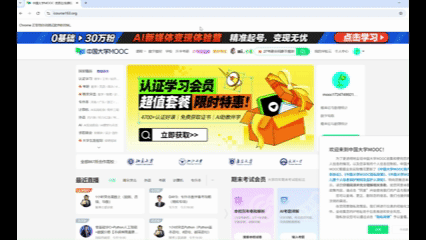
1、首先,要实现用户模拟登录。
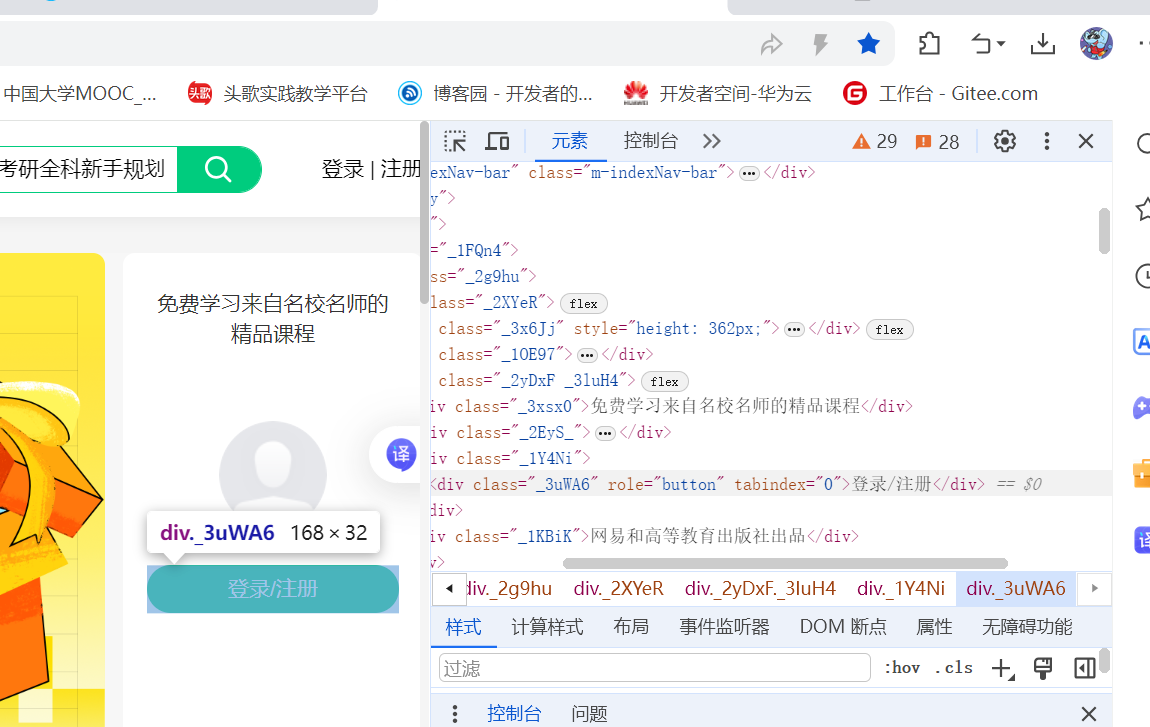
第一步,点击这个网页上的登录/注册键
根据页面信息,找到登录按钮class="_3uWA6"
第二步,采用扫码登录
def login():
try:
# 找到并点击 登录/注册 按钮(点击之后跳出输入弹窗)
login_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//div[@class="_3uWA6" and text()="登录/注册"]'))
)
login_button.click()
# 等待扫码登录
print("请扫码登录...")
time.sleep(30)
print("登录成功。")
return True
except Exception as e:
print(f"登录失败: {e}")
return False
效果如下
2、爬取课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度(因为教师团队、课程简介等都需要点击进入课程详情页才能查找到对应的元素,所以分开爬取)
首先,观察页面信息
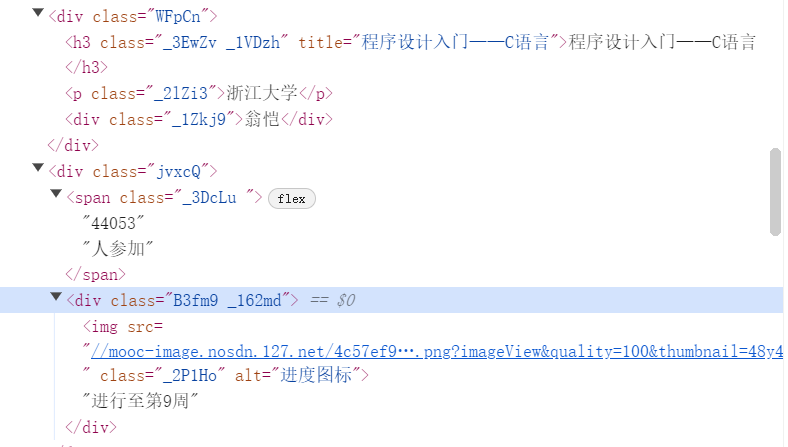
使用xpath爬取信息
cCourse = course.find_element(By.XPATH, './/h3').text # 课程名
cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text # 大学名称
cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text # 主讲老师
cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text # 参与该课程的人数
cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text # 课程进展
3、进入详情页后,爬取教师团队、课程简介
也是先观察页面信息
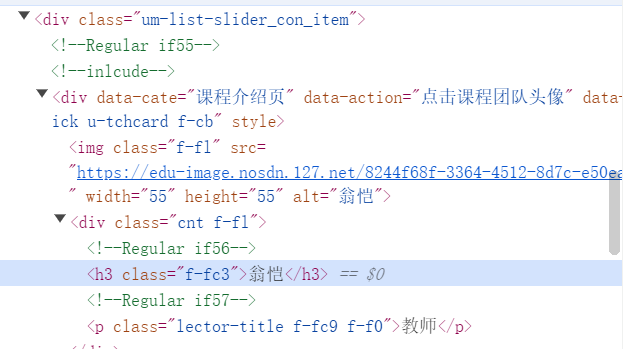

爬取教师团队信息
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
爬取课程简介
cBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
if len(cBrief) == 0:
cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*')
cBrief = ""
for c in cBriefs:
cBrief += c.text
运行结果
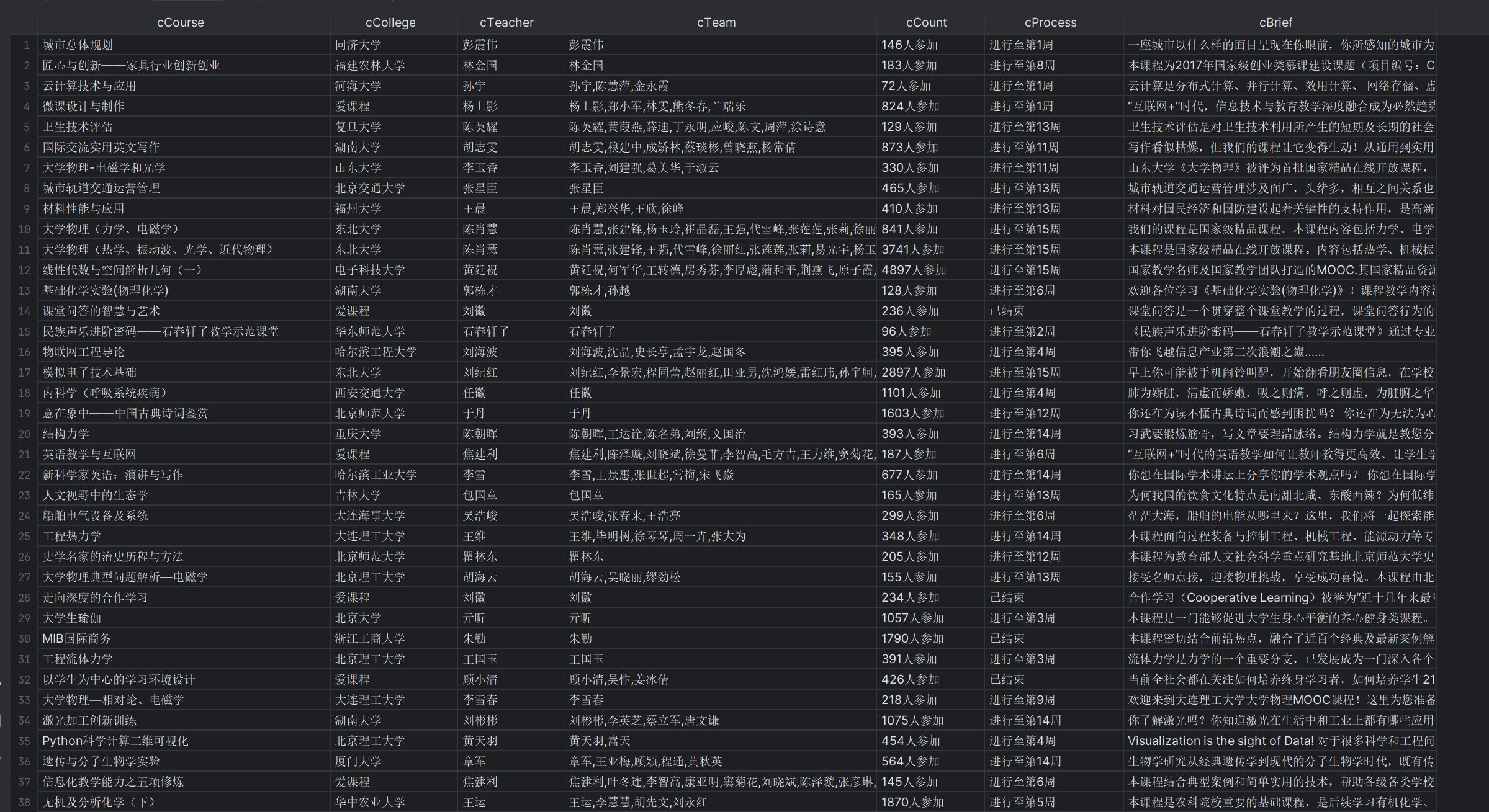
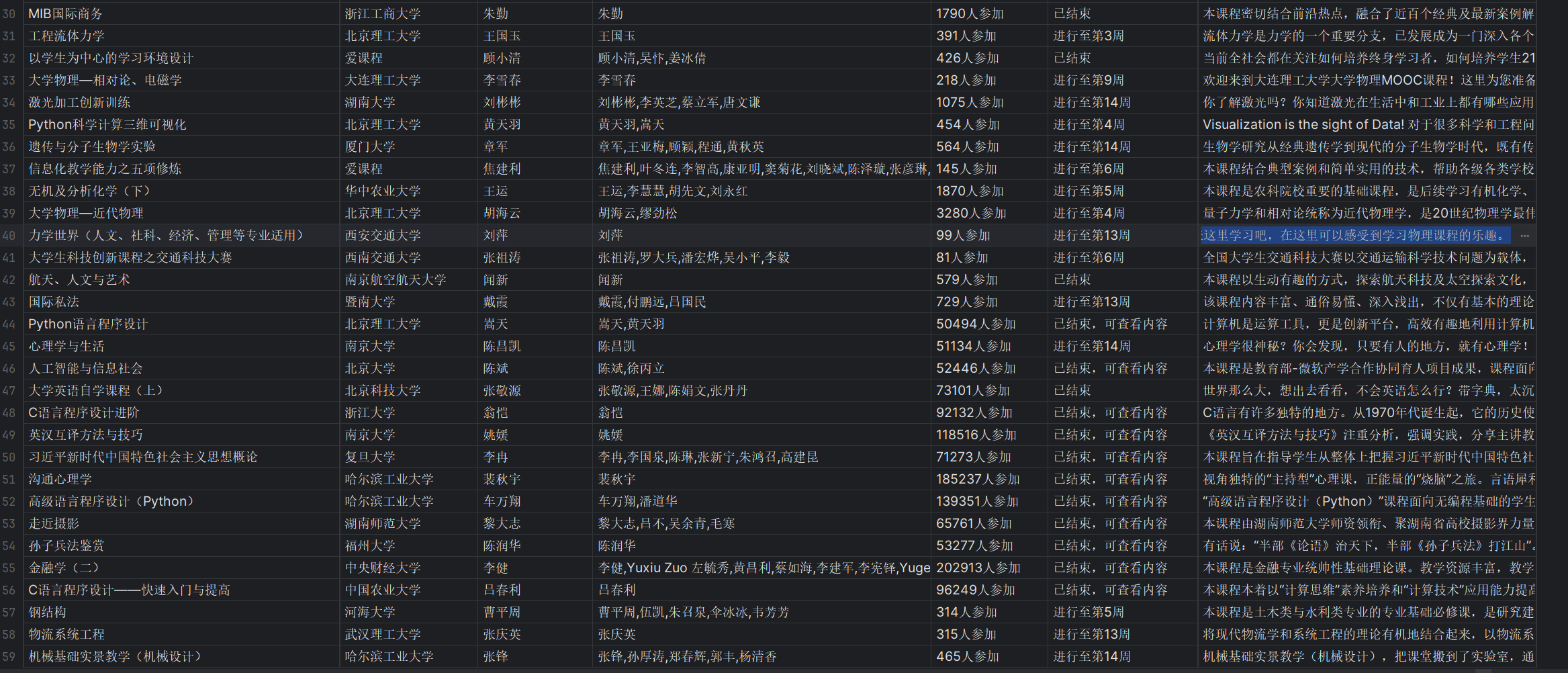
心得体会
学会了模拟登录,以及窗体切换。这道题和之前的不太一样,有些数据需要进入详情页才能爬取。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
输出:实验关键步骤或结果截图。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
Python脚本生成测试数据

执行脚本测试
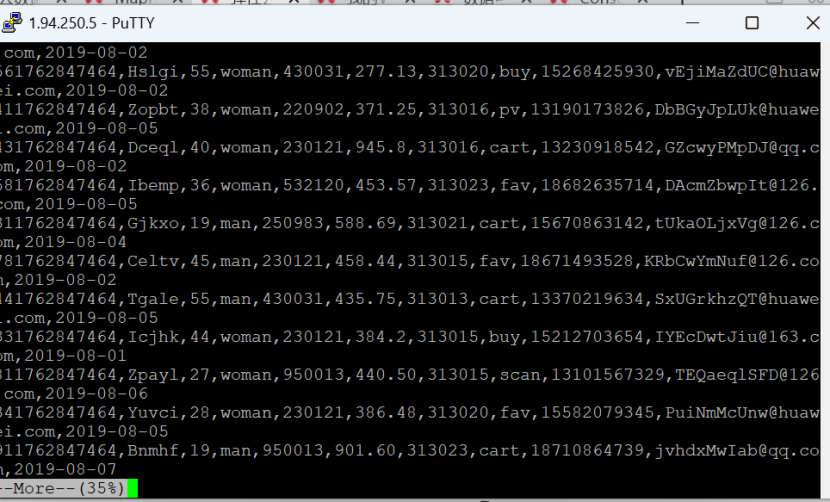
任务二:配置Kafka

任务三: 安装Flume客户端
下载Flume客户端

校验下载的客户端文件包

表明文件包校验成功

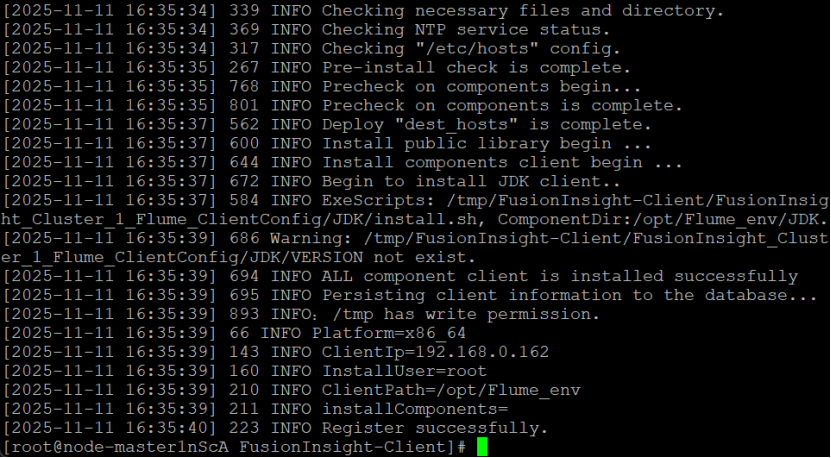
安装Flume运行环境
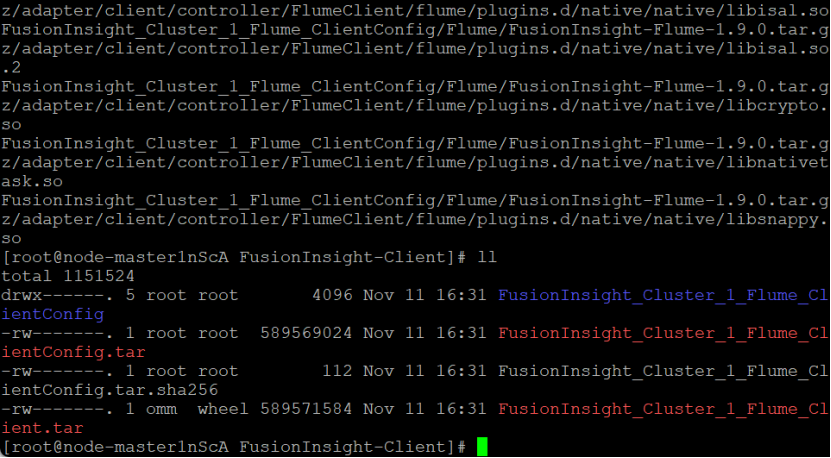
重启成功
任务四:配置Flume采集数据
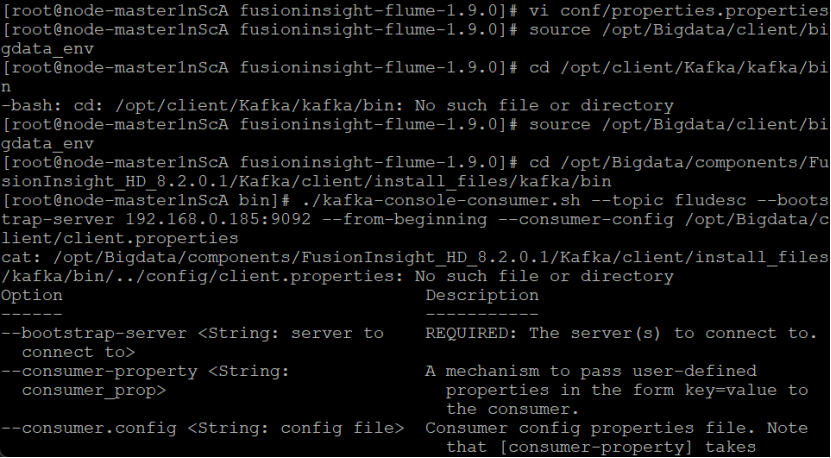
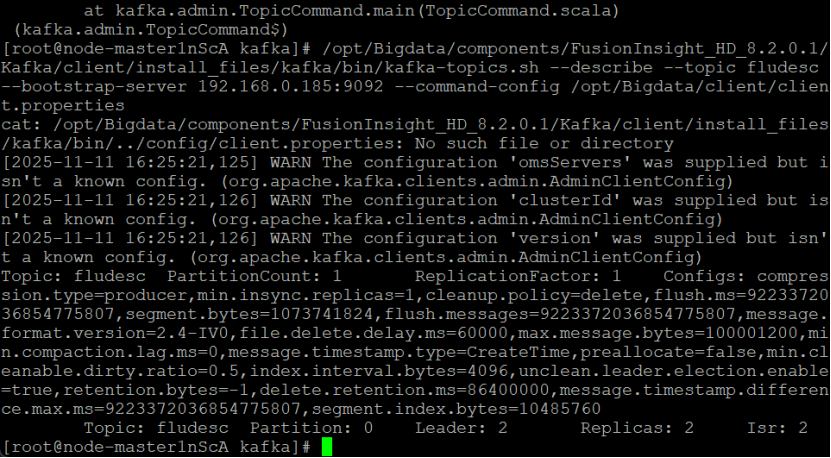
创建消费者消费kafka中的数据
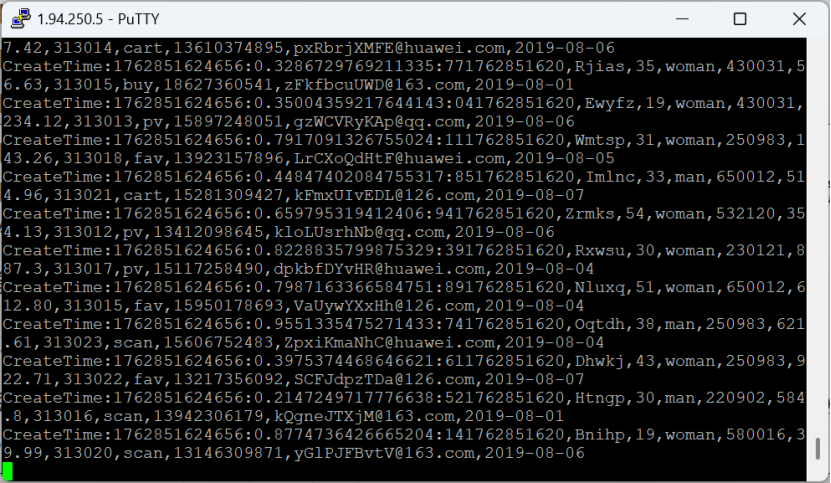
有数据产生,表明Flume到Kafka目前是打通的

心得体会
熟悉Flume 采集数据的方法,学会配置环境,提升了大数据问题定位和解决能力
实践证明,耐心调试和严谨态度是保障数据项目成功的关键要素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号