
爬取电影数据并保存至csv文件
url = 'https://ssr1.scrape.center/'
from parsel import Selector
import requests
import csv
import certifi
def get_page():
# 翻页1-10页
for i in range(1,11):
url = f'https://ssr1.scrape.center/page/{i}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36'
}
# 1.发送请求
response = requests.get(url,headers=headers,verify=certifi.where())
# print(response.text)
# 2.解析页面
selector = Selector(response.text)
# 3.获取所有div标签(根据class属性定位div标签),返回数据列表,列表里每一个元素都是selector对象
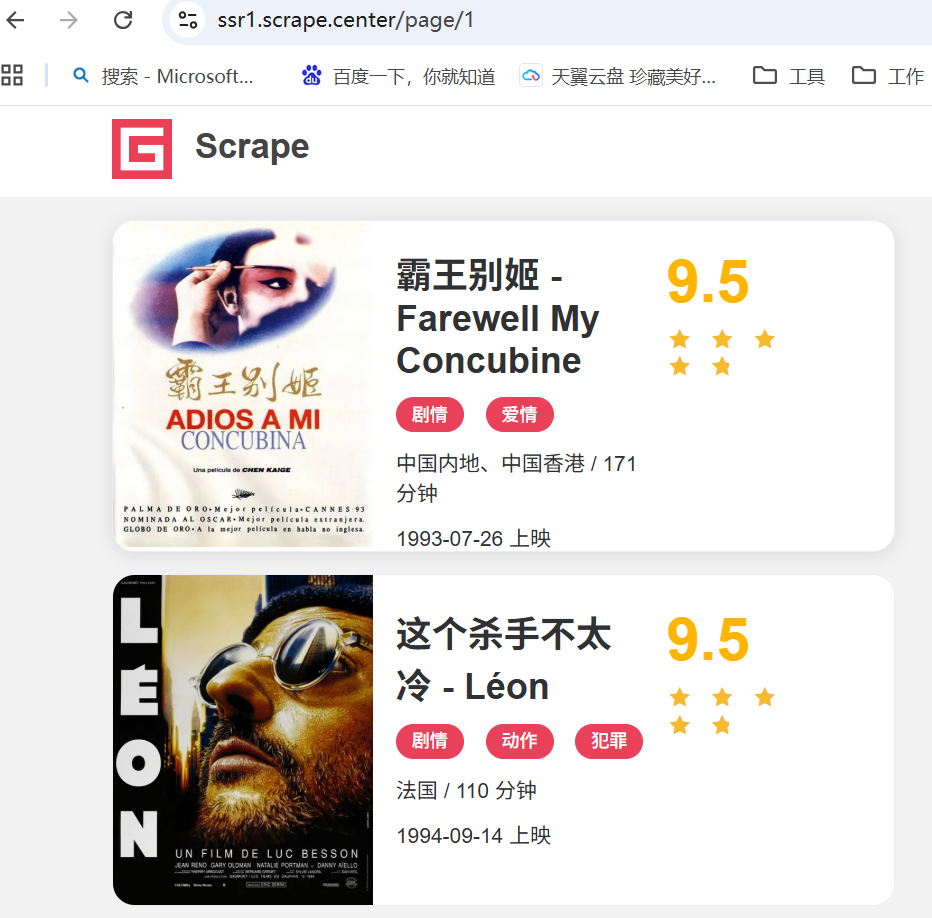
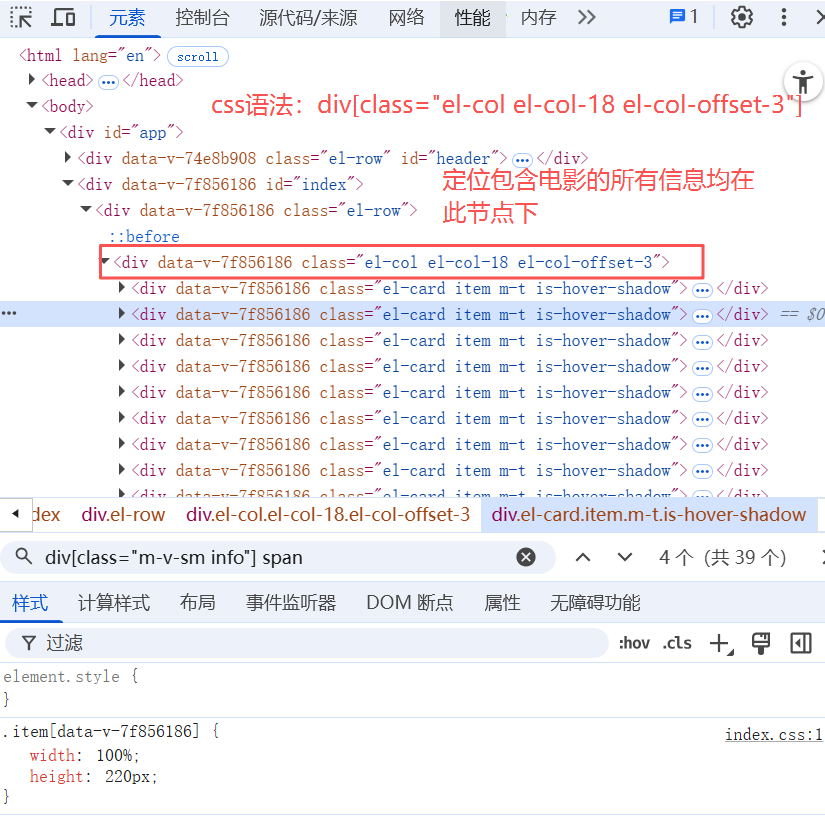
name_list = selector.css('div[class="el-card item m-t is-hover-shadow"]')
# print(name_list)
# exit()
for name in name_list:
title = name.css('h2[class="m-b-sm"]::text').get()
score = name.css('p[class="score m-t-md m-b-n-sm"]::text').get().strip()
type = name.css('button[type="button"] span::text').getall()
type_clean = "/".join(type)
area = name.css('div[class="m-v-sm info"] span::text').getall()[0]
year = name.css('div[class="m-v-sm info"] span::text').getall()[-1]
# print(f"{title} {score} {type}")
# break
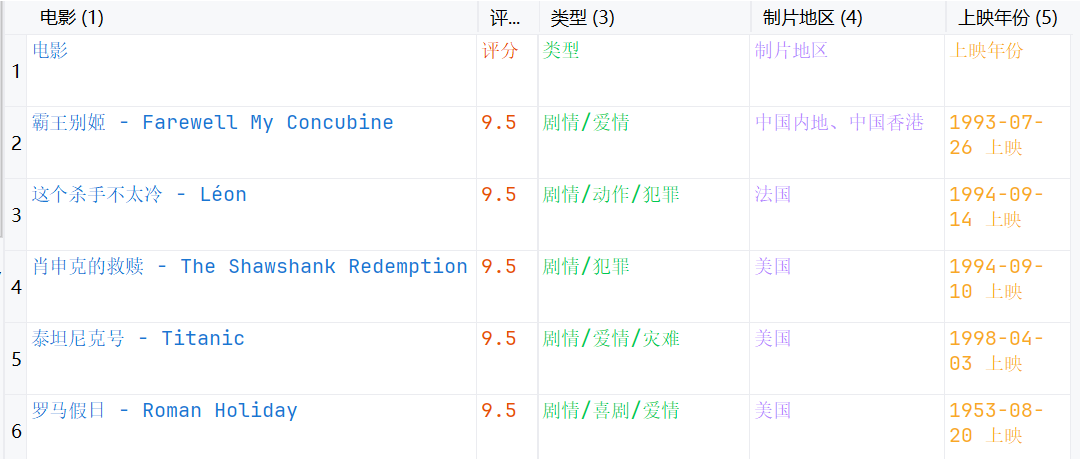
writer.writerow({"电影":title,"评分":score,"类型":type_clean,"制片地区":area,"上映年份":year})
def save_data():
fieldname = ["电影","评分","类型","制片地区","上映年份"]
global writer
with open("center_movie.csv","w",encoding='utf-8-sig',newline='') as f:
writer = csv.DictWriter(f,fieldname)
writer.writeheader() # 写入表头,省略会报错
get_page()
if __name__ == '__main__':
save_data()
"""
https://ssr1.scrape.center/page/1
https://ssr1.scrape.center/page/2
https://ssr1.scrape.center/page/3
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号