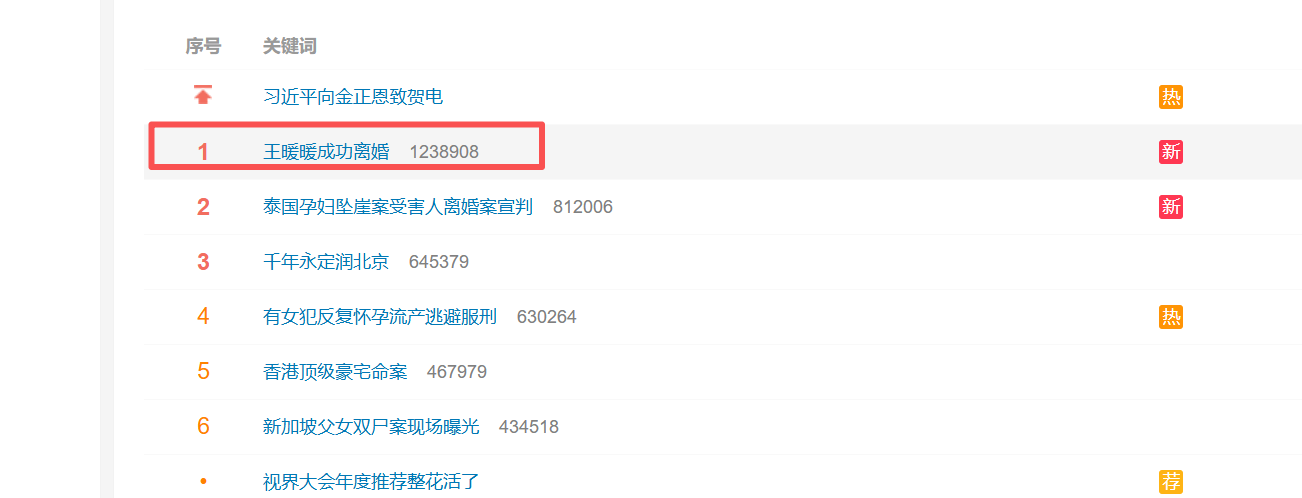
获取微博热搜榜top50
![image]()
# 获取微博热搜榜
import requests
from lxml import etree
url = "https://s.weibo.com/top/summary?cate=realtimehot&sudaref=s.weibo.com&display=0&retcode=6102"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36',
'cookie': 'SUB=_2AkMfuwuJf8NxqwFRmvwUyWrjb4h0zA3EieKp5_pSJRMxHRl-yT9yqmEstRB6NDslZjrICksrzHg7FjnxwgXaBx0S7mWG; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9Whenz85o-fiuaCWiTw4GPjM; _s_tentry=passport.weibo.com; Apache=4826852396222.754.1760003262911; SINAGLOBAL=4826852396222.754.1760003262911; ULV=1760003262922:1:1:1:4826852396222.754.1760003262911:'
}
response = requests.get(url,headers=headers)
response.encoding = "utf-8"
# print(response.text)
# 解析html文档
tree = etree.HTML(response.text)
# 定位微博热搜榜信息
contents = tree.xpath('//div[@class="m-wrap"]/div[1]/table/tbody/tr')
# 移除列表第0个元素,遍历列表取出数据
for content in contents[1:]:
rank = content.xpath('./td/text()')[0]
title = content.xpath('./td/a/text()')[0]
value = content.xpath('./td/span/text()')[0]
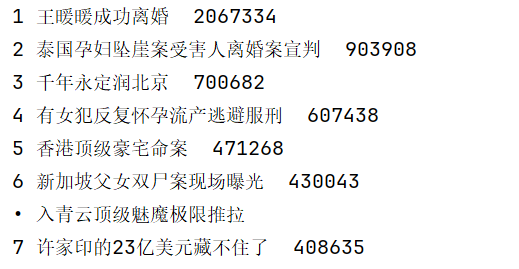
print(rank,title,value)
# 保存数据并写入文件
with open('weibo.txt',"a+",encoding="utf-8") as f:
f.write(f"{rank} {title}{value}\n")
![image]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号