爬虫:获取动态加载数据(selenium)(某站)
如果网站数据是动态加载,需要不停往下拉进度条才能显示数据,用selenium模拟浏览器下拉进度条可以实现动态数据的抓取。
本文希望找到某乎某话题下讨论较多的问题,以此再寻找每一问题涉及的话题关键词(侵删)。
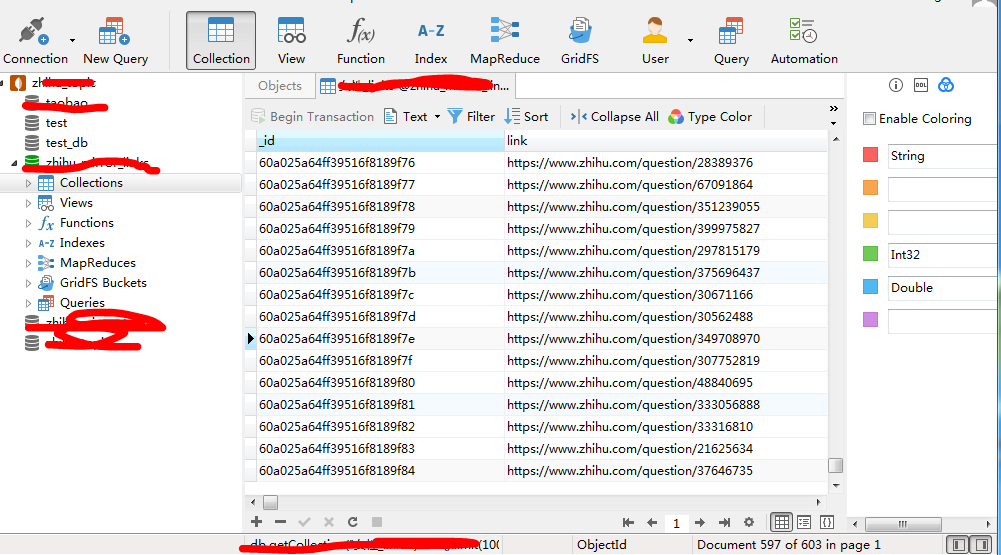
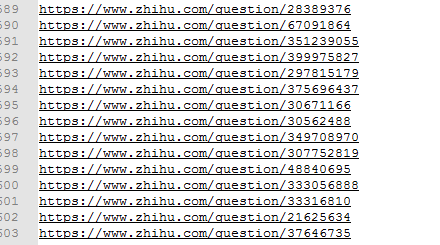
下面代码采用driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")模拟浏览器下拉进度条200次,获取了女性话题下近900多条回答,去重(同一话题下有重复问题)后得到600多个问题
from selenium.webdriver import Chrome from selenium.webdriver import ChromeOptions import time import random import re from pymongo import MongoClient client = MongoClient('localhost') db = client['test_db'] def get_links(url, word): option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) option.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"') driver = Chrome(options=option) time.sleep(10) driver.get('https://www.zhihu.com') time.sleep(10) driver.delete_all_cookies() # 清除刚才的cookie time.sleep(2) cookie = {} # 替换为自己的cookie driver.add_cookie(cookie) driver.get(url) time.sleep(random.uniform(10, 11)) for i in range(0, 200): driver.execute_script("window.scrollTo(0, document.body.scrollHeight)") time.sleep(random.uniform(3, 4)) links = driver.find_elements_by_css_selector('h2.ContentItem-title > div > a') print(len(links))
# 去重 regex = re.compile(r'https://www.zhihu.com/question/\d+') # 匹配问题而不是答案链接 links_set = set() for link in links: try: links_set.add(regex.search(link.get_attribute("href")).group()) except AttributeError: pass print(len(links_set)) with open(r'知乎镜像链接' + '/' + word + '-'.join(str(i) for i in list(time.localtime())[:5]) + '.txt', 'a') as f: for item in links_set: f.write(item + '\n') db[word + '_' + 'links'].insert_one({"link": item}) if __name__ == '__main__': input_word = input('输入话题:') input_link = input('输入话题对应链接url:') get_links(input_link, input_word)
截图如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号