splash渲染网页
#coding=utf8 import requests,time,random import threadpool render_html = 'http://192.168.30.128:8050/render.html' ##填写你的地址 url=’http://s.weibo.com/weibo/%25E8%25B5%25B5%25E9%259B%2585%25E8%258A%259D?topnav=1&wvr=6&b=1' headerx = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'} datax = {"url": url, "wait": 30, 'images': 0, 'timeout': 90 } #如果要使用代理ip加上这个 ,'proxy':pr} # ,'proxy': 'http://119.115.233.93:8118'} responsex=requests.get(url=render_html ,headers=headerx,params=datax) return responsex
splash 文档地址 http://splash.readthedocs.io/en/latest/scripting-tutorial.html
docker安装,自己百度。
装完docker后,运行
docker pull scrapinghub/spalsh
docker run -d -p 8050:8050 scrapinghub/spalsh
之后使用这个函数请求就可以得到渲染后的地址了。
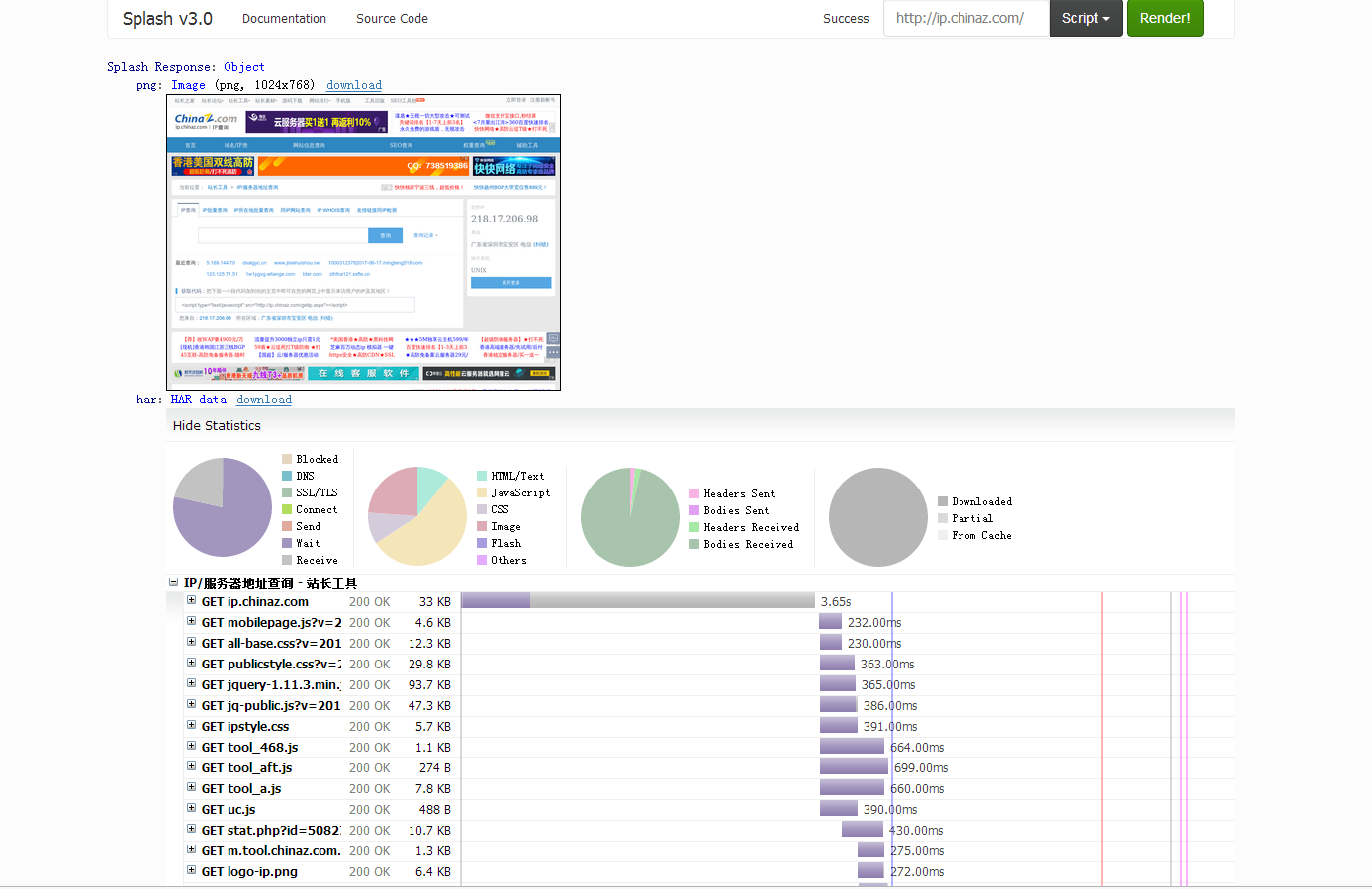
电脑打开,http://192.168.30.128:8050/render.html (换成你自己的ip),可以在这里面测试,例如打开chinaz首页。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号