rabbitmq 生产者 消费者(多个线程消费同一个队列里面的任务。) 一个通用rabbitmq消费确认,快速并发运行的框架。
rabbitmq作为消息队列可以有消息消费确认机制,之前写个基于redis的通用生产者 消费者 并发框架,redis的list结构可以简单充当消息队列,但不具备消费确认机制,随意关停程序,会丢失一部分正在程序中处理但还没执行完的消息。基于redis的与基于rabbitmq相比对消息消费速度和消息数量没有天然的支持。
使用rabbitmq的最常用库pika
不管是写代码还是运行起来都比celery使用更简单,基本能够满足绝大多数场景使用,用来取代celery worker模式(celery有三个模式,worker模式最常用,其余是定时和间隔时间两种模式)的后台异步的作用。
# coding=utf-8 """ 一个通用的rabbitmq生产者和消费者。使用多个线程消费同一个消息队列。 """ from collections import Callable import functools import time from threading import Lock from pika import BasicProperties # noinspection PyUnresolvedReferences from app.utils_ydf import (LoggerMixin, LogManager, decorators, RabbitMqHelper, BoundedThreadPoolExecutor) class RabbitmqPublisher(LoggerMixin): def __init__(self, queue_name, log_level_int=1): self._queue_name = queue_name self.logger.setLevel(log_level_int * 10) channel = RabbitMqHelper().creat_a_channel() channel.queue_declare(queue=queue_name, durable=True) self.channel = channel self.lock = Lock() self._current_time = None self.count_per_minute = None self._init_count() self.logger.info(f'{self.__class__} 被实例化了') def _init_count(self): self._current_time = time.time() self.count_per_minute = 0 def publish(self, msg): with self.lock: # 亲测pika多线程publish会出错。 self.channel.basic_publish(exchange='', routing_key=self._queue_name, body=msg, properties=BasicProperties( delivery_mode=2, # make message persistent ) ) self.logger.debug(f'放入 {msg} 到 {self._queue_name} 队列中') self.count_per_minute += 1 if time.time() - self._current_time > 60: self._init_count() self.logger.info(f'一分钟内推送了 {self.count_per_minute} 条消息到 {self.channel.connection} 中') class RabbitmqConsumer(LoggerMixin): def __init__(self, queue_name, consuming_function: Callable = None, threads_num=100, max_retry_times=3, log_level=1, is_print_detail_exception=True): """ :param queue_name: :param consuming_function: 处理消息的函数,函数有且只能有一个参数,参数表示消息。是为了简单,放弃策略和模板来强制参数。 :param threads_num: :param max_retry_times: :param log_level: :param is_print_detail_exception: """ self._queue_name = queue_name self.consuming_function = consuming_function self.threadpool = BoundedThreadPoolExecutor(threads_num) self._max_retry_times = max_retry_times self.logger.setLevel(log_level * 10) self.logger.info(f'{self.__class__} 被实例化') self._is_print_detail_exception = is_print_detail_exception self.rabbitmq_helper = RabbitMqHelper(heartbeat_interval=30) channel = self.rabbitmq_helper.creat_a_channel() channel.queue_declare(queue=self._queue_name, durable=True) channel.basic_qos(prefetch_count=threads_num) self.channel = channel LogManager('pika.heartbeat').get_logger_and_add_handlers(1) @decorators.keep_circulating(1) # 是为了保证无论rabbitmq异常中断多久,无需重启程序就能保证恢复后,程序正常。 def start_consuming_message(self): def callback(ch, method, properties, body): msg = body.decode() self.logger.debug(f'从rabbitmq取出的消息是: {msg}') # ch.basic_ack(delivery_tag=method.delivery_tag) self.threadpool.submit(self.__consuming_function, ch, method, properties, msg) self.channel.basic_consume(callback, queue=self._queue_name, # no_ack=True ) self.channel.start_consuming() @staticmethod def ack_message(channelx, delivery_tagx): """Note that `channel` must be the same pika channel instance via which the message being ACKed was retrieved (AMQP protocol constraint). """ if channelx.is_open: channelx.basic_ack(delivery_tagx) else: # Channel is already closed, so we can't ACK this message; # log and/or do something that makes sense for your app in this case. pass def __consuming_function(self, ch, method, properties, msg, current_retry_times=0): if current_retry_times < self._max_retry_times: # noinspection PyBroadException try: self.consuming_function(msg) # ch.basic_ack(delivery_tag=method.delivery_tag) self.rabbitmq_helper.connection.add_callback_threadsafe(functools.partial(self.ack_message, ch, method.delivery_tag)) except Exception as e: self.logger.error(f'函数 {self.consuming_function} 第{current_retry_times+1}次发生错误,\n 原因是{e}', exc_info=self._is_print_detail_exception) self.__consuming_function(ch, method, properties, msg, current_retry_times + 1) else: self.logger.critical(f'达到最大重试次数 {self._max_retry_times} 后,仍然失败') # ch.basic_ack(delivery_tag=method.delivery_tag) self.rabbitmq_helper.connection.add_callback_threadsafe(functools.partial(self.ack_message, ch, method.delivery_tag)) if __name__ == '__main__': rabbitmq_publisher = RabbitmqPublisher('queue_test') [rabbitmq_publisher.publish(str(i)) for i in range(1000)] def f(msg): print('.... ', msg) time.sleep(10) # 模拟做某事需要10秒种。 rabbitmq_consumer = RabbitmqConsumer('queue_test', consuming_function=f, threads_num=20) rabbitmq_consumer.start_consuming_message()
1、放入任务 (图片鼠标右键点击新标签打开查看原图)
 /2、
/2、
2、开启消费者,写一个函数传给消费者类。
3、并发运行效果。
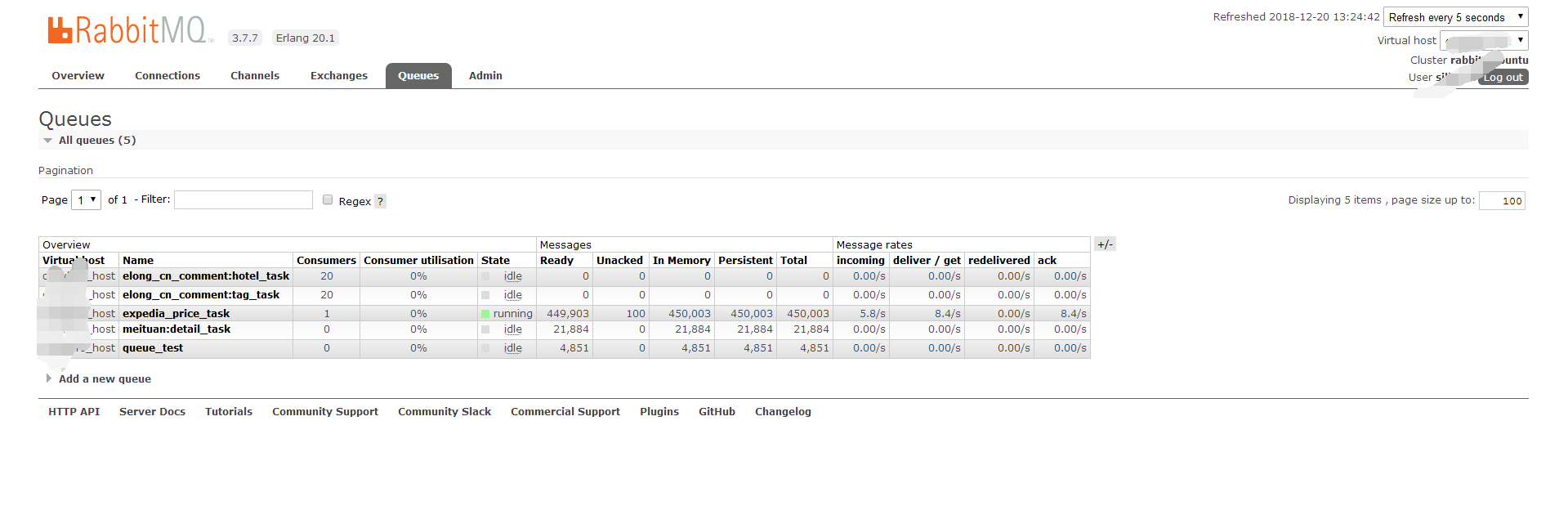
rabbitmq这个专业的消息中间件就是比redis作为消息中间件专业了很多。
反对极端面向过程编程思维方式,喜欢面向对象和设计模式的解读,喜欢对比极端面向过程编程和oop编程消耗代码代码行数的区别和原因。致力于使用oop和36种设计模式写出最高可复用的框架级代码和使用最少的代码行数完成任务,致力于使用oop和设计模式来使部分代码减少90%行,使绝大部分py文件最低减少50%-80%行的写法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号