数据库三大范式
范式是为了设计出合理的关系型数据库,越高的范式数据库冗余越小。
1. 第一范式(1NF)
列不可再分,所有的域都是原子性的

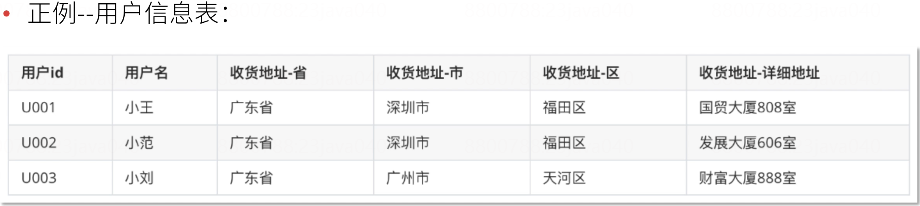
2. 第二范式(2NF)
满足1NF,表中的字段必须完全依赖于全部主键而非部分主键
例如,字段 x 和字段 y 确定唯一 一行数据,那么字段 z 必须依赖 x+y,不能只依赖 x,或者只依赖 y,即不能是部分依赖。
设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K(这个“完全”不要漏了),那么我们称 K 为候选码,简称为码。在实际中我们通常可以理解为:假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。
包含在任何一个码中的属性成为主属性,除去所有的主属性,剩下的就都是非主属性了。

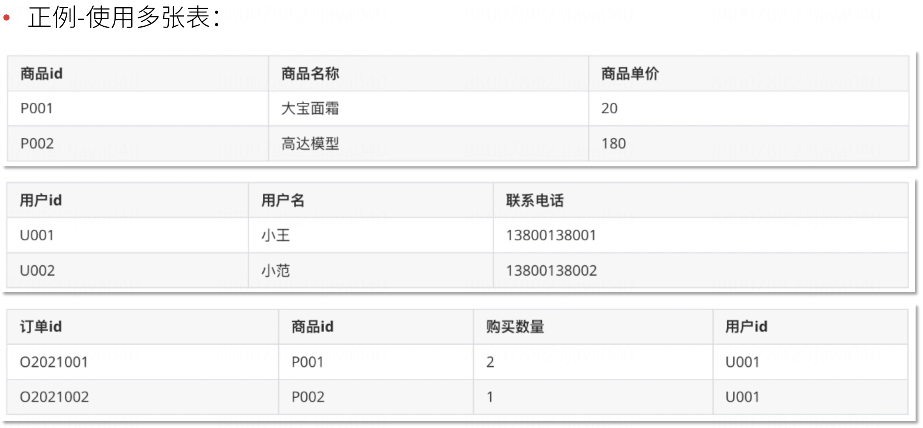
3. 第三范式(3NF)
满足2NF,非主键外的所有字段必须互不依赖,每列数据都与主键直接相关
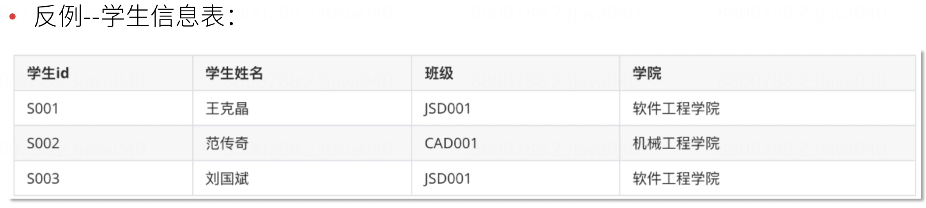
在现实中,各“班级”都是归属于“学院”的,即:只要班级是“JSDO01”,学院就一定是“软件工程学院”,所以,“学院”依赖于“班级”,形成“非主属性”依赖于另一个“非主属性”的情况,不符合第三范式的要求。
基于“消除传递依赖”的思想,应该将以上表中的“学院”删除,另创建其它表记录“班级”和“学院”的关系。
4. 引申
遵循范式,是为了减少冗余,但是展示全部数据会降低查询性能,因为需要关联查询。
所以推荐适当冗余。


