2026“钉耙编程”中国大学生算法设计春季联赛(2)题解
2026“钉耙编程”中国大学生算法设计春季联赛(2)题解
有点写不动了,先写题解吧。
Problem 1001. 湖上午后
题目描述
以二进制形式给出两个非负整数 \(s\) 和 \(t\),请求出方程 \(a \times b = (a \text{ or } b) \times (a \text{ and } b)\) 在 \(a\) 和 \(b\) 都取 \([s, t]\) 中的整数时,共有几组解。
其中,or 表示按位或,and 表示按位与。
答案对 998244353 取模。
Input
输入的第一行包含一个整数 \(Q\) (\(1 \le Q \le 20\)),表示测试用例的数量。
接下来是 \(Q\) 个测试用例的描述。
每个测试用例,共一行,包含两个 01 字符串 \(S\) 和 \(T\)(字符串 \(S\) 和 \(T\) 的长度 \(|S|\) 和 \(|T|\) 有 \(1 \le |S|, |T| \le 5 \times 10^5\)),分别表示 \(s\) 和 \(t\) 的二进制形式。保证给定的 \(s\) 和 \(t\) 的二进制形式无前导零,且 \(s \le t\)。
Output
对于每个测试用例,输出一行,包含一个非负整数,表示答案对 998244353 取模的值。
首先我们要知道个一个事情:\(a + b = (a \ or\ b) + (a \ and\ b)\)。这个其实还是比较好算的,用冗斥原理比较好理解:\((a \ or\ b) = (a + b) - (a\ and\ b)\)。
根据题目给出的原式就有:\((a+b) = (a \ or\ b) + (a \ and\ b), (a\times b) = (a \ or\ b) \times (a \ and\ b)\)。根据高中数学可以知道:
因为可以构造二次方程:\(x^2-(a+b)x+ab=0, x^2-(c+d)x+cd=0\),容易发现这是同解方程,所以就能得到这个条件。
于是原题可以得到条件 \((a + b) = (a\ or\ b) + (a\ and\ b)\)。这个等式成立当且仅当其中一个二进制下是另外一个二进制的子集。为了方便讨论,不妨令 \(a\) 是 \(b\) 的子集。
容易计数 \(a=b\) 的情况,于是可以通过两倍再减去重复的情况得到答案。
此时问题变成了:我们需要统计 \([s, t]\) 范围内,有多少对 \((a, b)\) 满足这个条件。
常规的数位 DP 会考虑做差。比如参照经典的 P2602 就是利用做差来计算。但是这个题里你考虑做差其实会很麻烦。
不妨直接将限制写进状态:记录 \(dp[p][i][j]\),为不包括 \(p\) 的前缀,是否和 \(s\) 一致,是否和 \(t\) 一致的方案数。
这个状态设计其实比较抽象,但是数位 dp 写的比较多,如果见过这种设计还是比较好理解的。可以结合 gemini 来理解一下。
#include <iostream>
#include <vector>
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
const int MOD = 998244353;
struct modint {
int val;
modint(long long v = 0) {
if (v < 0) v = v % MOD + MOD;
if (v >= MOD) v %= MOD;
val = (int)v;
}
explicit operator int() const { return val; }
friend modint qpow(modint a, long long p) {
modint ans(1);
while (p > 0) {
if (p & 1) ans *= a;
a *= a, p >>= 1;
}
return ans;
}
modint inv() const { return qpow(*this, MOD - 2); }
modint& operator+=(modint b) {
val += b.val;
if (val >= MOD) val -= MOD;
return *this;
}
modint& operator-=(modint b) {
val -= b.val;
if (val < 0) val += MOD;
return *this;
}
modint& operator*=(modint b) {
val = (int)(1LL * val * b.val % MOD);
return *this;
}
modint& operator/=(modint b) { return *this *= b.inv(); }
friend modint operator+(modint a, modint b) { return a += b; }
friend modint operator-(modint a, modint b) { return a -= b; }
friend modint operator*(modint a, modint b) { return a *= b; }
friend modint operator/(modint a, modint b) { return a /= b; }
};
void solve() {
std::string s, t;
cin >> s >> t;
std::string tmp(t.size() - s.size(), '0');
s = '0' + s, t = '0' + t;
using type = std::vector<std::vector<modint>>;
type dp(2, std::vector<modint>(2, 0));
s = tmp + s;
int len = s.size();
modint Snum = 0, Tnum = 0, ans = 0;
for (auto i : s) Snum = Snum * 2 + i - '0';
for (auto i : t) Tnum = Tnum * 2 + i - '0';
ans += Tnum - Snum + 1;
for (int i = 0; i <= 1; i++) {
for (int j = 0; j <= 1; j++) dp[i][j] = 1;
}
for (int p = len - 1; p >= 0; p--) {
type nxt(2, std::vector<modint>(2, 0));
int v1 = s[p] - '0', v2 = t[p] - '0';
for (int i = 0; i <= 1; i++) {
for (int j = 0; j <= 1; j++) {
for (int k = 0; k <= 3; k++) {
int cha = k & 1, chb = k >> 1;
if (cha > chb) continue;
int nxti = i, nxtj = j;
if (i) {
if (cha < v1) continue;
if (cha > v1) nxti = 0;
}
if (j) {
if (chb > v2) continue;
if (chb < v2) nxtj = 0;
}
nxt[i][j] += dp[nxti][nxtj];
}
}
}
dp = std::move(nxt);
}
// cerr << (int)dp[1][1] << endl;
ans = dp[1][1] * 2 - ans;
cout << (int)ans << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
事实上如果想要更好理解这种状态,可以试着用这种设计去写一下经典的数位 DP 题。
Problem 1002. 庭扫落樱
妖梦所在的庭院可以看作一个平面直角坐标系中的电子迷宫。这个电子迷宫中有 \(n\) 个位于第一象限的弹幕发射器,第 \(i\) 个弹幕发射器位于点 \(\left(x_i,y_i\right)\),且它会向上、下、左、右中的某一个方向发射激光。我们称一个点在一个弹幕发射器的照明路径上,当且仅当该点在以弹幕发射器为原点,向其照射方向画出的射线上(注意:弹幕发射器本身也在自己的照明路径上)。由于激光的功率很大,相互照射时会引发危险,因此,不会有任意两个弹幕发射器同时在对方的照明路径上。
为防止光污染,妖梦决定在电子迷宫中放置一些障碍物(可以放在弹幕发射器所在的位置),以防止激光照射到无穷远处。现在,妖梦想知道,至少需要放置多少个障碍物,才能使所有的弹幕发射器的照射路径上都至少有一个障碍物。
Input
输入的第一行包含一个整数 \(t\)(\(1\le t\le 100\)),表示测试用例的数量。
接下来是 \(t\) 个测试用例的描述。
每个测试用例的第一行包含一个整数 \(n\)(\(1\le n\le 300\)),表示弹幕发射器的数量。
接下来 \(n\) 行,第 \(i\) 行包含三个整数 \(x_i\),\(y_i\) 和 \(d_i\)(\(1\le x_i,y_i\le 10^9\),\(d_i\in \{0,1,2,3\}\)),表示第 \(i\) 个弹幕发射器的坐标是 \(\left(x_i,y_i\right)\),同时:
- 若 \(d_i = 0\),则表示该弹幕发射器向上发射激光;
- 若 \(d_i = 1\),则表示该弹幕发射器向右发射激光;
- 若 \(d_i = 2\),则表示该弹幕发射器向下发射激光;
- 若 \(d_i = 3\),则表示该弹幕发射器向左发射激光。
保证所有测试用例中 \(n\) 的总和不超过 \(3000\)。
一个不是那么典的二分图匹配。
我们可以先从激光的相交性质入手。很容易发现一个关键性质:互相平行的激光是不可能相交的。也就是说,只有垂直方向(上、下)的激光,和水平方向(左、右)的激光之间,才有可能产生交点。同时题目保证了“不会有任意两个发射器互相照射”,所以直接排除了共线对射的复杂情况。
如果一束垂直激光和一束水平激光有交点,我们在这个交点处放一个障碍物,就能同时挡住这两束激光。
但要注意,对于任意一束激光,虽然它可能和多束其他方向的激光都有交点,但只要它遇到了第一个障碍物,后续的光束就被截断了。这意味着在它参与的所有交点中,我们至多只能挑选一个交点来发挥“一石二鸟”的作用。
发现了吗?这个过程非常类似二分图匹配:
- 我们将所有的弹幕发射器分为两组作为二分图的左右部:垂直组(\(d_i = 0, 2\))和水平组(\(d_i = 1, 3\))。
- 遍历两组中的所有发射器,如果一束垂直激光和一束水平激光在照射方向上有交点,我们就在它们之间连一条边。
- 图中的每一条边(即一个有效交点),代表我们可以用 1 个障碍物同时搞定 2 个发射器。
不过值得注意的地方是,比如会有若干朝上的共线激光,这个时候你选定有意义的起点应该是 \(y\) 坐标最小的那个。原因不言自明。
为了让放置的障碍物最少,我们就需要尽可能多地利用这些交点。每多选一个不冲突的交点,就能“节省” 1 个障碍物。因此,最多能节省的障碍物数量,完全等价于这棵二分图的最大匹配数。
得出最终结论:至少需要放置的障碍物数量 = 总发射器数量 \(n\) - 二分图最大匹配数。
建好图之后,跑二分图最大匹配就可以了。当然,直接大力上网络流跑最大流也是完全没问题的(我写的网络流())。
#include <iostream>
#include <map>
#include <algorithm>
#include <queue>
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
struct edge {
int u, v, cap, nxt;
} e[kMaxN];
int n, tot = 1;
int head[kMaxN], cur[kMaxN];
void _(int u, int v, int cap) {
e[++tot] = {u, v, cap, head[u]};
head[u] = tot;
}
void add(int u, int v, int cap) {
_(u, v, cap), _(v, u, 0);
}
int s, t;
int level[kMaxN];
bool bfs() {
for (int i = 1; i <= n; i++) level[i] = 0;
std::queue<int> q;
auto record = [&](int v, int d) {
if (level[v]) return;
level[v] = d, q.push(v);
};
record(s, 1);
while (!q.empty()) {
int u = q.front();
q.pop();
cur[u] = head[u];
for (int i = head[u]; i; i = e[i].nxt) {
if (e[i].cap) record(e[i].v, level[u] + 1);
}
}
return level[t];
}
int dinic(int u, int in) {
if (u == t) return in;
int out = 0;
for (int& i = cur[u]; i; i = e[i].nxt) {
int v = e[i].v;
if (level[v] == level[u] + 1 && e[i].cap) {
int res = dinic(v, std::min(in, e[i].cap));
e[i].cap -= res, e[i ^ 1].cap += res;
in -= res, out += res;
if (in == 0) break;
}
}
if (out == 0) level[u] = 0;
return out;
}
int dinic() {
int ans = 0;
while (bfs()) {
ans += dinic(s, 1e9);
}
return ans;
}
struct node {
int x, y, id;
};
void solve() {
int N;
tot = 1, n = 0;
s = ++n, t = ++n;
// std::vector<node> d[4];
std::map<int, int> d[4];
std::map<std::pair<int, int>, int> id[4];
cin >> N;
for (int i = 1, x, y, dd; i <= N; i++) {
cin >> x >> y >> dd;
if (dd == 0) {
d[0][x] = d[0].count(x) ? std::min(d[0][x], y) : y;
}
if (dd == 1) {
d[1][y] = d[1].count(y) ? std::max(d[1][y], x) : x;
}
if (dd == 2) {
d[2][x] = d[2].count(x) ? std::min(d[2][x], y) : y;
}
if (dd == 3) {
d[3][y] = d[3].count(y) ? std::max(d[3][y], x) : x;
}
}
for (int i = 0; i < 4; i++) {
for (auto& pir : d[i]) id[i][pir] = ++n;
}
for (int i = 0; i <= 2; i += 2) {
for (auto [x1, y1] : d[i]) {
int id1 = id[i][{x1, y1}];
for (int j = 1; j <= 3; j += 2) {
for (auto [x2, y2] : d[j]) {
int id2 = id[i][{x2, y2}];
if (i == 0 && j == 1) {
if (y1 <= y2 && x1 >= x2) add(id1, id2, 1);
}
if (i == 0 && j == 3) {
if (y1 <= y2 && x1 <= x2) add(id1, id2, 1);
}
if (i == 2 && j == 1) {
if (y1 >= y2 && x1 >= x2) add(id1, id2, 1);
}
if (i == 2 && j == 3) {
if (y1 >= y2 && x1 <= x2) add(id1, id2, 1);
}
}
}
}
}
auto tmp = dinic();
cout << N - dinic() << endl;
for (int i = 1; i <= n; i++) head[i] = 0;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1003.
给定一个长度为 \(n\) 的数列 \(a_1,a_2,\cdots,a_n\) 和一个定值 \(x\)。 铃仙和因幡帝依次选数,选完后立刻删除该数。
- 铃仙每次可以选任意一个数 \(a_i\);
- 因幡帝每次必须选头部的前 \(x\) 个数,即 \(a_1, a_2,\cdots, a_x\)。若当前数列个数小于 \(x\) 个,则全部选完。
铃仙先选,随后轮流选数,直至数列为空。铃仙想要最大化铃仙所选之数的和,即假设铃仙选取了 \(a_{k_1},a_{k_2},\cdots, a_{k_m}\)(\(1\le k_1<k_2<\cdots <k_m\le n\)),铃仙想要最大化 \(\sum_{i=1}^m a_{k_i}\)。假设铃仙采用最优策略,对所有的 \(x=1,2,3,\cdots,n-1\),分别独立求出铃仙最大化的所选之数的和。
其实是唐题,没写亏了。
首先考虑固定一个 \(x\) 怎么做:
-
由于每一轮固定消耗 \(x+1\) 个数字,所有游戏最后会持续 \(m=\lceil\frac{n}{x+1}\rceil\) 轮。
-
假定你最后会选择若干数字,其下标是 \(p_1 < p_2 < p_3 < \cdots\)。容易发现最好从下标从小往大开始选。如果你提前将靠后的选走,那么会导致靠前的无法被选中。于是想让这个选取成立,就只能从小往大开始选。
-
对于第 \(j\) 次选取,也就是 \(p_j\)。它实际上可以做的选择范围是 \([(x+1)(j-1)+1, n]\) 这一个区间。实际上,由于前面选取的自由性,很有可能会导致边界不严格并且会产生若干已经被选取的位置。这样导出的状态其实非常复杂而且难以考虑,并且每一次选择都有严重后效性。正着做贪心显然不对,DP也无法实现。
-
对于这种正着做复杂度很高的问题,一般考虑倒序。
-
但是你倒着做问题就会变得比较显然:\([(x+1)(j-1) + 1, n]\) 是一个强行边界,不依赖你已经确定的决策的强行边界,并且倒着做决策是没有后效性的:这完全不会影响编号更小的决策合法性。
-
于是问题就会变成:对于每一个 \(j\),倒序遍历的时候,在 \([(x + 1)(j - 1) + 1, n]\) 中选取剩下的数中最大的那个。这个用线段树可做,能够在 \(\dfrac{n}{x} \log n\) 的复杂度情况下解决问题。
对于所有的 \(x\),容易知道 \(\sum \frac{1}{x}\) 是经典的调和级数,所以复杂度最后大概就是 \(n \log^2{n}\)。
#include <iostream>
#include <vector>
#include <set>
#define int long long
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
int val[kMaxN];
int maxp[kMaxN];
int check(int x, int y) {
return val[x] > val[y] ? maxp[x] : maxp[y];
}
void pushup(int p) {
val[p] = std::max(val[p << 1], val[p << 1 | 1]);
maxp[p] = check(maxp[p << 1], maxp[p << 1 | 1]);
}
void build(int p, int l, int r, int* a) {
if (l == r) return val[p] = a[l], maxp[p] = p, void();
int mid = (l + r) >> 1;
build(p << 1, l, mid, a);
build(p << 1 | 1, mid + 1, r, a);
pushup(p);
}
int qry(int p, int l, int r, int L, int R) {
if (L <= l && r <= R) return maxp[p];
int mid = (l + r) >> 1;
if (R <= mid) return qry(p << 1, l, mid, L, R);
if (mid + 1 <= L) return qry(p << 1 | 1, mid + 1, r, L, R);
return check(qry(p << 1, l, mid, L, R), qry(p << 1 | 1, mid + 1, r, L, R));
}
void update(int p, int v) {
val[p] = v;
while (p != 1) {
p >>= 1, pushup(p);
}
}
int n;
int a[kMaxN];
int calc(int x) {
int m = n / (x + 1);
std::multiset<int, std::greater<int>> s;
if (n % (x + 1)) m++;
// (x + 1)(i - 1) + 1
std::vector<std::pair<int, int>> chan;
int ans = 0;
for (int i = m; i >= 1; i--) {
int p = qry(1, 1, n, (x + 1) * (i - 1) + 1, n);
// cerr << "YOU GET " << p << ' ' << val[p] << endl;
chan.push_back({p, val[p]});
ans += val[p];
update(p, -1);
}
for (auto [p, val] : chan) update(p, val);
return ans;
}
void solve() {
cin >> n;
std::multiset<int> s;
int ans = 0;
for (int i = 1; i <= n; i++) cin >> a[i];
build(1, 1, n, a);
for (int i = 1; i <= n - 1; i++) {
cout << calc(i) << ' ';
}
cout << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1004. 三途川畔
给定两个非负整数 \(n\) 和 \(k\),请你构造 \(n\) 个正整数,使得这些数的乘积大于或等于它们的和,并且两者的差恰好等于 \(k\)。
换句话说,你需要找到 \(n\) 个合适的正整数 \(x_1, x_2, \dots, x_n\),满足 \(\left(x_1 + x_2 + \dots + x_n\right) + k = x_1 \times x_2 \times \dots \times x_n\)。
由于不能输出太大,你还得保证对每个你构造的数 \(x_i\),都有 \(1 \le x_i \le 10^8\)。
如果存在多种解法,输出任意一种即可。
Input
第一行包含一个整数 \(t\)(\(1 \le t \le 3000\)),表示测试用例的数量。
接下来是 \(t\) 个测试用例的描述。
每个测试用例,共一行,包含两个整数 \(n\) 和 \(k\)(\(2 \le n \le 2\times 10^5\),\(0 \le k \le 10^7\))。
保证所有测试用例中 \(n\) 的总和不超过 \(5\times 10^5\)。
只考虑 \(n=2\) 的情况。因为当 \(n>2\) 的时候,你可以强行规定 \(i > 2, x_i=1\)……然后对 \(k\) 加加减减就变成了 \(n=2\) 一模一样的做法。
也就是考虑找到正整数 \(x, y\),使得 \(x + y + k = xy\)。变形以后就是:\(x = \frac{y + k}{y - 1} = 1 + \frac{k + 1}{y - 1}\)。
由于 \(k\) 的上限也就是 \(10^7\) 这个级别,所以你直接令 \(y = 2\) 都结束了。
然后就结束了……
#include <iostream>
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
std::pair<int, int> calc(int k) {
for (int y = 2; ; y++) {
int x = (y + k) / (y - 1);
if (x + y + k == x * y) return {x, y};
}
}
void solve() {
int n, k;
cin >> n >> k;
for (int i = 1; i + 2 <= n; i++) {
cout << 1 << ' ';
}
auto [x, y] = calc(k + n - 2);
cout << x << ' ' << y << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1005. 守矢晨风
给定 \(n\) 个圆形区域,第 \(i\) 个圆的圆心为 \(\left(p_i,q_i\right)\),半径为 \(r_i\)。圆形区域为 \(\{\left(x,y\right)\mid \left(x-p_i\right)^2+\left(y-q_i\right)^2\le r_i^2\}\)。保证圆的半径不超过 \(30\)。
给定 \(m\) 次询问。每次询问给定 \(x_{i,1}\),\(y_{i,1}\),\(x_{i,2}\),\(y_{i,2}\)(\(x_{i,1} \le x_{i,2}\),\(y_{i,1} \le y_{i,2}\)),表示四个顶点分别位于 \(\left(x_{i,1},y_{i,1}\right)\),\(\left(x_{i,1},y_{i,2}\right)\),\(\left(x_{i,2},y_{i,2}\right)\),\(\left(x_{i,2},y_{i,1}\right)\) 的矩形区域 \(\{(x,y)\mid x\in [x_{i,1},x_{i,2}], y \in [y_{i,1},y_{i,2}]\}\)。每次询问求出,在给定的 \(n\) 个圆中,与给定的矩形区域有公共点的圆的数量。
样例 1 的图
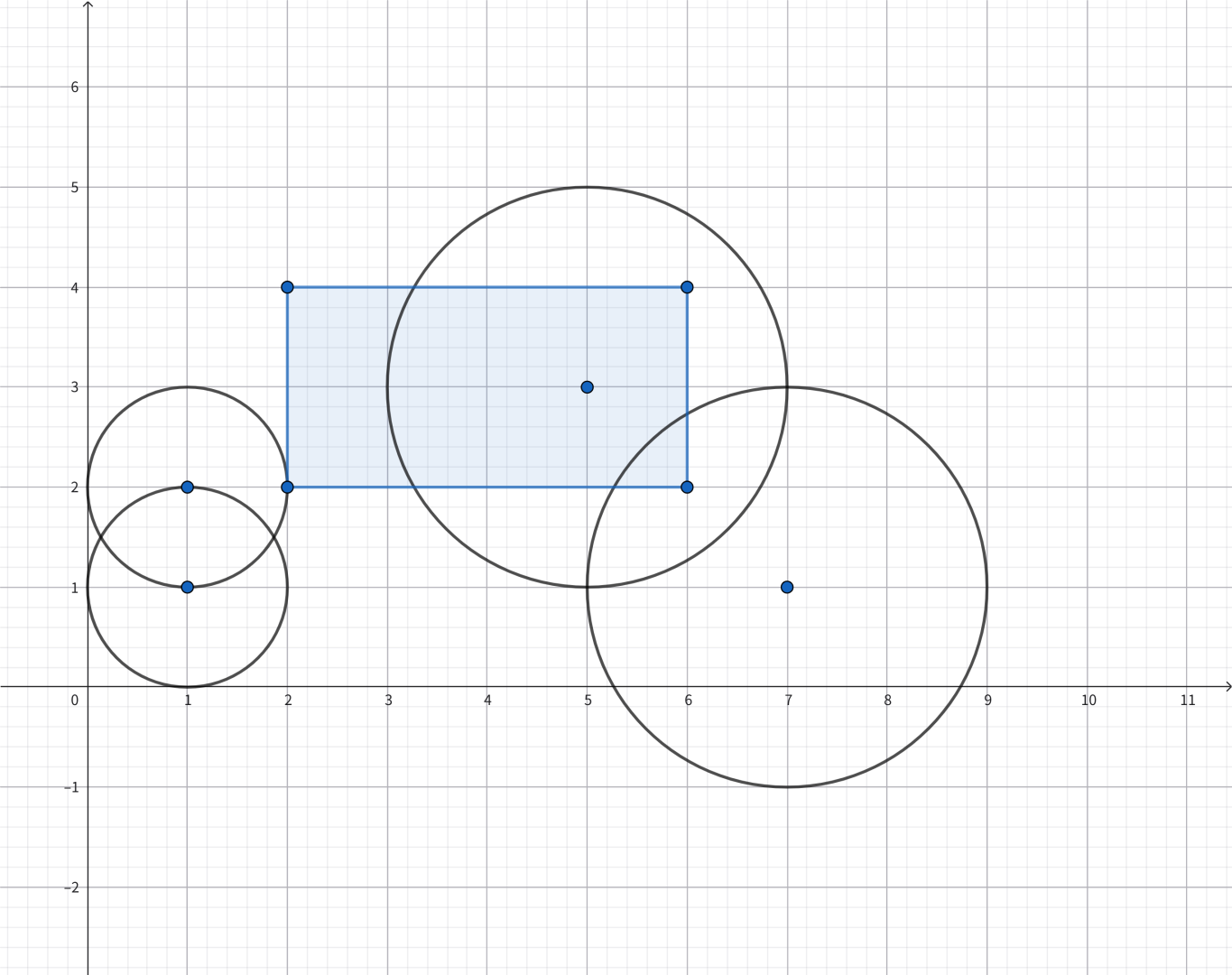
由于 \(n\) 很大,而 \(m\) 相对较小,且一个非常关键的限制是:保证圆的半径不超过 \(30\)。
这个 \(r \le 30\) 的限制是破题的核心。既然半径很小,我们可以按半径 \(r\) 的大小将所有的圆进行分组,对于每一种半径 \(r \in [1, 30]\) 单独计算贡献。
对于一个固定的半径 \(r\) 和一个询问矩形 \([x_1, x_2] \times [y_1, y_2]\),什么样的圆心 \((p, q)\) 对应的圆会和矩形相交呢?
我们可以将相交的条件转化为:圆心落在一个特定的区域内。这个特定的区域可以看作是原矩形向外“膨胀”了 \(r\) 的距离。
具体来说,这个膨胀后的区域可以分为两个部分:
- 矩形的上下两端延长区域:\(y \in [y_1, y_2]\) 且 \(x \in [x_1 - r, x_2 + r]\)。只要圆心的 \(y\) 坐标在这个范围内,且 \(x\) 坐标在这个扩展后的水平范围内,圆必定与矩形相交。
- 矩形的四个角的圆弧区域:当 \(y > y_2\) 或 \(y < y_1\) 时,圆心必须在距离四个角不超过 \(r\) 的范围内。由于 \(r \le 30\),对于 \(y_2 + k\) 或 \(y_1 - k\) (\(1 \le k \le r\)) 的每一根扫描线,其对应的合法的 \(x\) 坐标区间都可以通过勾股定理 \(dx^2 + dy^2 \le r^2\) 提前预处理出来。
这样,问题就转化为了:在平面上有一堆点(圆心),多次询问某个形状(矩形加圆角)内包含多少个点。
因为 \(m\) 较小,我们可以将这些询问区域拆解成若干条水平的“线段”,然后使用扫描线 + 树状数组来解决。
对于每个半径 \(r\):
- 将询问拆解。对于主体部分,在 \(y_1-1\) 处加入一个右端点为 \(x_2+r\)、左端点为 \(x_1-r\) 的“减去”操作(下边界),在 \(y_2\) 处加入一个“加上”操作(上边界)。
- 对于四个角的圆弧部分,枚举 \(k \in [1, r]\),在 \(y_1 - k\) 和 \(y_2 + k\) 处分别加入对应的单行查询线段。
- 将所有的圆心、查询的上下边界和圆弧线段都按 \(y\) 坐标排序,从下往上扫描。遇到圆心就把对应的 \(x\) 坐标加入树状数组;遇到查询线段就用树状数组区间求和统计答案。
整体时间复杂度约为 \(O(\max(R) \cdot m \cdot \max(R) \log(n) + n \log(n))\),其中 \(\max(R) = 30\)。虽然常数看起来有点大,但在 \(14s\) 的充裕时限下,这个扫描线做法是可以非常轻松跑过的(甚至只需要大概 \(12s\))。
#include <array>
#include <algorithm>
#include <cassert>
#include <vector>
#include <iostream>
using std::array;
using std::cerr;
using std::cin;
using std::cout;
using std::vector;
const char endl = '\n';
const int kMaxN = 2e6 + 100;
struct BIT {
static const int kMaxN = 1e7;
int a[kMaxN];
int lowbit(int x) { return x & -x; }
void clear(int x) {
for (; x < kMaxN; x += lowbit(x)) a[x] = 0;
}
void add(int x, int v) {
for (; x < kMaxN; x += lowbit(x)) a[x] += v;
}
int qry(int x) {
if (x < 0) return 0;
int ans = 0;
for (; x; x -= lowbit(x)) ans += a[x];
return ans;
}
int qry(int x, int y) { return qry(y) - qry(x - 1); }
} tr, single;
struct mat {
int x1, y1, x2, y2;
} mats[kMaxN];
int n, m;
int p[kMaxN], q[kMaxN], r[kMaxN];
int another[31][31];
void solve() {
std::vector<int> pos, y;
array<vector<std::pair<int, int>>, 31> nodes;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
cin >> p[i] >> q[i] >> r[i];
nodes[r[i]].push_back({q[i], p[i]}), y.push_back(q[i]);
pos.push_back(p[i]);
}
for (int r = 1; r <= 30; r++) {
std::sort(nodes[r].begin(), nodes[r].end());
}
for (int i = 1, x1, y1, x2, y2; i <= m; i++) {
cin >> x1 >> y1 >> x2 >> y2;
mats[i] = {x1, y1, x2, y2};
for (int k = 0; k <= 30; k++) {
pos.push_back(x1 + k), pos.push_back(x1 - k);
pos.push_back(x2 + k), pos.push_back(x2 - k);
y.push_back(y1 + k), y.push_back(y1 - k);
y.push_back(y2 + k), y.push_back(y2 - k);
}
}
std::vector<int> ans(m + 1);
std::sort(pos.begin(), pos.end());
pos.erase(std::unique(pos.begin(), pos.end()), pos.end());
auto map = [&](int x) { return std::lower_bound(pos.begin(), pos.end(), x) - pos.begin() + 1; };
std::sort(y.begin(), y.end());
y.erase(std::unique(y.begin(), y.end()), y.end());
auto calc = [&](int r) {
std::vector<std::tuple<int, int, int, int>> qrmatup, qrmatdown, qrline;
for (int i = 1; i <= m; i++) {
qrmatup.push_back({mats[i].y2, mats[i].x1 - r, mats[i].x2 + r, i});
qrmatdown.push_back({mats[i].y1 - 1, mats[i].x1 - r, mats[i].x2 + r, i});
for (int j = 1; j <= r; j++) {
qrline.push_back({mats[i].y2 + j, mats[i].x1 - another[r][j], mats[i].x2 + another[r][j], i});
qrline.push_back({mats[i].y1 - j, mats[i].x1 - another[r][j], mats[i].x2 + another[r][j], i});
}
}
std::sort(qrmatup.begin(), qrmatup.end());
std::sort(qrmatdown.begin(), qrmatdown.end());
std::sort(qrline.begin(), qrline.end());
int i = 0, j = 0, k = 0, p = 0;
auto& node = nodes[r];
std::vector<int> vis;
for (auto y : y) {
std::vector<int> tmp;
for (; j < qrmatdown.size(); j++) {
auto [yq, x1, x2, id] = qrmatdown[j];
if (yq > y) break;
x1 = map(x1), x2 = map(x2);
ans[id] -= tr.qry(x1, x2);
}
for (; p < node.size() && node[p].first == y; p++) {
int x = map(node[p].second);
tmp.push_back(x), vis.push_back(x);
tr.add(x, 1), single.add(x, 1);
}
for (; i < qrmatup.size(); i++) {
auto [yq, x1, x2, id] = qrmatup[i];
if (yq > y) break;
x1 = map(x1), x2 = map(x2);
ans[id] += tr.qry(x1, x2);
}
for (; k < qrline.size(); k++) {
auto [yq, x1, x2, id] = qrline[k];
if (yq > y) break;
x1 = map(x1), x2 = map(x2);
ans[id] += single.qry(x1, x2);
}
for (auto i : tmp) single.clear(i);
}
std::sort(vis.begin(), vis.end());
vis.erase(std::unique(vis.begin(), vis.end()), vis.end());
for (auto i : vis) tr.clear(i);
};
for (int r = 1; r <= 30; r++) calc(r);
for (int i = 1; i <= m; i++) {
cout << ans[i] << endl;
}
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
for (int r = 1; r <= 30; r++) {
for (int x = 0; x <= 30; x++) {
for (int y = 0; y <= 30; y++) {
if (x * x + y * y <= r * r) {
another[r][x] = y;
} else {
break;
}
}
}
}
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1006. 姐妹共读
给定一个长为 \(n\) 的数组 \(a_1,a_2\cdots, a_n\),求将其重排后满足 \(a_i = i\) 的下标 \(i\)(\(1\le i\le n\))的数量最大值。
其中,重排是指将原数组 \(a_1, a_2, \cdots, a_n\) 中的元素按照任意顺序重新排列,得到一个新的数组,新数组中的元素与原数组完全相同(包括重复元素),只有顺序不同。
好像没什么好说的,统计 \(n\) 以内有多少元素,存在 \(a_i\) 等于它。
你一定可以通过某种排列将这个 \(a_i\) 挤到那个位置。
#include <unordered_set>
#include <iostream>
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
int n;
int a[kMaxN];
void solve() {
cin >> n;
std::unordered_set<int> s;
for (int i = 1; i <= n; i++) {
cin >> a[i];
if (a[i] <= n) s.insert(a[i]);
}
cout << s.size() << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1007. 云端航迹
一个由 \(k\) 个非负整数 \(a_1,a_2,\cdots, a_k\) 构成的可重集 \(S=\{a_1,a_2,\cdots,a_k\}\),定义其权值为 \(a_1\oplus a_2\oplus a_3\oplus \cdots \oplus a_k\)。其中,\(\oplus\) 表示按位异或。特殊的,空集 \(\varnothing\) 的权值为 \(0\)。
在可重集 \(S=\{a_1,a_2,\cdots,a_k\}\) 上,寅丸星和娜兹琳轮流进行游戏,寅丸星先手,每人依次进行一次操作。设当前可重集为 \(S\),定义一次操作为:
- 选择一个元素 \(a_i\in S\),将 \(S\) 中的元素 \(a_i\) 删除。若 \(S=\{a_1,a_2,\cdots,a_m\}\),操作即令 \(S\leftarrow \{a_1,a_2,\cdots,a_{i-1},a_{i+1},a_{i+2},\cdots,a_m\}\)。
在任意时刻,若 \(S\) 的权值为 \(0\),则游戏立刻停止,最后一次进行操作的人失败。若最后一次无人进行操作,即初始时权值为 \(0\),则寅丸星失败。
给定一个长度为 \(n\) 的非负整数数组 \(x_1,x_2,\cdots x_n\)。寅丸星和娜兹琳对每一个不同的区间 \([l,r]\)(\(l,r\in \mathbb{Z}\) 且 \(1\le l\le r\le n\)),在区间内的所有数构成的可重集 \(S=\{x_l,x_{l+1},\cdots,x_r\}\) 上都进行了一次游戏。假设寅丸星和娜兹琳采用最优策略,求寅丸星获胜的数量和娜兹琳获胜的数量。
神秘找规律题。
通过暴力打表或者奇怪的数学推导,可以证明当序列长度为偶数的时候先手必胜。特别的,如果异或和为 \(0\) 先手必败。
所以可以根据奇偶来分别存储前缀和的计数,记异或前缀和为 \(S_i\),容易知道序列 \(l, r\) 异或和为 \(0\) 等价于 \(S_{l - 1} = S_r\)。然后好像就做完了。
也就是考虑每一个 \(r\),要找到一个奇偶性相同的 \(i\) 使得 \(S_r = S_i\)。这个直接拿一个 \(map\) 来分奇偶计数就可以了。
#include <iostream>
#include <map>
#define int long long
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
int n;
int x[kMaxN];
void solve() {
std::map<int, int> cnt[2];
int sum = 0;
cin >> n;
cnt[0][0]++;
int ans = 0;
for (int i = 1, x; i <= n; i++) {
cin >> x;
sum ^= x;
ans += (i >> 1) - cnt[i & 1][sum];
cnt[i & 1][sum]++;
}
cout << ans << ' ' << (n + 1) * n / 2 - ans << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1008. 古都茶叙
有 \(n\) 个整数 \(a_1,a_2,\ldots,a_n\),按顺时针围成一个环。已知它们的和是 \(0\)。
你需要选择一个起始位置 \(k\),从 \(a_k\) 开始沿顺时针方向取连续 \(n\) 个数,它们的所有前缀和都大于等于 \(0\)。
可以证明这样的 \(k\) 一定存在。如果有多个满足条件的 \(k\),请输出最小的那个。
换句话说,你需要寻找最小 \(k\) (\(1\le k\le n\)),使得对所有 \(l\)(\(0\le l\le n-1\)),都满足
\(\sum\limits_{i=0}^{l} a_{k+i} \ge 0\),其中 \(a_{n+1} = a_1 , a_{n+2} = a_2, \cdots, a_{2n-1} = a_{n-1}\),保证 \(\sum\limits_{i=1}^n a_i= 0\) 。
贪心是挑选 \(k\),使得前缀和 \(S_{k - 1}\) 尽可能小。
-
如果从 \(k\) 开始某个前缀和小于 \(0\),那么就会导致 \(S_{k - 1}\) 不是最小的那个。
-
同时由于 \(0\) 的约束条件很强,导致从 \(i\) 开始到 \(n\) 的和一定与 \(S_{i - 1}\) 互为相反数。
-
这样贪心就能保证前缀和一定不会小于 \(0\)。
当然也有另外一种证明思路:
-
挑选 \(i\),记 \(S_i = \sum_{j = 1}{i} a_j\)。由于题目保证了 \(n\) 个数字之和为0,这样也直接保证了 \(S_i+n = S_i\)。也就是说,\(S\) 实际上是一个周期为 \(n\) 的序列。
-
到这一步就比较显然了,你挑选的起点 \(k\) 对应的的 \(S_k - 1\) 必须是所有前缀和里面最小的那个,不然就会导致某个差分小于 \(0\)。
#include <iostream>
#include <vector>
#define int long long
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
void solve() {
int n, sum = 0, minsum = 0, id = 1;
cin >> n;
std::vector<int> a(n + 1);
for (int i = 1; i <= n; i++) {
cin >> a[i];
if (sum < minsum) {
minsum = sum, id = i;
}
sum += a[i];
}
cout << id << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1009. 微缩庭园
少名针妙丸在玩一款叫做「你的克拉夫特」的游戏。在这个游戏里,少名针妙丸可以在一个充满着方块的三维空间中自由地创造和破坏不同种类的方块。
现在少名针妙丸脚下有一块由 \(N\times M\) 个格子组成的网格。一开始,少名针妙丸在这些格子上铺满了白色地毯,然后少名针妙丸就去睡觉了。
但是不幸的是,在少名针妙丸睡觉的时候,你希望对少名针妙丸的地毯进行一些小小的修改。你希望将其中一些白色地毯改成黑色地毯,同时满足下面两个条件:
- 条件 1:任意两个黑色地毯所在的格子不能共享公共边,即满足:
- 若第 \(i\) 行第 \(j\) 列格子中为黑色地毯,则第 \(i-1\) 行第 \(j\) 列、第 \(i+1\) 行第 \(j\) 列、第 \(i\) 行第 \(j-1\) 列、第 \(i\) 行第 \(j+1\) 列格子中如果存在地毯,则不能为黑色地毯。
- 条件 2:最终形成的图案至少存在一条水平或者竖直的对称轴,即下面两个命题中至少满足一个:
- 对于任意的 \(i \in [1,N]\) 和 \(j \in [1,M]\),第 \(i\) 行第 \(j\) 列格子中的地毯颜色与第 \(N-i+1\) 行第 \(j\) 列格子中的地毯颜色相同;
- 对于任意的 \(i \in [1,N]\) 和 \(j \in [1,M]\),第 \(i\) 行第 \(j\) 列格子中的地毯颜色与第 \(i\) 行第 \(M-j+1\) 列格子中的地毯颜色相同。
你想要求出:最多可以放置多少块黑色地毯?
一个还是比较好写的题目,但是要手动推导最优情况。
-
如果 \(n\) 和 \(m\) 中有一个是奇数,那么最后的最优方案就是 \(\lceil\frac{n \times m}{2}\rceil\)。当然这个式子有点凑出来的味道:
- 如果 \(n\) 和 \(m\) 一奇数一偶数,毫无疑问就是 \(\frac{n\times m}{2}\)。
- 如果 \(n\) 和 \(m\) 都是奇数,那么更符合直觉的式子就是 \(\frac{n - 1}{2} \times m + \lceil\frac{m}{2}\rceil=\frac{n}{2} \times m + \frac{m + 1}{2}=\frac{n\times m + 1}{2}\)。容易发现其实一致。
-
如果两个都是偶数。首先对称轴那里会有两行或者两列无法放置数字,但是其他的地方一定是对半开。也就是说:
- 牺牲两列,那么答案就是:\(n \times (\frac{m}{2} - 1)\)
- 牺牲两行,那么答案就是:\(m \times (\frac{n}{2} - 1)\)
-
此时怎么做比较显然。
#include <iostream>
#define int long long
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
void solve() {
int n, m;
cin >> n >> m;
if ((n & 1) || (m & 1)) {
return cout << (n * m + 1) / 2 << endl, void();
}
cout << n * m / 2 - std::min(n, m) << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}
Problem 1010. 静海拾光
每个测试用例的共一行,两个数 \(x\)(\(1\le x\le 10^6\)) 和 \(k\)(\(1 \le k \le 10^{18}\)),表示查询所有元素和不超过 \(x\) 的非空正整数序列按字典序升序排序后的第 \(k\) 个序列。保证字典序排名为 \(k\) 的序列存在。
保证所有测试用例中的 \(x\) 的总和不超过 \(2 \times 10^6\)。
首先可以计算得到,当数值总和为 \(x\) 的方案数为 \(2^{x - 1}\)。证明方法比较简单,可以用组合数来计算。当然也有一种思考方式:
- 记 \(a_x\) 为总和为 \(x\) 的方案数。容易知道 \(a_1 = 1\)。那么对于 \(a_x\),若我们使得总和增加 \(1\),那么对于原本就存在的序列来说,一共有两种方式:在最末尾的数字增加一,或者在序列末尾增加一个新的数字 \(1\)。于是可以得到 \(a_{x + 1} = 2a_x\)。可能会质疑为什么一定要在末尾添加,因为这样能够保证不重不漏。
于是可以计算出数值不超过 \(x\) 的方案树为 \(2^x - 1\)。
考虑当前为 \(x, k\) 的时候,枚举下一位的数字 \(i\):
-
下一位为 \(i\),那么方案数应该有:
- \(i\) 然后跟一些数字,这些数字方案数量是 \(2^{x - i} - 1\)
- 只有一个 \(i\)
所以可以得到方案应该是 \(2^{x - i}\)。
-
如果 \(k \leq 2^{x - i}\),说明 \(k\) 一定被包括在这些方案里面,这个时候去掉单独的一个 \(i\) 这个方案,然后令 \(x = x-i, k = k- 1\) 在从 \(i=1\) 开始继续找。
-
否则说明 \(i\) 开头的方案全都不符合,这个时候 \(k\) 减去 \(2^{x}\)。
上述流程和在树上做一个搜索、然后找节点在哪个子树的方法其实是一样的。
#include <iostream>
#define int long long
// #define ONCE
using std::cerr;
using std::cin;
using std::cout;
const char endl = '\n';
const int kMaxN = 1e6 + 100;
void solve() {
int x, k;
cin >> x >> k;
while (k) {
for (int i = 1;; i++) {
int cnt = (x - i <= 60 ? 1ll << (x - i) : 1ll << 60);
if (k <= cnt) {
cout << i << ' ';
k--;
x -= i;
break;
} else {
k -= cnt;
}
}
}
cout << endl;
}
signed main() {
cin.tie(nullptr)->sync_with_stdio(false), cout.tie(nullptr), cerr.tie(nullptr);
int t = 1;
#ifndef ONCE
cin >> t;
#endif
while (t--) solve();
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号