ESPCN:图像超分中的亚像素卷积

转载自:从SRCNN到EDSR,总结深度学习端到端超分辨率方法发展历程 - 知乎 (zhihu.com)
ESPCN:
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR2016)
作者在本文中介绍到,像SRCNN那样的方法,由于需要将低分辨率图像通过上采样插值得到与高分辨率图像相同大小的尺寸,再输入到网络中,这意味着要在较高的分辨率上进行卷积操作,从而增加了计算复杂度。本文提出了一种直接在低分辨率图像尺寸上提取特征,计算得到高分辨率图像的高效方法。ESPCN网络结构如下图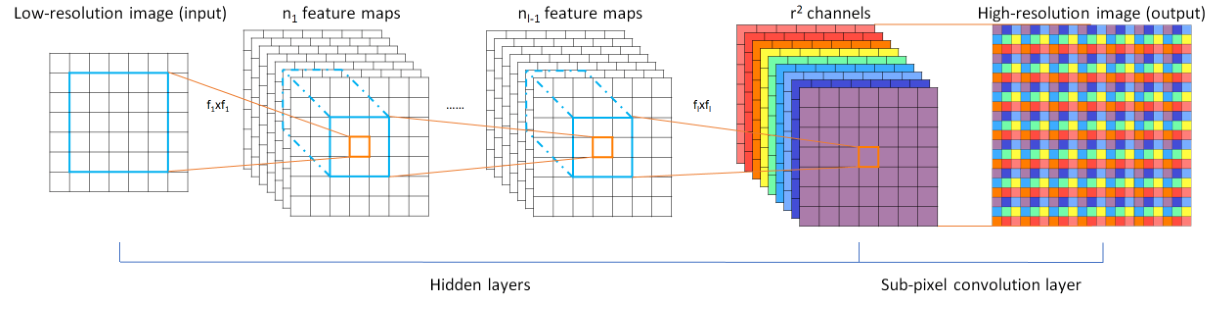
ESPCN:
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为 r^2 的与输入图像大小一样的特征图像。
再将特征图像每个像素的 r^2 个通道重新排列成一个 r×r 的区域,对应高分辨率图像中一个 r×r 大小的子块,从而大小为 H×W×r^2 的特征图像被重新排列成 rH×rW×1 的高分辨率图像。
我理解的亚像素卷积层包含两个过程,一个普通的卷积层和后面的排列像素的步骤。就是说,最后一层卷积层输出的特征个数需要设置成固定值,即放大倍数r的平方,
这样总的像素个数就与要得到的高分辨率图像一致,将像素进行重新排列就能得到高分辨率图。
在ESPCN网络中,图像尺寸放大过程的插值函数被隐含地包含在前面的卷积层中,可以自动学习到。由于卷积运算都是在低分辨率图像尺寸大小上进行,因此效率会较高。
训练时,可以将输入的训练数据标签,预处理成重新排列操作前的格式,比如将21×21的单通道图,预处理成9个通道,7×7的图,这样在训练时,就不需要做重新排列的操作。另外,ESPCN激活函数采用tanh替代了ReLU。损失函数为均方误差。
github(tensorflow): https://github.com/drakelevy/ESPCN-TensorFlow
github(pytorch): https://github.com/leftthomas/ESPCN
github(caffe): https://github.com/wangxuewen99

 浙公网安备 33010602011771号
浙公网安备 33010602011771号