
022304105叶骋恺数据采集第四次作业
作业1
代码与运行结果
for market_type in ["沪深A股", "上证A股", "深证A股"]:
driver.get(market_urls[market_type])
time.sleep(5)
try:
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "table tbody tr")))
time.sleep(3)
except TimeoutException:
print(f"{market_type}页面加载超时")
continue
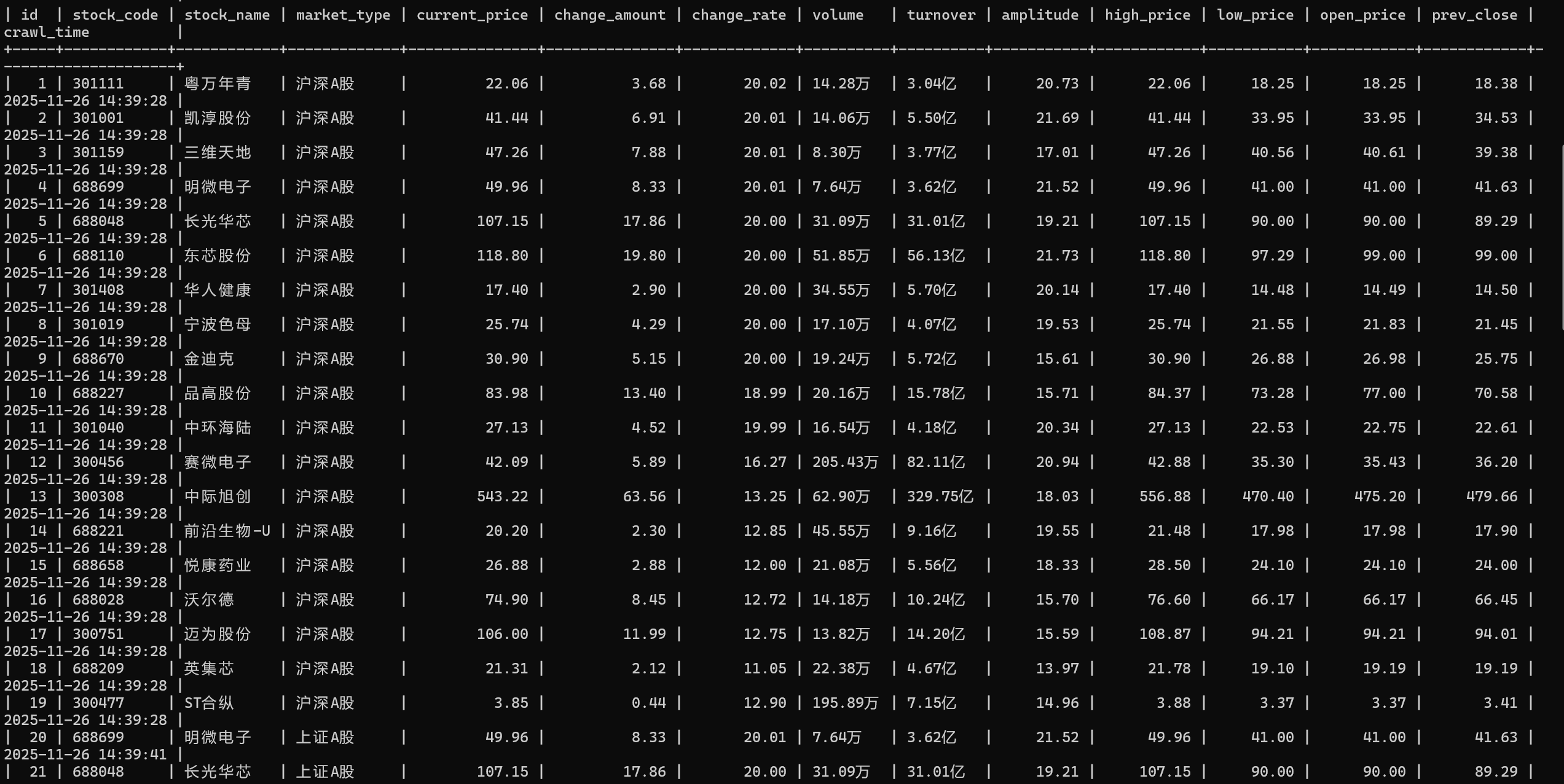
# 提取前20行数据
rows = driver.find_elements(By.CSS_SELECTOR, "table tbody tr")[:20]
stock_data = []
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
if len(cells) < 14:
continue
# 解析数据
stock_code = re.sub(r'\s+', '', cells[1].text.strip())
stock_name = re.sub(r'\s+', '', cells[2].text.strip())
# 价格解析函数
def parse_num(text, is_percent=False):
if not text or text in ['-', '--', '']:
return None
try:
cleaned = re.sub(r'[^\d.-]', '', text.strip())
return round(float(cleaned), 2) if cleaned else None
except:
return None
current_price = parse_num(cells[4].text)# 解析当前价格
change_rate = parse_num(cells[5].text, is_percent=True)# 解析涨跌幅
change_amount = parse_num(cells[6].text)# 解析涨跌额
volume = re.sub(r'\s+|,', '', cells[7].text.strip())# 解析成交量
turnover = re.sub(r'\s+|,', '', cells[8].text.strip())# 解析成交额
amplitude = parse_num(cells[9].text, is_percent=True)# 解析振幅
high_price = parse_num(cells[10].text)# 解析最高价
low_price = parse_num(cells[11].text)# 解析最低价
open_price = parse_num(cells[12].text)# 解析开盘价
prev_close = parse_num(cells[13].text)# 解析前收盘价
if stock_code and stock_name and current_price is not None:
stock_data.append({
'stock_code': stock_code, 'stock_name': stock_name, 'market_type': market_type,
'current_price': current_price, 'change_rate': change_rate, 'change_amount': change_amount,
'volume': volume, 'turnover': turnover, 'amplitude': amplitude,
'high_price': high_price, 'low_price': low_price, 'open_price': open_price, 'prev_close': prev_close
})
作业心得
这段股票数据爬取与存储的代码实践,让我收获颇丰:学会了通过 CSS 选择器和标签定位提取表格数据,结合正则表达式处理文本中的空格、特殊符号等脏数据,确保数据格式的规范性;在数据存储层面,深入理解了 MySQL 数据库的连接配置、批量插入与更新逻辑,有效解决了重复数据覆盖的问题,同时通过异常捕获机制提升了代码的健壮性,避免因页面加载超时、数据库连接失败等突发情况导致程序崩溃。整个过程中,我深刻体会到 “数据提取 - 清洗 - 存储” 全流程的严谨性,比如针对不同字段设计差异化的解析函数,既保证了数据准确性,也提升了代码的复用性;此外,通过处理浏览器自动化限制、数据格式异常等问题,也锻炼了我排查问题、优化代码的能力,为后续类似爬虫项目的开发积累了宝贵的实践经验。
作业2
代码与运行结果
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchWindowException, WebDriverException
import time
import pymysql
options = webdriver.EdgeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Edge(service=Service(r"D:\acaconda\Scripts\msedgedriver.exe"),options=options)
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
driver.maximize_window()
try:
db = pymysql.connect(host='127.0.0.1', user='root', password='705805959', port=3306, database='mooc')
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS courseMessage')
sql = '''CREATE TABLE courseMessage(cCourse varchar(64),cCollege varchar(64),cTeacher varchar(16),cTeam varchar(256),cCount varchar(16),
cProcess varchar(32),cBrief varchar(2048))'''
cursor.execute(sql)
except Exception as e:
print(e)
def spiderOnePage():
time.sleep(3)
courses = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')
current_window_handle = driver.current_window_handle
for course in courses:
cCourse = cCollege = cTeacher = cTeam = cCount = cProcess = cBrief = ""
try:
cCourse = course.find_element(By.XPATH, './/h3').text #提取课程名称
cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text #提取院校
cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text #提取老师
cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text #提取学校人数
cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text #提取课程进度
course.click()
Handles = driver.window_handles
if len(Handles) < 2:
continue
driver.switch_to.window(Handles[1])
time.sleep(3)
#捕获详情页被手动关闭的异常
try:
cBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text#先通过固定ID找简介
if len(cBrief) == 0:
cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*')# 获取简介区块下的所有子元素
cBrief = ""
for c in cBriefs:
cBrief += c.text
cBrief = cBrief.replace('"', r'\"').replace("'", r"\'")
cBrief = cBrief.strip()
nameList = []
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]') #提取授课团队
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]') #提取下一页按钮
while len(nextButton)!= 0:
nextButton[0].click()
time.sleep(3)
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
cTeam = ','.join(nameList)
except NoSuchWindowException:
driver.switch_to.window(current_window_handle)
continue
# 关闭窗口时捕获异常
try:
driver.close()
except WebDriverException:
pass
driver.switch_to.window(current_window_handle)
try:
cursor.execute('INSERT INTO courseMessage VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (
cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
except Exception as e:
print(e)
# 捕获所有异常,确保继续下一个课程
except Exception as e:
pass
try:
driver.switch_to.window(current_window_handle)
except:
pass
continue
driver.get('https://www.icourse163.org/')
driver.get(WebDriverWait(driver, 10, 0.48).until(EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a'))).get_attribute('href'))
spiderOnePage()
count = 1
try:
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
while next_page.get_attribute('class') == '_3YiUU ':
if count == 2:
break
count += 1
next_page.click()
spiderOnePage()
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
except Exception as e:
print(f"翻页失败:{e}")
try:
cursor.close()
db.close()
except:
pass
time.sleep(3)
driver.quit()

作业心得
通过编写这个MOOC课程爬虫项目,我深刻体会到Selenium自动化测试与数据采集的巧妙结合。通过window_handles和switch_to.window实现点击具体课程,再进入该课程页面继续爬取,掌握到了特殊的爬取方式。通过循环检测"下一页"按钮的方式实现了完整数据采集,这种应对动态内容的策略让我对Web数据抓取有了更深的理解。在访问目标网页时,我发现页面加载后会弹出广告窗口,遮挡页面并阻碍了后续的元素定位和操作。为了解决这个问题,我在代码中加入了捕获 NoSuchWindowException和WebDriver Exception两个错误,通过手动关闭窗口来切换回主窗口继续下一个,从而确保了自动化的稳定性。同时,将爬取结果实时存储到MySQL数据库的实践,让我对数据清洗、异常处理和数据库操作有了更扎实的掌握,为后续的数据分析工作奠定了良好基础。
作业3
环境搭建:
任务一:开通MapReduce服务

实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三: 安装Flume客户端
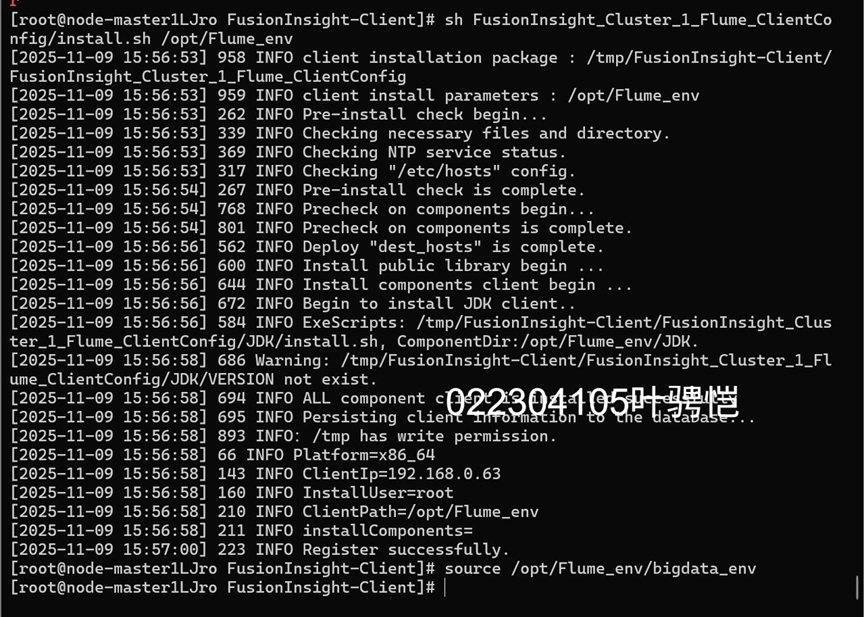
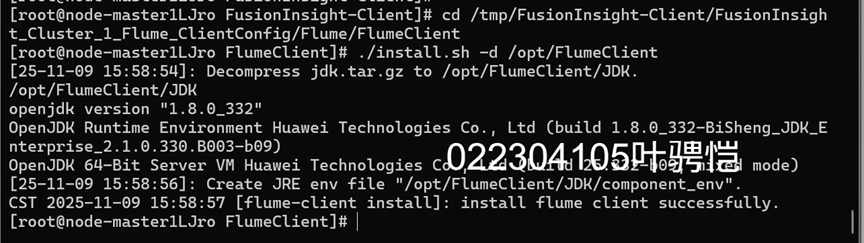
任务四:配置Flume采集数据


作业心得
通过本次实践让我对华为云的相关服务有了初步认识、拓宽自己的眼界与认知!但在根据实践手册一步一步进行操作时还是有碰到些许问题,应该是自己较为粗心在配置时出现问题,今后应当更加注意细节。
代码地址:https://gitee.com/xiaoyeabc/2025_crawl_project/tree/master/作业4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号