
022304105叶骋恺数据采集第一次作业
作业1
代码与运行结果
import urllib.request
from bs4 import BeautifulSoup
url ="http://www.shanghairanking.cn/rankings/bcur/2020"
response = urllib.request.urlopen(url, timeout=3)
html= response.read().decode('utf-8')
soup = BeautifulSoup(html, 'lxml')
name = soup.find_all(name='img',class_="univ-logo")
province = soup.find_all('td', attrs={"data-v-389300f0": True})
l=len(name)
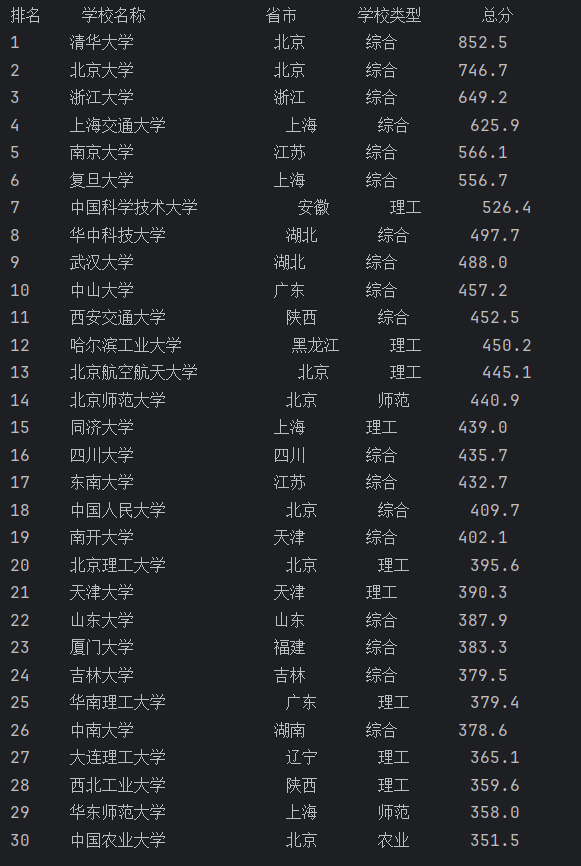
print(f"{'排名':<6}{'学校名称':<16}{'省市':<8}{'学校类型':<10}{'总分'}")
for i in range(l):
a=i+1
b=name[i]['alt']
c=province[i*6+2].text.strip()
d=province[i*6+3].text.strip()
e=province[i*6+4].text.strip()
print(f"{a:<6}{b:<18}{c:<8}{d:<8}{e}")
作业心得
本次实验的核心是爬取一个动态加载数据的网页。在数据解析上,我使用了BeautifulSoup。然后通过查找名字为td,标签为data-v-389300f0的表格单元格提取数据。最后用格式化字符串f-string设置各列左对齐宽度,保证排版整齐。这个实验让我深刻体会到,爬虫开发的核心难点,往往不在于代码语法本身,而在于对目标网页 DOM 结构的深度理解
作业2
代码与运行结果
import urllib.request
import re
url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"
response = urllib.request.urlopen(url, timeout=3)
html= response.read().decode('gb2312')
c = re.compile(r'<li[^>]*?>(.*?)</li>', re.S)
lis = c.findall(html)
a = re.compile(r'<a\s*?title="\s*([^"]*?)"', re.S)
b = re.compile(r'<span class="price_n">(.*?)</span>', re.S)
for i, li in enumerate(lis):
name = a.findall(li)
price = b.findall(li)
if name and price:
print(f"{name[0].strip()} {price[0].strip().replace('¥', '¥')}")

作业心得
本次实验以当当网图书搜索页为目标,通过urllib和re库实现了图书名称与价格的爬取。核心逻辑在于:借助正则表达式按文本模式定位数据 —— 通过 r'<a\s?title="\s([^"]?)"' 这一正则表达式,匹配带有 title 属性的 a 标签,捕获属性值以获取商品名;通过 r'(.?)' 匹配价格对应的 span 标签,提取标签内的文本内容。这次实践让我深刻认识到,爬虫开发的关键挑战并非语法本身,而是对网页结构的精准拆解。例如,该网站页面中 class="price_n" 的专属设计,使其成为价格数据的可靠标识;而<“li”>标签作为商品信息的独立容器,本质上是网站对内容布局的结构化处理,需通过先提取容器再匹配信息的方式确保数据对应。此外,编码格式的选择(非默认utf-8),体现了对目标网站字符集的针对性适配,这也是数据解析时容易被忽略的细节。
作业3
代码与运行结果
import urllib.request
from urllib.parse import urljoin
from bs4 import BeautifulSoup
import os
url ="https://news.fzu.edu.cn/yxfd.htm"
response = urllib.request.urlopen(url, timeout=3)
html= response.read().decode('utf-8')
soup = BeautifulSoup(html, 'lxml')
imgs = soup.find_all(name='img')
save_folder = "images"
if not os.path.exists(save_folder):
os.makedirs(save_folder)
for i in range(len((imgs))):
img_src = imgs[i].get('src', '')
full_img_url = urljoin(url, img_src)
filename = full_img_url.split('/')[-1].split('?')[0]
path = os.path.join(save_folder,filename)
urllib.request.urlretrieve(full_img_url,path)
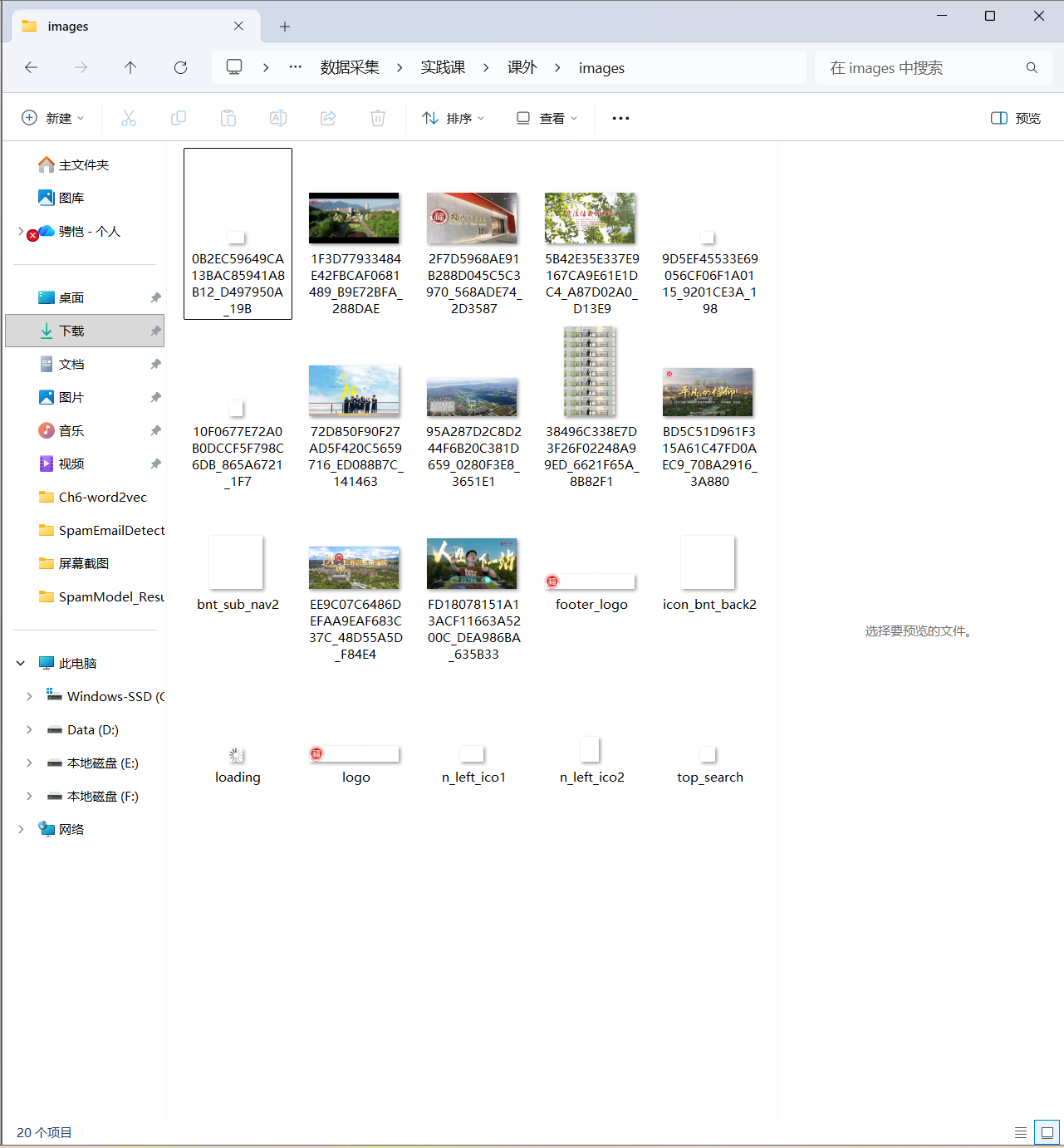
作业心得
本次实验实现了福州大学新闻网页面图片的批量下载,核心逻辑围绕 “图片链接解析 - URL 标准化 - 本地存储” 展开。代码通过BeautifulSoup提取所有img标签的src属性,利用urljoin将相对路径转换为绝对 URL,再通过urlretrieve按文件名保存至指定文件夹。实践中最深刻的体会是:网络资源爬取的难点不仅在于数据提取,更在于 “URL 标准化” 与 “文件系统适配” 的细节处理。此外,urljoin的应用解决了 “相对路径无法直接访问” 的核心问题,这让我意识到:在跨页面资源爬取时,URL解析器是比标签定位更基础的工具。
代码地址:https://gitee.com/xiaoyeabc/2025_crawl_project/tree/master/作业1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号