突破数据瓶颈:大型语言模型的数据合成与增强技术全景解析
大型语言模型(LLM)的迅猛发展,正面临一个核心矛盾:模型对海量、高质量数据的需求呈指数级增长,而现实世界的数据供给却步履维艰。数据耗尽危机已迫在眉睫,这使得数据合成与增强技术成为推动LLM持续进化的关键引擎。本文旨在深度解析这一领域的技术脉络,为开发者和研究者提供一份清晰的路线图。
引言:数据,LLM的阿喀琉斯之踵
无论是训练像GPT-4这样的通用巨兽,还是微调用于特定领域(如使用Python进行数据分析或Go语言后端开发)的专用模型,其性能天花板本质上由训练数据的质量、多样性和规模决定。然而,高质量数据的增长速度已远远落后于模型参数和数据集的扩张速度。这催生了一个紧迫的需求:我们必须更高效地利用现有数据,并创造新的数据来源。数据合成与增强,正是在此背景下从辅助手段跃升为核心技术。
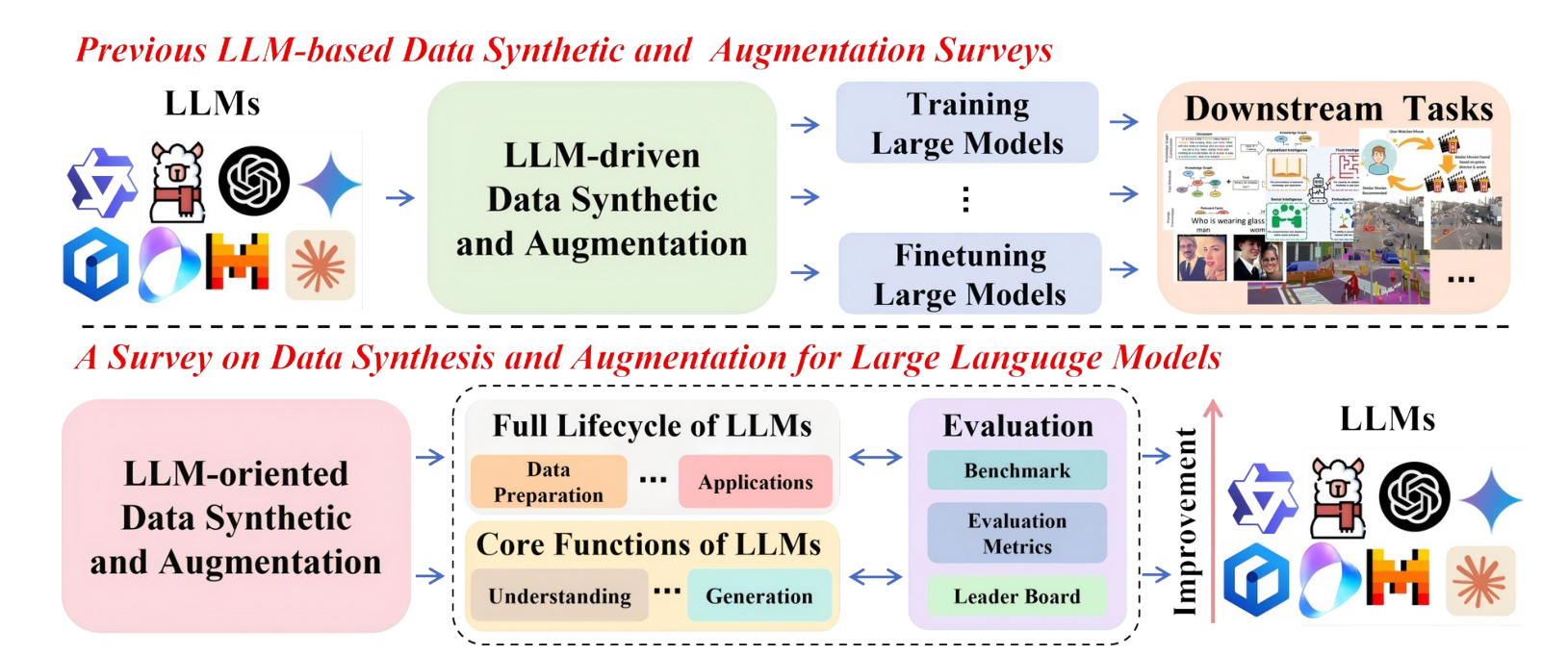
与以往侧重于下游任务应用的综述不同,本文聚焦于数据技术如何直接赋能LLM生命周期的各个阶段。下图清晰地展示了该领域研究在时间和地域上的发展趋势:
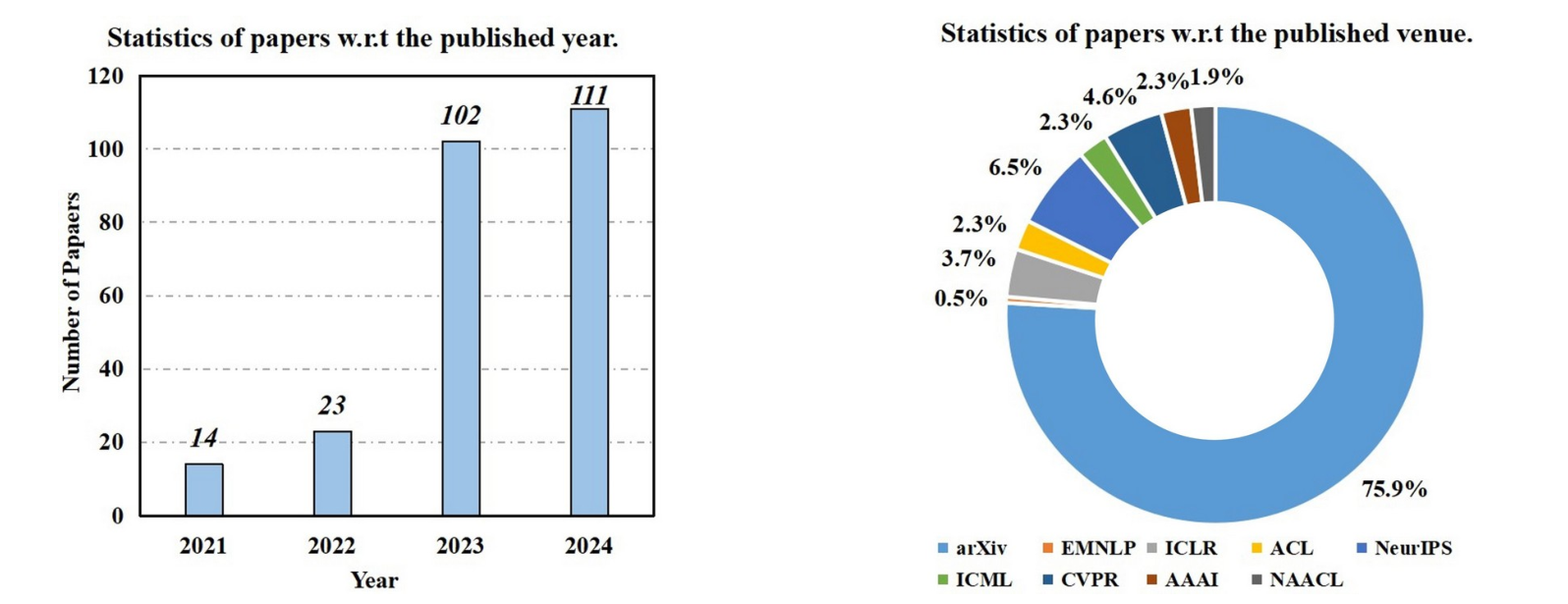
我们的讨论将围绕一个核心分类框架展开,该框架系统性地梳理了数据生成的两大路径:

两大核心范式:数据增强与数据合成
1. 数据增强:从数据到数据的艺术
数据增强旨在对原始数据进行加工处理,以增加其多样性和数量,同时不改变其本质语义。这如同为一位厨师(模型)提供同一种食材(数据)的多种切法和烹饪方式,以锻炼其全面的料理能力。主要方法包括:
- 数据标注:利用LLM强大的语言理解能力,为海量未标注数据自动生成标签,极大降低标注成本。
- 数据重构:通过提示工程,指导LLM将现有数据改写成不同风格、格式或复杂度,例如将一段JavaScript代码注释重构成更详细的API文档。
- 协同标注:结合人类专家的精确性和LLM的效率,形成人机协作的标注闭环,兼顾质量与规模。
2. 数据合成:从零到一的创造
数据合成则更具创造性,其目标是生成全新的、符合真实数据分布的数据样本。这主要依赖于模型本身的能力,可分为:
- 通用模型蒸馏:使用如GPT-4等强大的“教师模型”来生成训练“学生模型”所需的高质量数据。这是目前最主流的方法。
- 领域模型蒸馏:针对特定领域(如医疗、法律、C++代码生成)训练专用模型来合成数据,以解决通用模型在专业领域知识不足的问题。
- 模型自我提升:让模型生成数据来训练自己,形成自我迭代改进的循环,减少对外部数据的依赖。
下图展示了这些技术在LLM发展历程中的应用与演进:
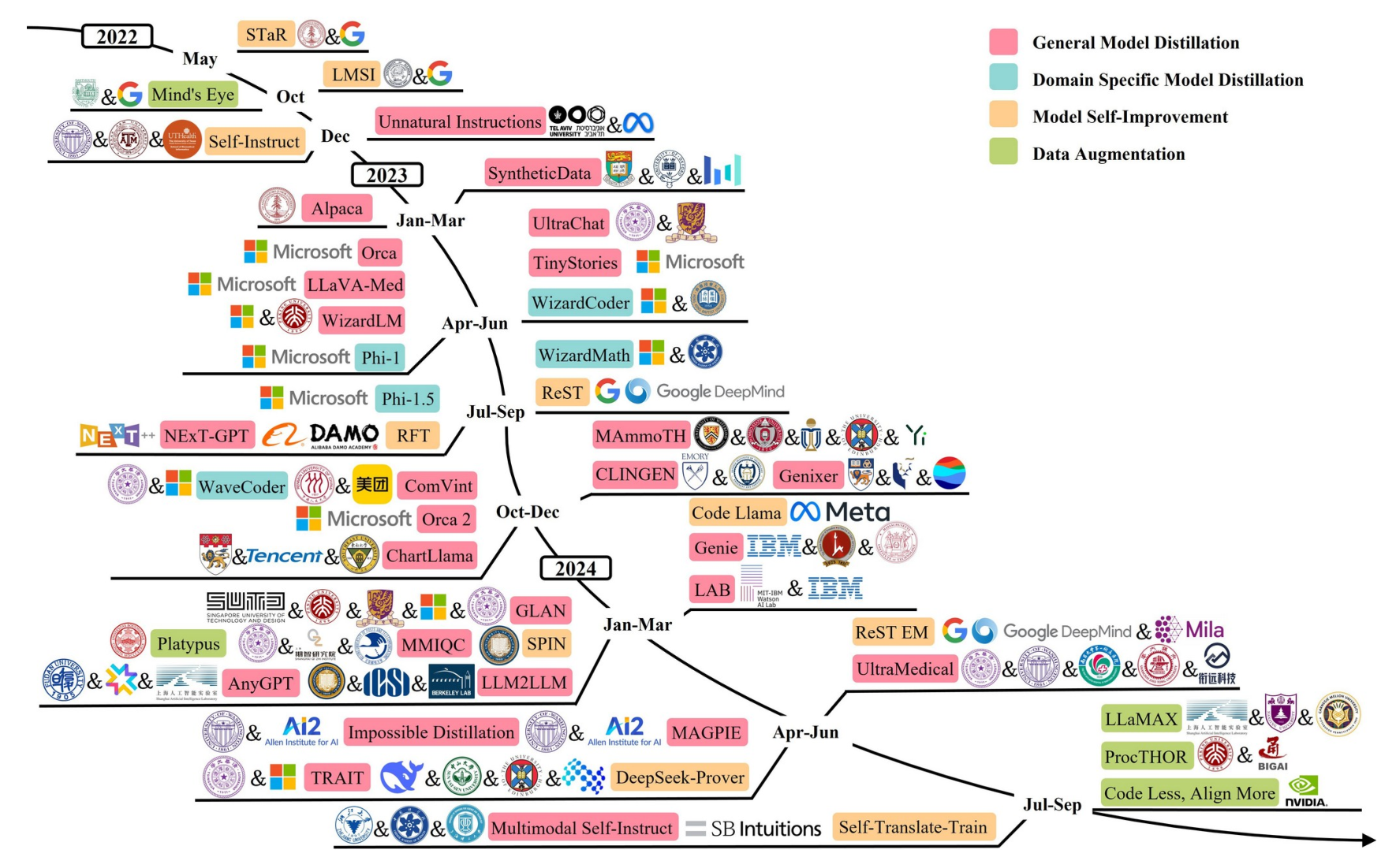
赋能LLM全生命周期
数据技术并非一次性工具,而是贯穿LLM构建与优化的始终。我们可以从生命周期视角来审视其应用:
预训练阶段
目标是构建模型的基础语言能力。在此阶段,通过通用模型蒸馏合成海量文本,或通过数据重构扩充现有语料库,可以为模型提供更丰富、多样的语言模式,减少偏见,打下坚实根基。
微调与指令调优阶段
这是让模型适应特定任务或学会遵循指令的关键环节。例如,我们可以:
- 使用强大的教师模型合成高质量的
问答对或代码-注释对来微调模型。 - 通过合成推理步骤(Chain-of-Thought),让模型不仅学习答案,更学习得出答案的逻辑过程,这对于提升TypeScript或Python代码的推理能力至关重要。
- 利用模型自我提升,让一个已初步学会代码生成的模型,通过分析自己的输出并生成改进版本的数据,进行迭代优化。
偏好对齐阶段
为了让模型输出更安全、有用、符合人类价值观,需要基于人类反馈进行强化学习(RLHF)。数据合成在此扮演了成本削减器的角色:
- RLAIF:用AI反馈替代部分人类反馈,通过LLM自动生成偏好对比数据。
- 领域蒸馏:合成特定领域(如安全响应、伦理咨询)的偏好数据,使模型在专业场景下也能可靠对齐。
以下分类法进一步概括了数据生成如何针对LLM的不同核心功能进行优化:
前沿应用场景实战
在数据稀缺的垂直领域,数据合成技术正大放异彩:
- 数学与科学推理:合成带有详细解题步骤的数理问题,增强模型的逻辑推理能力。
- 代码生成:由于代码具有可执行、可验证的特性,非常适合大规模合成。可以生成海量
(问题描述,Python/Go/JavaScript代码)对来训练模型。 - 医疗与法律:在保护隐私的前提下,从知识图谱或脱敏文档中合成专业的问答数据,打造领域专家助手。
挑战、局限与未来方向
尽管前景广阔,但数据合成与增强之路仍布满荆棘:
- ⚠️ 数据质量隐忧:合成数据可能存在多样性不足、长尾分布缺失、事实错误或逻辑不一致等问题,导致模型过拟合或学习到错误模式。
- ⚠️ 评估难题:缺乏鲁棒的自动化指标来评估合成数据的真实性和有效性。如何避免数据污染(测试数据混入训练集)也是一大挑战。
- ⚠️ 伦理与安全:合成数据可能放大模型原有的偏见,或生成有害、带有隐私信息的内容。
未来方向展望:
- 多模态合成:从纯文本扩展到图像、音频、视频的跨模态数据生成。
- 实时与交互式合成:在模型部署后,根据用户交互实时生成数据并进行在线学习。
- 建立稳健的质量评估体系:开发更可靠的自动化评估指标和去污染技术。
- 负责任的数据合成:将伦理考量嵌入数据生成流程,确保技术向善。
结论:迈向以数据为中心的人工智能新时代
数据合成与增强已不再是LLM训练中的可选技巧,而是应对数据稀缺危机的战略性解决方案。它贯穿于模型预训练、微调、对齐的全过程,并在数学、编程、科学等专业领域展现出巨大潜力。尽管在数据质量、评估和伦理方面仍面临严峻挑战,但该领域的持续创新正推动我们从一个“模型为中心”的范式,转向一个“数据为中心”的AI发展新阶段。未来的LLM进步,将很大程度上取决于我们创造、管理和利用数据智能的能力。
(本文核心观点基于相关学术综述,作者信息及摘要图示如下:)
 ---
---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号