

机器学习基础入门(第三篇):监督学习详解与经典算法 - 详解
目录
4. 支持向量机(Support Vector Machine, SVM)
一、前言
在前两篇文章中,我们先后认识了机器学习的发展历程与应用场景,以及不同的分类方式。我们提到,监督学习是机器学习中最基础、最常见的任务类型,也是很多人工智能应用的核心。
从垃圾邮件识别,到语音助手中的语音转文字,再到推荐体系中的点击预测,背后都离不开监督学习的支撑。对于初学者来说,掌握监督学习就是打开机器学习世界的第一把钥匙。
本文将从以下几个方面深入解读监督学习:
什么是监督学习?
监督学习的常见任务:分类与回归
监督学习的经典算法
模型评估与性能衡量
典型应用案例
二、什么是监督学习?
指经过带有标签的素材训练模型,让模型学会从输入到输出的映射关系。就是监督学习(Supervised Learning)
1. 核心思想
给定一组训练内容:
D={(x1,y1),(x2,y2),...,(xn,yn)}
其中:
xi 是输入特征(例如一封邮件的文本内容,一张图片的像素矩阵)。
yi是标签(例如“垃圾/非垃圾”,“猫/狗”)。
找到一个函数 (f(x)),使得预测值 y^ = f(x)) 与真实值 (y) 尽可能接近。就是监督学习的目标就
2. 任务类别
监督学习通常分为两大类:
分类任务(Classification)离散的类别。就是:输出
/否)。就是例:识别邮件是否为垃圾邮件(
回归任务(Regression):输出是连续的数值。
例:预测房价、预测销量。
三、监督学习的经典算法
接下来,大家将逐一介绍几种监督学习中最常见的经典算法。
1. 线性回归(Linear Regression)
(1)思想
线性回归用于解决回归问题。它假设输出 (y) 与输入特征 (x) 之间存在线性关系:
y=w1x1+w2x2+...wnxn+b
其中 (wi) 是权重,(b) 是偏置。
(2)训练目标
通过最小化**均方误差(MSE)**来确定参数: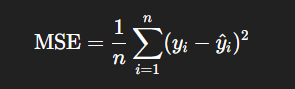
(3)应用场景
房价预测
经济指标预测
销售额预测
2. 逻辑回归(Logistic Regression)
(1)思想
分类算法。它通过 Sigmoid 函数将线性模型的输出映射到 ([0, 1]),用来表示样本属于某个类别的概率。就是逻辑回归纵然名字叫“回归”,实际上
公式如下:
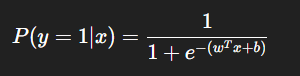
(2)应用场景
二分类问题(垃圾邮件/正常邮件,患病/未患病)。
信用风险评估。
工业界应用最广泛的算法之一,因其简单、可解释性强、计算效率高。就是逻辑回归
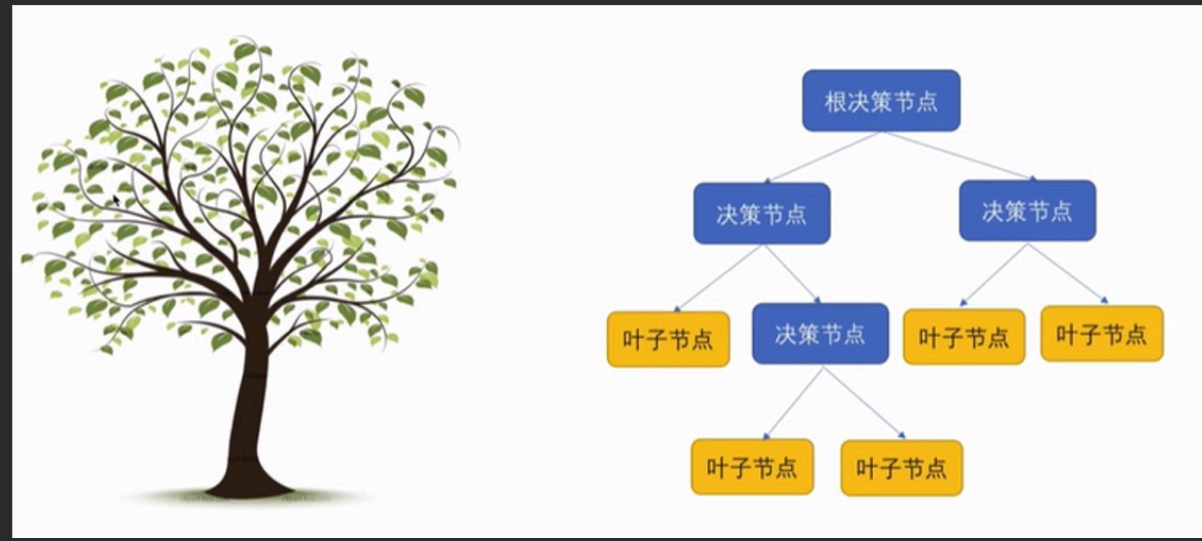
3. 决策树(Decision Tree)
(1)思想
决策树依据一系列“是/否”的疑问,将数据逐步划分,最终得到分类或回归结果。
例如:
“天气是否晴朗?”
假如是,再问“湿度是否高?”
否适合打网球”的预测。就是最终得到“
(2)优点
易于理解和解释(可视化树结构)。
能处理非线性关系。
(3)缺点
容易过拟合。
对数据扰动敏感。
(4)改进方法
随机森林(Random Forest):集成多棵树,降低过拟合。
梯度提升树(GBDT、XGBoost、LightGBM):性能更强,工业应用广泛。
4. 支持向量机(Support Vector Machine, SVM)
(1)思想
SVM 通过构造一个最优超平面,将不同类别的信息尽可能分开,并最大化分类间隔。
在二维空间中,它就是找到一条分界直线;在高维空间中,则是一个超平面。
(2)应用场景
文本分类(垃圾邮件识别)。
图像分类。
(3)特点
在小数据集下表现优秀。
对高维数据处理能力强。
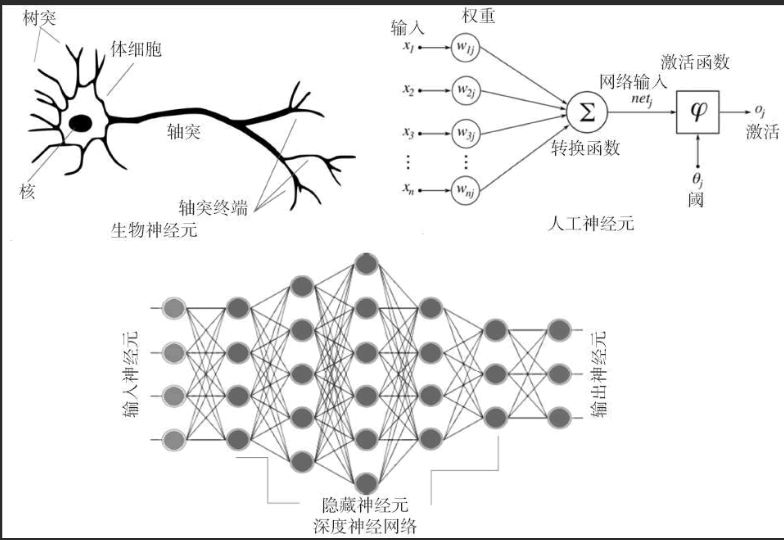
5. 神经网络(Neural Networks)
(1)思想
神经网络模拟人脑神经元的工作机制,由输入层、隐藏层和输出层组成。依据非线性激活函数,神经网络能够学习复杂的非线性关系。
(2)应用场景
图像识别(卷积神经网络 CNN)。
自然语言处理(循环神经网络 RNN,Transformer)。
语音识别、推荐系统。
(3)优势
表达能力强,适合处理大规模复杂数据。
可扩展为深度学习,解决更复杂任务。
四、监督学习的训练与评估
在监督学习中,除了选择算法,还必须关注模型评估,否则可能出现过拟合或欠拟合。
1. 内容划分
训练集(Training Set):用于训练模型。
验证集(Validation Set):用于调参和模型选择。
测试集(Test Set):用于最终评估模型性能。
常用方法:交叉验证(Cross Validation)。
2. 评估指标
(1)分类任务
准确率(Accuracy):预测正确样本占总样本的比例。
精确率(Precision):预测为正例的样本中,有多少是真正的正例。
召回率(Recall):所有正例中,有多少被正确识别。
F1 值:精确率和召回率的调和平均数。
(2)回归任务
均方误差(MSE)
均方根误差(RMSE)
平均绝对误差(MAE)
(R^2) 决定系数
3. 模型优化
正则化:如 L1(Lasso)、L2(Ridge),防止过拟合。
特征工程:选择和构造更合适的特征。
超参数调优:网格搜索、随机搜索、贝叶斯优化。
五、监督学习的应用案例
为了更直观,我们来看两个实际案例:
案例一:房价预测(回归)
输入特征:房屋面积、地段、楼层、装修情况。
输出标签:房价(连续值)。
算法选择:线性回归 / 随机森林回归。
案例二:垃圾邮件识别(分类)
输入特征:邮件文本中的词频、发件人地址。
输出标签:垃圾邮件 / 正常邮件。
算法选择:逻辑回归 / SVM / 神经网络。
这两个案例展示了监督学习在现实生活中的直观应用。
六、总结与展望
本文我们详细介绍了监督学习:
它的基本概念与任务类型(分类与回归)。
常见经典算法(线性回归、逻辑回归、决策树、SVM、神经网络)。
模型评估与优化方法。
典型应用案例。
监督学习是机器学习的基石。掌握它,等于站稳了进入机器学习领域的第一步。
在下一篇文章中,我们将探索 无监督学习,了解如何在没有标签的材料中发现潜在规律,例如聚类与降维办法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号