

完整教程:用 Flink Table API 打造实时交易看板从 Kafka 到 MySQL 再到 Grafana
一、为什么选 Table API?
Table API 是 Flink 提供的统一关系型 API,批流同源、语义一致:对无界流或有界批数据执行同一条查询,都可以得到一致的结果。这意味着你可以在离线(批)模式下开发与测试,并直接切换到在线(流)模式部署生产,非常适合数据分析、ETL、和实时看板类应用。
二、你将构建的实时看板
我们要做的是一个**“按账户统计每小时交易额”**的实时看板。数据来自 Kafka 的 transactions 主题,Flink 实时计算后写入 MySQL 的 spend_report 表,再用 Grafana 做可视化展示。
架构示意
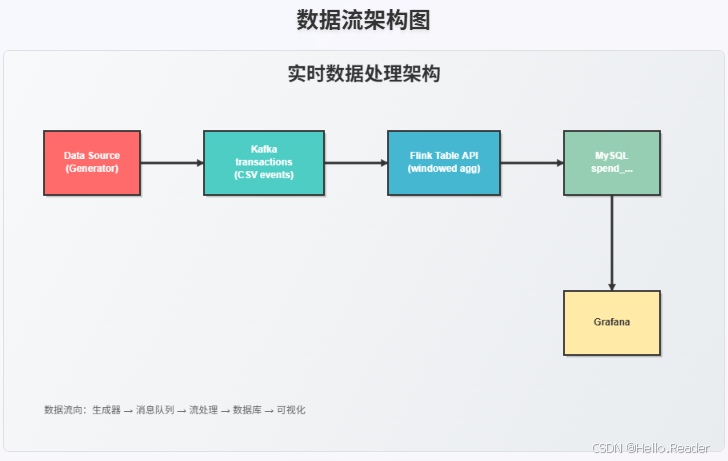
三、环境准备
- Java:11
- Maven
- Docker
示例工程来自 flink-playgrounds 仓库。下载后进入 flink-playground/table-walkthrough 项目,在 IDE 中打开 SpendReport 文件。
四、Flink 作业骨架:表环境与表注册
1)创建 TableEnvironment(流模式)
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);2)注册源表与结果表
源表
transactions:Kafka 主题transactions,CSV 格式,包含:account_id(BIGINT)amount(BIGINT)transaction_time(TIMESTAMP(3))- Watermark:
transaction_time - INTERVAL '5' SECOND(允许 5 秒乱序)
tEnv.executeSql(
"CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")"
);- 汇表
spend_report:JDBC 写入 MySQL,采用主键account_id + log_ts做 upsert。
tEnv.executeSql(
"CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT,\n" +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")"
);Tips
WATERMARK是事件时间处理的关键,它告诉 Flink “当水位推进到 T 时,认为 T 之前的窗口不会再有新数据”。PRIMARY KEY … NOT ENFORCED是 Table/SQL 层的声明,底层由 JDBC sink 执行 upsert 语义。
3)读表并写出
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");五、实现业务逻辑:三种写法
目标:按账户(account_id)统计每小时(log_ts)的消费总额(amount)。
写法 A:直接用内置函数 floor 到小时
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TimeIntervalUnit;
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}要点:把 transaction_time向下取整到小时,再 groupBy 聚合求和。
写法 B:自定义 UDF(如果没有内置 floor)
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
public class MyFloor
extends ScalarFunction {
public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime ts) {
return ts.truncatedTo(ChronoUnit.HOURS);
// 向下取整到小时
}
}集成到查询:
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.call;
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
call(MyFloor.class, $(
"transaction_time")).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}写法 C:使用滚动窗口(推荐)
窗口是处理无界流的“正确姿势”。这里我们用 1 小时滚动窗口(Tumble):
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
import org.apache.flink.table.api.Table;
public static Table report(Table transactions) {
return transactions
.window(
org.apache.flink.table.api.Tumble
.over(lit(1).hour())
.on($("transaction_time"))
.as("log_ts")
)
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts").start().as("log_ts"), // 窗口开始时间作为小时粒度
$("amount").sum().as("amount")
);
}对比:
- A/B 写法适用于“直接做字段变换再聚合”的场景。
- C 写法通过窗口内建算子让运行时可做更多优化(如状态清理),并且对批/流都更自然。
六、批/流一致语义下的单元测试(批模式)
为了快速验证逻辑,我们可在 批模式 下跑测试类 SpendReportTest:
EnvironmentSettings settings = EnvironmentSettings.inBatchMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
// 准备静态输入数据 -> 调用 report(...) -> 校验输出这体现了 Flink 的“一次开发,批流通吃”:批上测试,流上上线。
七、Docker 一键端到端拉起
进入 table-walkthrough 目录:
# 构建镜像
docker compose build
# 后台启动
docker compose up -d1)Flink 控制台
浏览器打开 Flink Web UI,查看任务 DAG、并行度、任务状态、反压等。
2)MySQL 验证结果
docker compose exec mysql \
mysql -Dsql-demo -usql-demo -pdemo-sql
mysql> use sql-demo;
mysql>
select count(*) from spend_report;
+----------+
| count(*) |
+----------+
| 110 |
+----------+你将看到
spend_report里不断有 upsert 的统计结果进入。
3)Grafana 可视化
打开 Grafana,选择数据源为 MySQL,构建一个简单的图表(如 Bar/Time Series),以 log_ts 为时间轴,sum(amount) 为度量,account_id 为维度进行拆分,即可得到按账户的小时级消费曲线/柱状。
八、关键概念与生产化要点
Watermark(事件时间)
WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND- 意味着允许 5 秒乱序。太小会丢迟到数据,太大会延迟输出;根据业务延迟特性调整。
窗口状态与清理
- 窗口聚合会在 state 中累计,水位线推进后,Flink 可判定窗口完成并进行状态清理,降低内存占用。
主键 Upsert(JDBC Sink)
PRIMARY KEY (account_id, log_ts) NOT ENFORCED:用于生成 upsert 语义,避免重复插入。- 若使用新版 MySQL 驱动,驱动类名可能是
com.mysql.cj.jdbc.Driver(本文示例保持与给定 DDL 一致)。
批/流一致语义
- 同一逻辑在批/流两种模式下保持一致结果,降低联调成本。
扩展格式
- Kafka 源支持 CSV/JSON/Avro/Parquet 等,选择合适格式能提高解码效率与可观测性。
九、常见问题排查(FAQ)
Windows + Docker 数据生成器容器启动失败
报错:standard_init_linux.go:211: exec user process caused "no such file or directory"原因:
docker-entrypoint.sh需要bash。
解决:将脚本首行改为sh,或在环境中提供bash。MySQL 驱动类不匹配
如果连接 MySQL 报驱动相关错误,尝试把'driver'从com.mysql.jdbc.Driver改为com.mysql.cj.jdbc.Driver。看不到数据
- 确认 Kafka
transactions主题有新数据进来(可在容器里kafka-console-consumer验证)。 - 检查 Table DDL 的
format与实际消息格式一致(CSV/JSON)。 - 检查
WATERMARK设置是否过于严格导致窗口迟迟不触发。
- 确认 Kafka
Grafana 图表空白
- 检查 Grafana 中 MySQL 数据源连通;
- 面板查询是否命中
sql-demo.spend_report; - 时间范围是否覆盖到了
log_ts数据(适当扩大时间范围)。
十、完整主类(示例整合)
以“窗口写法 C”为业务实现,便于状态清理与流式优化。
package org.example;
import org.apache.flink.table.api.*;
import static org.apache.flink.table.api.Expressions.*;
public class SpendReportJob
{
public static void main(String[] args) {
// 1) 表环境(流)
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
// 2) 源表:Kafka
tEnv.executeSql(
"CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")"
);
// 3) 汇表:MySQL(upsert)
tEnv.executeSql(
"CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT,\n" +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")"
);
// 4) 读取源表
Table transactions = tEnv.from("transactions");
// 5) 业务:1 小时滚动窗口聚合
Table result =
transactions
.window(
Tumble.over(lit(1).hour())
.on($("transaction_time"))
.as("log_win")
)
.groupBy($("account_id"), $("log_win"))
.select(
$("account_id"),
$("log_win").start().as("log_ts"),
$("amount").sum().as("amount")
);
// 6) 写出至 MySQL
result.executeInsert("spend_report");
}
}十一、实用延伸
- 改用 JSON 数据:将 Kafka 源
format改为json,并根据字段嵌套结构调整 DDL。 - Exactly-once:在生产环境启用 checkpoint 与合理的 sink 语义(例如 TwoPhaseCommit sink),确保端到端一致性。
- 维度扩展:可增加
merchant_id、region等维度,Grafana 中做多维度对比与过滤。 - 告警:在 Grafana 或下游系统中设置阈值告警(例如某账户小时消费异常激增)。
十二、总结
本文从 Table API 的“批流一致”特点切入,完整走通了 Kafka → Flink → MySQL → Grafana 的实时看板链路。你不仅学会了如何注册源/汇表、如何用内置函数或 UDF 实现按小时汇总,更用窗口方式构建了可优化、可维护的实时聚合作业。借助 Docker 一键拉起与批模式单测,你可以更快、更稳地把实时看板从 Demo 推向生产。
如果你已经跑通了示例,不妨尝试:
1)把窗口从 1 小时改为 5 分钟;
2)增加账户白名单过滤;
3)切换 CSV → JSON;
4)在 Grafana 做按账户的对比趋势与异常突增告警。
祝你玩转 Flink 的实时计算世界!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号